
EMOVA-Models
Collection
A collection of EMOVA models (https://emova-ollm.github.io/)
•
11 items
•
Updated
•
2
![]()
🤗 EMOVA-Models | 🤗 EMOVA-Datasets | 🤗 EMOVA-Demo
📄 Paper | 🌐 Project-Page | 💻 Github | 💻 EMOVA-Speech-Tokenizer-Github
EMOVA (EMotionally Omni-present Voice Assistant) is a novel end-to-end omni-modal LLM that can see, hear and speak without relying on external models. Given the omni-modal (i.e., textual, visual and speech) inputs, EMOVA can generate both textual and speech responses with vivid emotional controls by utilizing the speech decoder together with a style encoder. EMOVA possesses general omni-modal understanding and generation capabilities, featuring its superiority in advanced vision-language understanding, emotional spoken dialogue, and spoken dialogue with structural data understanding. We summarize its key advantages as:
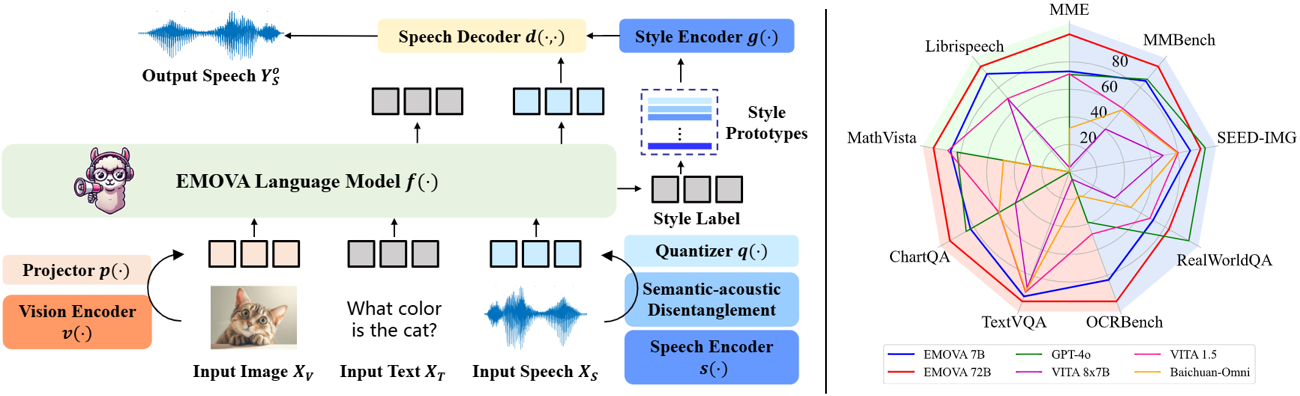
| Benchmarks | EMOVA-3B | EMOVA-7B | EMOVA-72B | GPT-4o | VITA 8x7B | VITA 1.5 | Baichuan-Omni |
|---|---|---|---|---|---|---|---|
| MME | 2175 | 2317 | 2402 | 2310 | 2097 | 2311 | 2187 |
| MMBench | 79.2 | 83.0 | 86.4 | 83.4 | 71.8 | 76.6 | 76.2 |
| SEED-Image | 74.9 | 75.5 | 76.6 | 77.1 | 72.6 | 74.2 | 74.1 |
| MM-Vet | 57.3 | 59.4 | 64.8 | - | 41.6 | 51.1 | 65.4 |
| RealWorldQA | 62.6 | 67.5 | 71.0 | 75.4 | 59.0 | 66.8 | 62.6 |
| TextVQA | 77.2 | 78.0 | 81.4 | - | 71.8 | 74.9 | 74.3 |
| ChartQA | 81.5 | 84.9 | 88.7 | 85.7 | 76.6 | 79.6 | 79.6 |
| DocVQA | 93.5 | 94.2 | 95.9 | 92.8 | - | - | - |
| InfoVQA | 71.2 | 75.1 | 83.2 | - | - | - | - |
| OCRBench | 803 | 814 | 843 | 736 | 678 | 752 | 700 |
| ScienceQA-Img | 92.7 | 96.4 | 98.2 | - | - | - | - |
| AI2D | 78.6 | 81.7 | 85.8 | 84.6 | 73.1 | 79.3 | - |
| MathVista | 62.6 | 65.5 | 69.9 | 63.8 | 44.9 | 66.2 | 51.9 |
| Mathverse | 31.4 | 40.9 | 50.0 | - | - | - | - |
| Librispeech (WER↓) | 5.4 | 4.1 | 2.9 | - | 3.4 | 8.1 | - |
This repo contains the EMOVA-Qwen2.5-3B checkpoint organized in the original format of our EMOVA codebase, and thus, it should be utilized together with EMOVA codebase. Its paired config file is provided here. Check here to launch a web demo using this checkpoint.
@article{chen2024emova,
title={Emova: Empowering language models to see, hear and speak with vivid emotions},
author={Chen, Kai and Gou, Yunhao and Huang, Runhui and Liu, Zhili and Tan, Daxin and Xu, Jing and Wang, Chunwei and Zhu, Yi and Zeng, Yihan and Yang, Kuo and others},
journal={arXiv preprint arXiv:2409.18042},
year={2024}
}
Base model
Qwen/Qwen2.5-3B