
TRIM
Introduction
We introduce new approach, Token Reduction using CLIP Metric (TRIM), aimed at improving the efficiency of MLLMs without sacrificing their performance. Inspired by human attention patterns in Visual Question Answering (VQA) tasks, TRIM presents a fresh perspective on the selection and reduction of image tokens. The TRIM method has been extensively tested across 12 datasets, and the results demonstrate a significant reduction in computational overhead while maintaining a consistent level of performance. This research marks a critical stride in efficient MLLM development, promoting greater accessibility and sustainability of high-performing models.
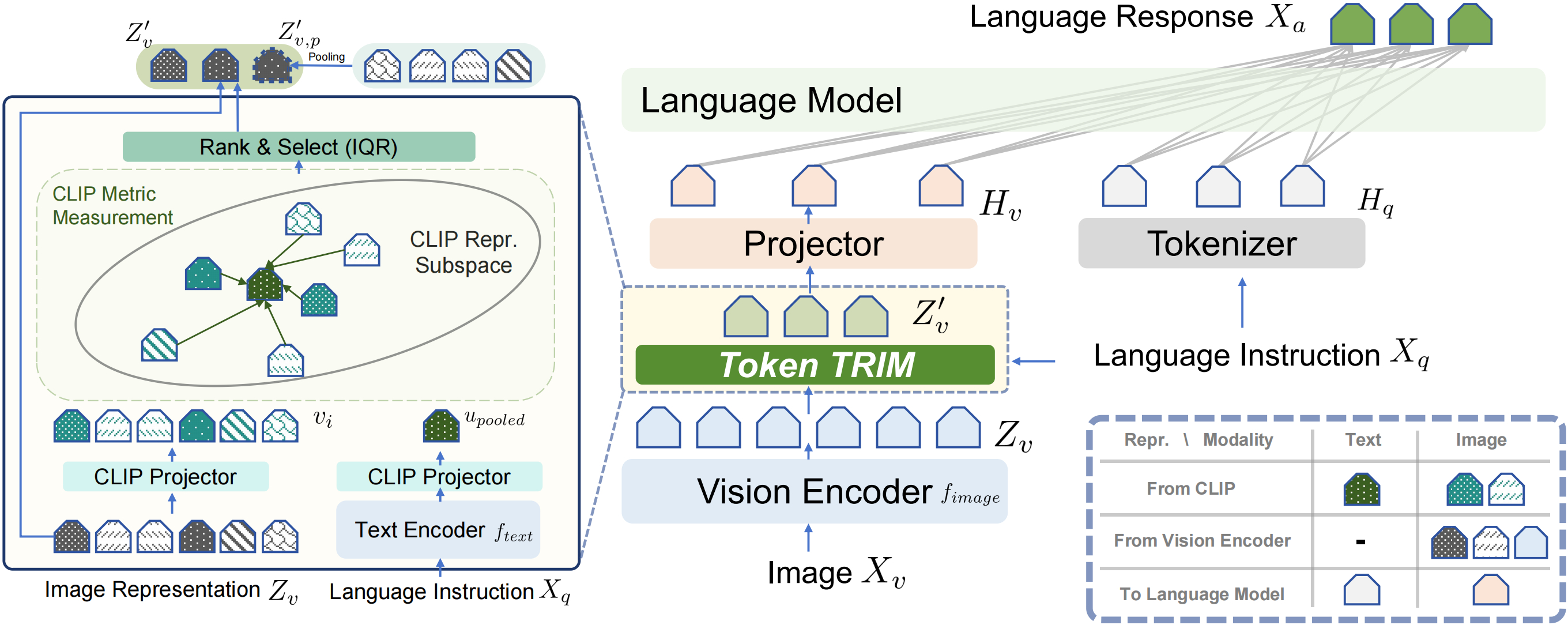
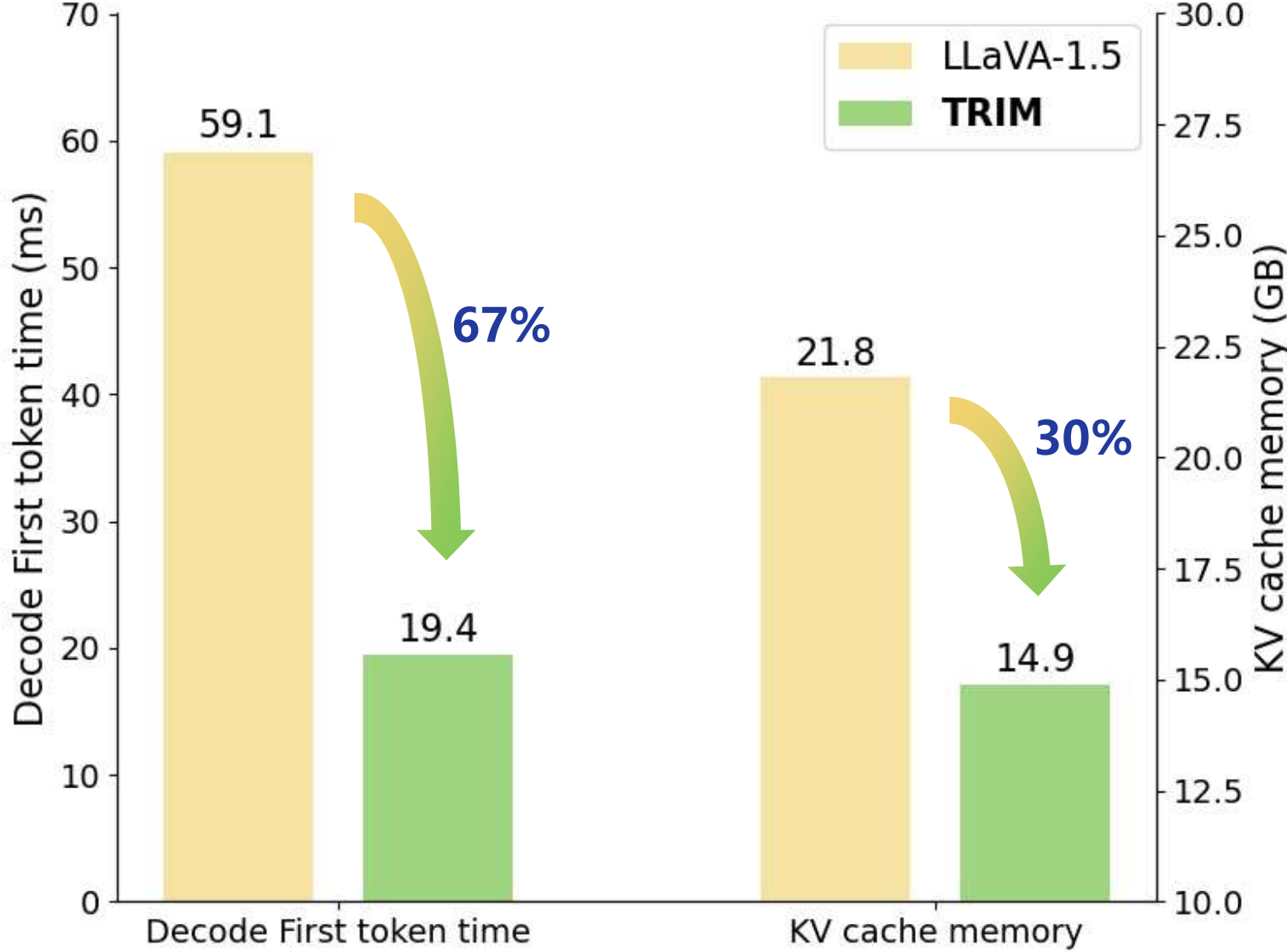
TRIM significantly streamlines the computational process, reducing the number of image tokens by approximately 79%, processing time by 67%, and memory usage by 30% relative to the baseline (LLaVA-1.5-7B).
How to use?
Please refer to Code for TRIM.
Links
- Repository: TRIM GitHub
- Paper: Arxiv
- Point of Contact: Dingjie Song
Citation
If you find this project useful in your research, please consider citing:
@article{song2024less,
title={Less is More: A Simple yet Effective Token Reduction Method for Efficient Multi-modal LLMs},
author={Song, Dingjie and Wang, Wenjun and Chen, Shunian and Wang, Xidong and Guan, Michael and Wang, Benyou},
journal={arXiv preprint arXiv:2409.10994},
year={2024}
}
- Downloads last month
- 25
Model tree for FreedomIntelligence/llava-v1.5-7b-TRIM
Base model
liuhaotian/llava-v1.5-7b