
Model Description
These are model weights originally provided by the authors of the paper T2M-GPT: Generating Human Motion from Textual Descriptions with Discrete Representations.
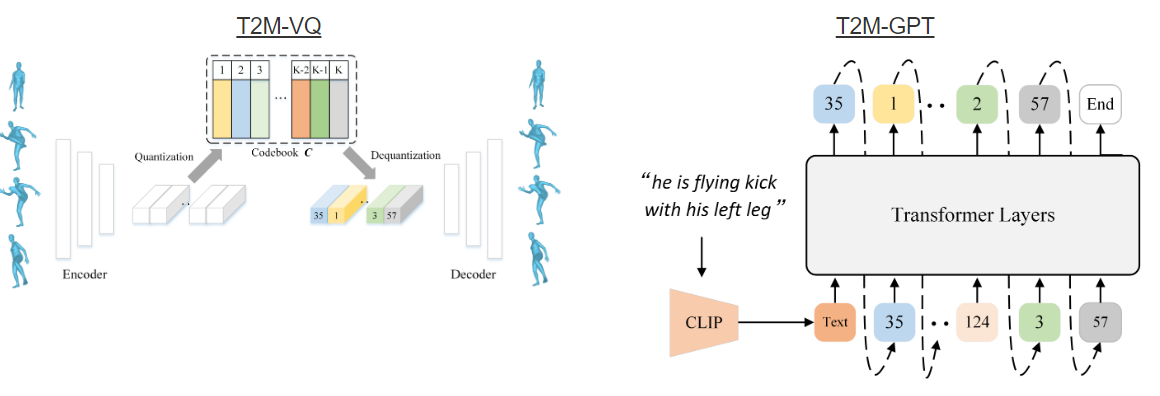
Conditional generative framework based on Vector QuantisedVariational AutoEncoder (VQ-VAE) and Generative Pretrained Transformer (GPT) for human motion generation from textural descriptions.
A simple CNN-based VQ-VAE with commonly used training recipes (EMA and Code Reset) allows us to obtain high-quality discrete representations
The official code of this paper in here
Example


Datasets
HumanML3D and KIT-ML
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support
HF Inference deployability: The model has no library tag.