
Mugs: A Multi-Granular Self-Supervised Learning Framework
This is a PyTorch implementation of Mugs proposed by our paper "Mugs: A Multi-Granular Self-Supervised Learning Framework". ![]()
![]()
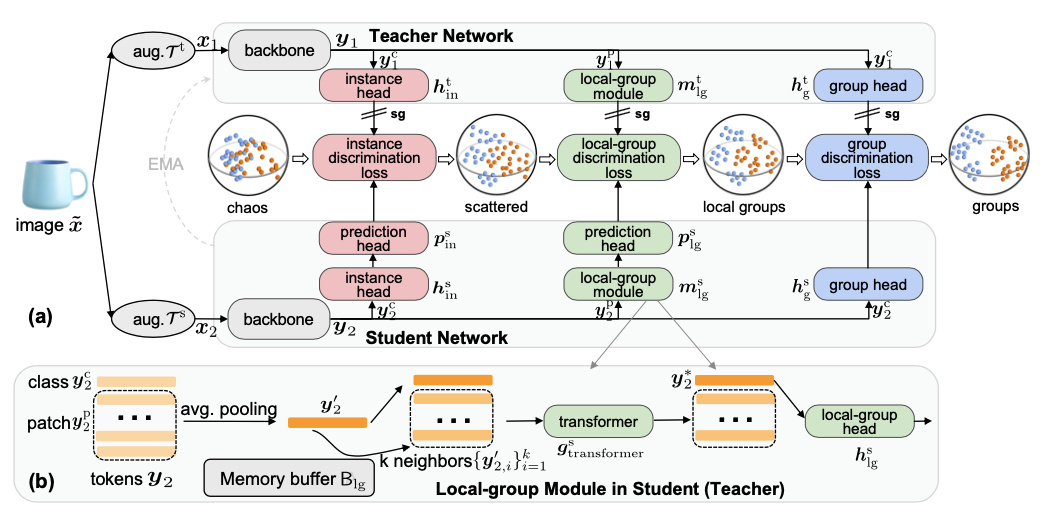
Fig 1. Overall framework of Mugs. In (a), for each image, two random crops of one image are fed into backbones of student and teacher. Three granular supervisions: 1) instance discrimination supervision, 2) local-group discrimination supervision, and 3) group discrimination supervision, are adopted to learn multi-granular representation. In (b), local-group modules in student/teacher averages all patch tokens, and finds top-k neighbors from memory buffer to aggregate them with the average for obtaining a local-group feature.
Pretrained models on ImageNet-1K
You can choose to download only the weights of the pretrained backbone used for downstream tasks, or the full checkpoint which contains backbone and projection head weights for both student and teacher networks.
Table 1. KNN and linear probing performance with their corresponding hyper-parameters, logs and model weights.
| arch | params | pretraining epochs | k-nn | linear | download | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| ViT-S/16 | 21M | 100 | 72.3% | 76.4% | backbone only | full ckpt | args | logs | eval logs | |
| ViT-S/16 | 21M | 300 | 74.8% | 78.2% | backbone only | full ckpt | args | logs | eval logs | |
| ViT-S/16 | 21M | 800 | 75.6% | 78.9% | backbone only | full ckpt | args | logs | eval logs | |
| ViT-B/16 | 85M | 400 | 78.0% | 80.6% | backbone only | full ckpt | args | logs | eval logs | |
| ViT-L/16 | 307M | 250 | 80.3% | 82.1% | backbone only | full ckpt | args | logs | eval logs | |
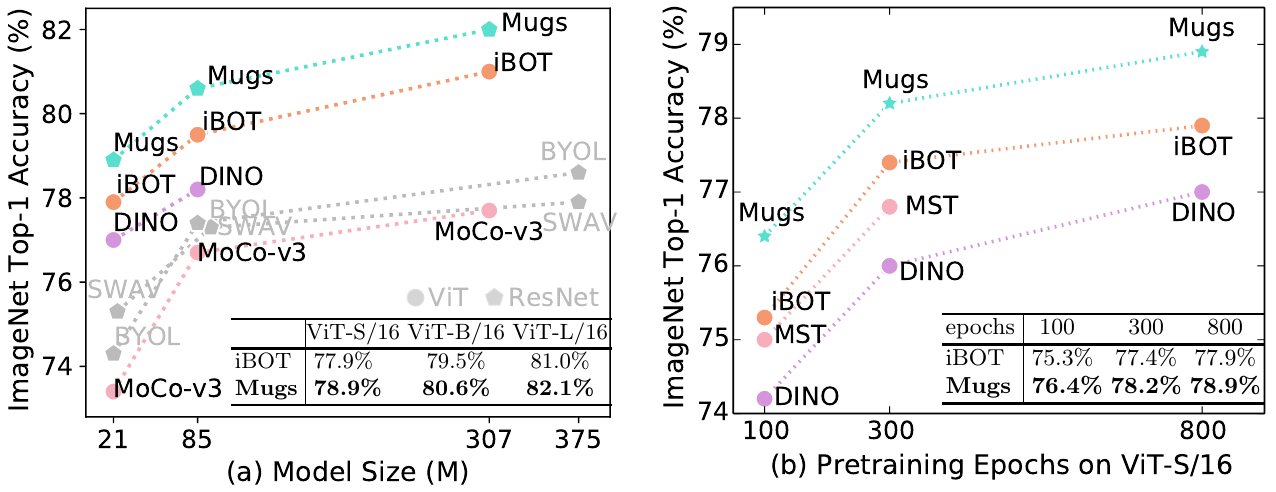
Fig 2. Comparison of linear probing accuracy on ImageNet-1K.
Pretraining Settings
Environment
For reproducing, please install PyTorch and download the ImageNet dataset.
This codebase has been developed with python version 3.8, PyTorch version 1.7.1, CUDA 11.0 and torchvision 0.8.2. For the full
environment, please refer to our Dockerfile file.
ViT pretraining :beer:
To pretraining each model, please find the exact hyper-parameter settings at the args column of Table 1. For training log and linear probing log, please refer to the
log and eval logs column of Table 1.
ViT-Small pretraining:
To run ViT-small for 100 epochs, we use two nodes of total 8 A100 GPUs (total 512 minibatch size) by using following command:
python -m torch.distributed.launch --nproc_per_node=8 main.py --data_path DATASET_ROOT --output_dir OUTPUT_ROOT --arch vit_small
--group_teacher_temp 0.04 --group_warmup_teacher_temp_epochs 0 --weight_decay_end 0.2 --norm_last_layer false --epochs 100
To run ViT-small for 300 epochs, we use two nodes of total 16 A100 GPUs (total 1024 minibatch size) by using following command:
python -m torch.distributed.launch --nproc_per_node=16 main.py --data_path DATASET_ROOT --output_dir OUTPUT_ROOT --arch vit_small
--group_teacher_temp 0.07 --group_warmup_teacher_temp_epochs 30 --weight_decay_end 0.1 --norm_last_layer false --epochs 300
To run ViT-small for 800 epochs, we use two nodes of total 16 A100 GPUs (total 1024 minibatch size) by using following command:
python -m torch.distributed.launch --nproc_per_node=16 main.py --data_path DATASET_ROOT --output_dir OUTPUT_ROOT --arch vit_small
--group_teacher_temp 0.07 --group_warmup_teacher_temp_epochs 30 --weight_decay_end 0.1 --norm_last_layer false --epochs 800
ViT-Base pretraining:
To run ViT-base for 400 epochs, we use two nodes of total 24 A100 GPUs (total 1024 minibatch size) by using following command:
python -m torch.distributed.launch --nproc_per_node=24 main.py --data_path DATASET_ROOT --output_dir OUTPUT_ROOT --arch vit_base
--group_teacher_temp 0.07 --group_warmup_teacher_temp_epochs 50 --min_lr 2e-06 --weight_decay_end 0.1 --freeze_last_layer 3 --norm_last_layer
false --epochs 400
ViT-Large pretraining:
To run ViT-large for 250 epochs, we use two nodes of total 40 A100 GPUs (total 640 minibatch size) by using following command:
python -m torch.distributed.launch --nproc_per_node=40 main.py --data_path DATASET_ROOT --output_dir OUTPUT_ROOT --arch vit_large
--lr 0.0015 --min_lr 1.5e-4 --group_teacher_temp 0.07 --group_warmup_teacher_temp_epochs 50 --weight_decay 0.025
--weight_decay_end 0.08 --norm_last_layer true --drop_path_rate 0.3 --freeze_last_layer 3 --epochs 250
Evaluation
We are cleaning up the evalutation code and will release them when they are ready.
Self-attention visualization
Here we provide the self-attention map of the [CLS] token on the heads of the last layer

Fig 3. Self-attention from a ViT-Base/16 trained with Mugs.
T-SNE visualization
Here we provide the T-SNE visualization of the learned feature by ViT-B/16. We show the fish classes in ImageNet-1K, i.e., the first six classes, including tench, goldfish, white shark, tiger shark, hammerhead, electric ray. See more examples in Appendix.

Fig 4. T-SNE visualization of the learned feature by ViT-B/16.
License
This repository is released under the Apache 2.0 license as found in the LICENSE file.
Citation
If you find this repository useful, please consider giving a star :star: and citation :beer::
@inproceedings{mugs2022SSL,
title={Mugs: A Multi-Granular Self-Supervised Learning Framework},
author={Pan Zhou and Yichen Zhou and Chenyang Si and Weihao Yu and Teck Khim Ng and Shuicheng Yan},
booktitle={arXiv preprint arXiv:2203.14415},
year={2022}
}