
Meta-Llama-3-8B-Instruct-64k-PoSE
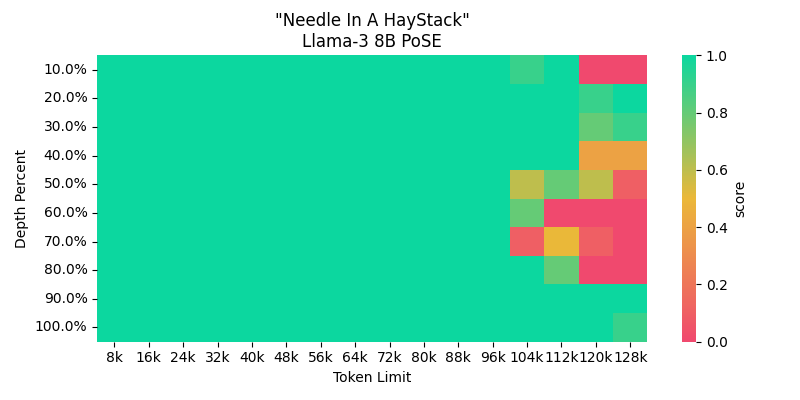
This is a custom version of the Meta Llama 3 8B instruction-tuned language model with an extended context length of up to 64,000 tokens. It was created by merging the meta-llama/Meta-Llama-3-8B-Instruct model with a LoRA adapter finetuned using PoSE by Wing Lian to extend Llama's context length from 8k to 64k @ rope_theta: 500000.0. They used PoSE with continued pretraining on 300M tokens from the RedPajama V1 dataset using data between 6k-8k tokens.
They have further set rope_theta to 2M after continued pre-training to potentially further extend the context past 64k.
This was trained on a subset of the RedPajama v1 dataset with text between 6k-8k context. They trained a rank stabilized LoRA of rank 256. WandB
Model Details
- Base Model: Meta Llama 3 8B instruction-tuned model
- Context Length: Up to 64,000 tokens (increased from original 8,192 token limit)
- Adapter Training: PoSE adapter finetuned on 300M tokens from the RedPajama V1 dataset with 6k-8k token sequences.
- Adapter Rank: 256 rank stabilized LoRA adapter
This extended context model allows for much longer form inputs and generation compared to the original base model. It maintains the strong instruction-following and safety capabilities of Llama 3 while greatly increasing the applicable use cases. See the Original Repo by Wing Lian for more details on the adapter training process.
Usage
This model can be used just like the base Llama 3 8B model, but with the increased context length enabling much longer prompts and outputs. See the example usage with the Transformers library:
import transformers
import torch
model_id = "Azma-AI/Meta-Llama-3-8B-Instruct-64k-PoSE"
pipeline = transformers.pipeline(
"text-generation", model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto"
)
long_prompt = "..." # Your prompt up to 64k tokens
output = pipeline(long_prompt)
Citation
If you use this model, please cite the original Meta Llama 3 model card and the PoSE adapter paper:
@article{llama3modelcard,
title={Llama 3 Model Card},
author={AI@Meta},
year={2024},
url = {https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md}
}
Acknowledgments
- Downloads last month
- 11