
Medical-Related
Collection
Models of all types of tasks that relate to medical matters.
•
18 items
•
Updated
This model is a fine-tuned version of bert-large-cased.
It achieves the following results on the evaluation set:
For more information on how it was created, check out the following link: https://github.com/DunnBC22/NLP_Projects/blob/main/Token%20Classification/Monolingual/EMBO-SourceData%20with%20LoRA/NER%20Project%20Using%20EMBO-SourceData%20with%20LoRA.ipynb
This model is intended to demonstrate my ability to solve a complex problem using technology.
Dataset Source: https://huggingface.co/datasets/EMBO/BLURB
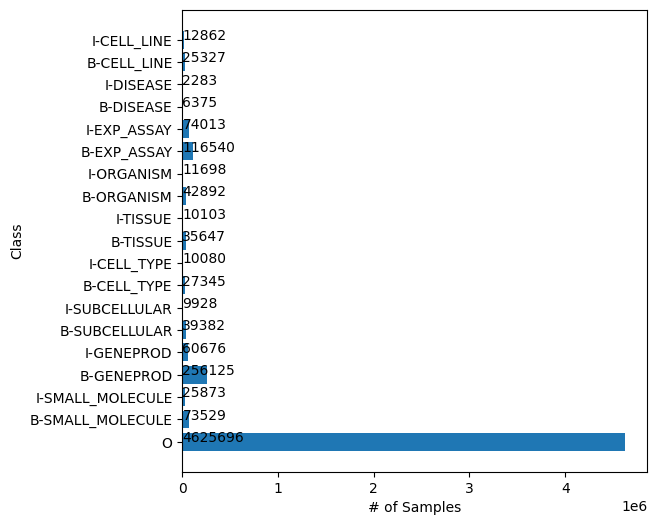
Token Distribution
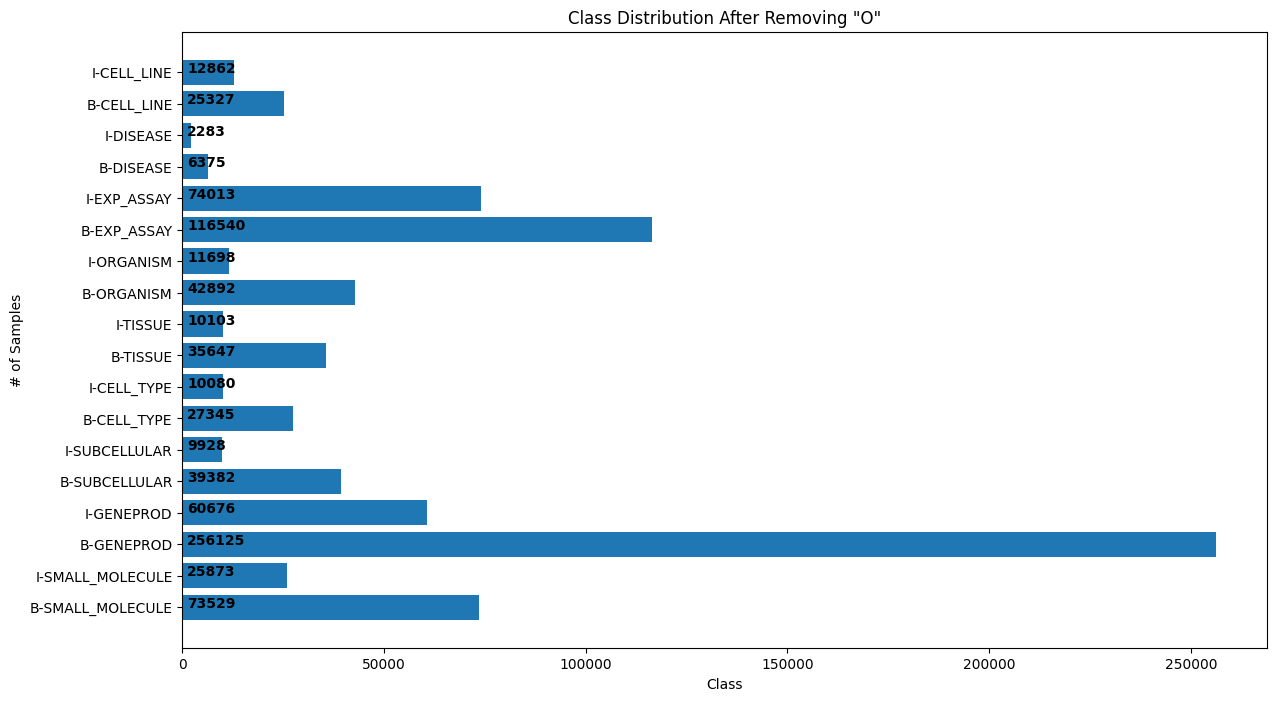
Token Distribution After Removing 'O' Tokens
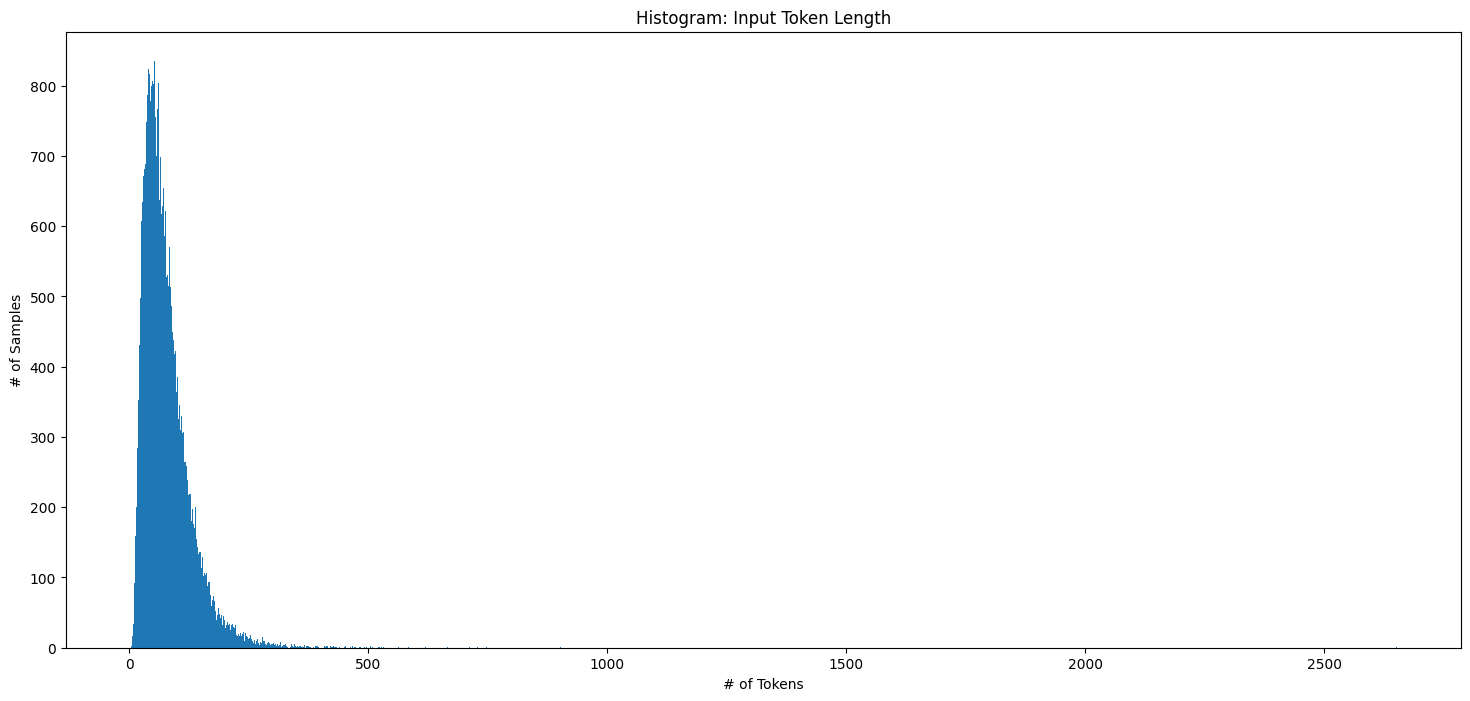
Histogram of Tokenized Input Lengths
The following hyperparameters were used during training:
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|---|---|---|---|---|---|---|---|
| 0.1552 | 1.0 | 3454 | 0.1499 | 0.7569 | 0.7968 | 0.7763 | 0.9516 |
| 0.1179 | 2.0 | 6908 | 0.1328 | 0.7910 | 0.8120 | 0.8013 | 0.9564 |
| 0.0998 | 3.0 | 10362 | 0.1282 | 0.7999 | 0.8278 | 0.8136 | 0.9584 |