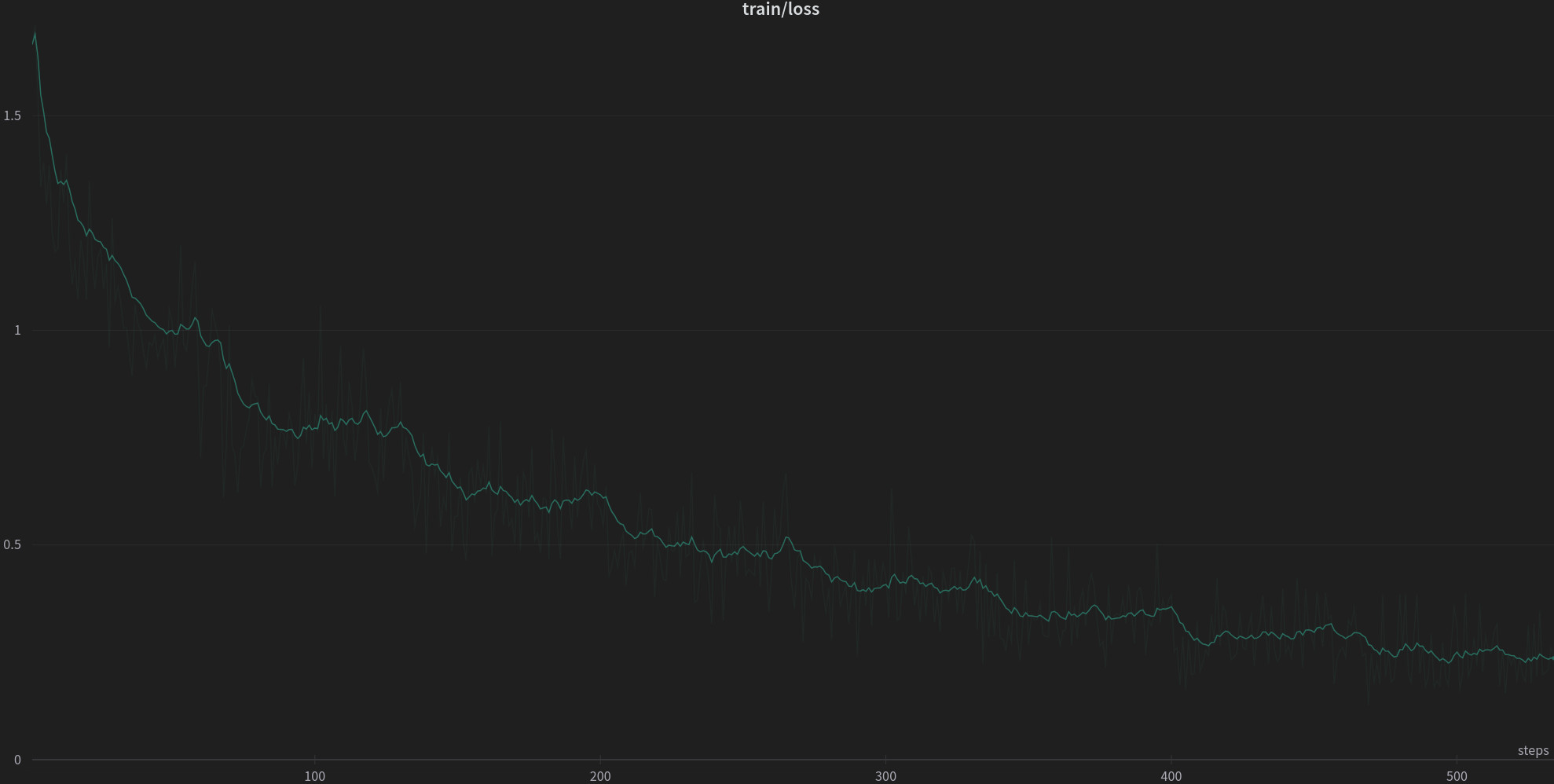
This repo contains a qlora adapter for Llama-2-7b, trained on 1B tokens (available here) and subsequently fine-tuned on a private instructions dataset, exclusively in Polish.
The fine-tuning took 1 hour on a single RTX 4090 with the following hyperparameters:
- context length: 2048
- batch_size: 16
- learning_rate: 0.0001
- lora_r: 64
- lora_alpha: 16
- lora_modules: all
- lora_dropout: 0.0
- weight_decay: 0.1
- max_grad_norm: 0.3
- double_quant, nf4
- optimizer: paged_adamw_32bit (beta2: 0.999)
This adapter allows the model to speak Polish more accurately than vanilla Llama-2-7b.