

LaMini-Flan-T5-248M
![]()
This model is one of our LaMini-LM model series in paper "LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions". This model is a fine-tuned version of google/flan-t5-base on LaMini-instruction dataset that contains 2.58M samples for instruction fine-tuning. For more information about our dataset, please refer to our project repository.
You can view other models of LaMini-LM series as follows. Models with ✩ are those with the best overall performance given their size/architecture, hence we recommend using them. More details can be seen in our paper.
| Base model | LaMini-LM series (#parameters) | |||
|---|---|---|---|---|
| T5 | LaMini-T5-61M | LaMini-T5-223M | LaMini-T5-738M | |
| Flan-T5 | LaMini-Flan-T5-77M✩ | LaMini-Flan-T5-248M✩ | LaMini-Flan-T5-783M✩ | |
| Cerebras-GPT | LaMini-Cerebras-111M | LaMini-Cerebras-256M | LaMini-Cerebras-590M | LaMini-Cerebras-1.3B |
| GPT-2 | LaMini-GPT-124M✩ | LaMini-GPT-774M✩ | LaMini-GPT-1.5B✩ | |
| GPT-Neo | LaMini-Neo-125M | LaMini-Neo-1.3B | ||
| GPT-J | coming soon | |||
| LLaMA | coming soon | |||
Use
Intended use
We recommend using the model to response to human instructions written in natural language.
We now show you how to load and use our model using HuggingFace pipeline().
# pip install -q transformers
from transformers import pipeline
checkpoint = "{model_name}"
model = pipeline('text2text-generation', model = checkpoint)
input_prompt = 'Please let me know your thoughts on the given place and why you think it deserves to be visited: \n"Barcelona, Spain"'
generated_text = model(input_prompt, max_length=512, do_sample=True)[0]['generated_text']
print("Response", generated_text)
Training Procedure
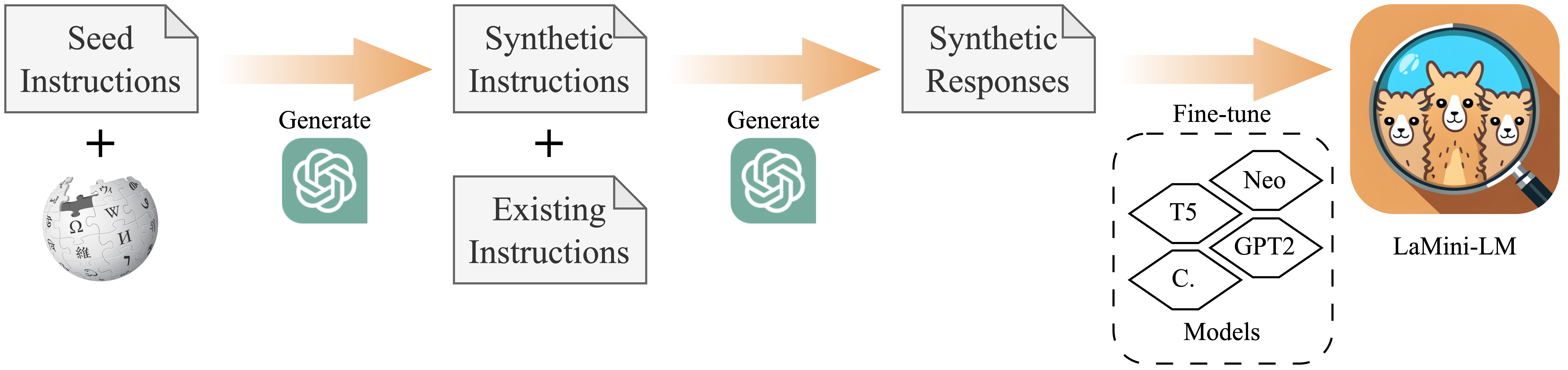
We initialize with google/flan-t5-base and fine-tune it on our LaMini-instruction dataset. Its total number of parameters is 248M.
Training Hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 512
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
Evaluation
We conducted two sets of evaluations: automatic evaluation on downstream NLP tasks and human evaluation on user-oriented instructions. For more detail, please refer to our paper.
Limitations
More information needed
Citation
@article{lamini-lm,
author = {Minghao Wu and
Abdul Waheed and
Chiyu Zhang and
Muhammad Abdul-Mageed and
Alham Fikri Aji
},
title = {LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions},
journal = {CoRR},
volume = {abs/2304.14402},
year = {2023},
url = {https://arxiv.org/abs/2304.14402},
eprinttype = {arXiv},
eprint = {2304.14402}
}
- Downloads last month
- 3,417