
VolumeDiffusion
Overview
This is the official repo of the paper VolumeDiffusion: Flexible Text-to-3D Generation with Efficient Volumetric Encoder.
TL;DR
VolumeDiffusion is a fast and scalable text-to-3D generation method that gives you a 3D object within seconds/minutes.
Result
Generations 1 (Figure 5 in paper)


Generations 2 (Figure 9 in paper)


Generations 3 (Figure 10 in paper)
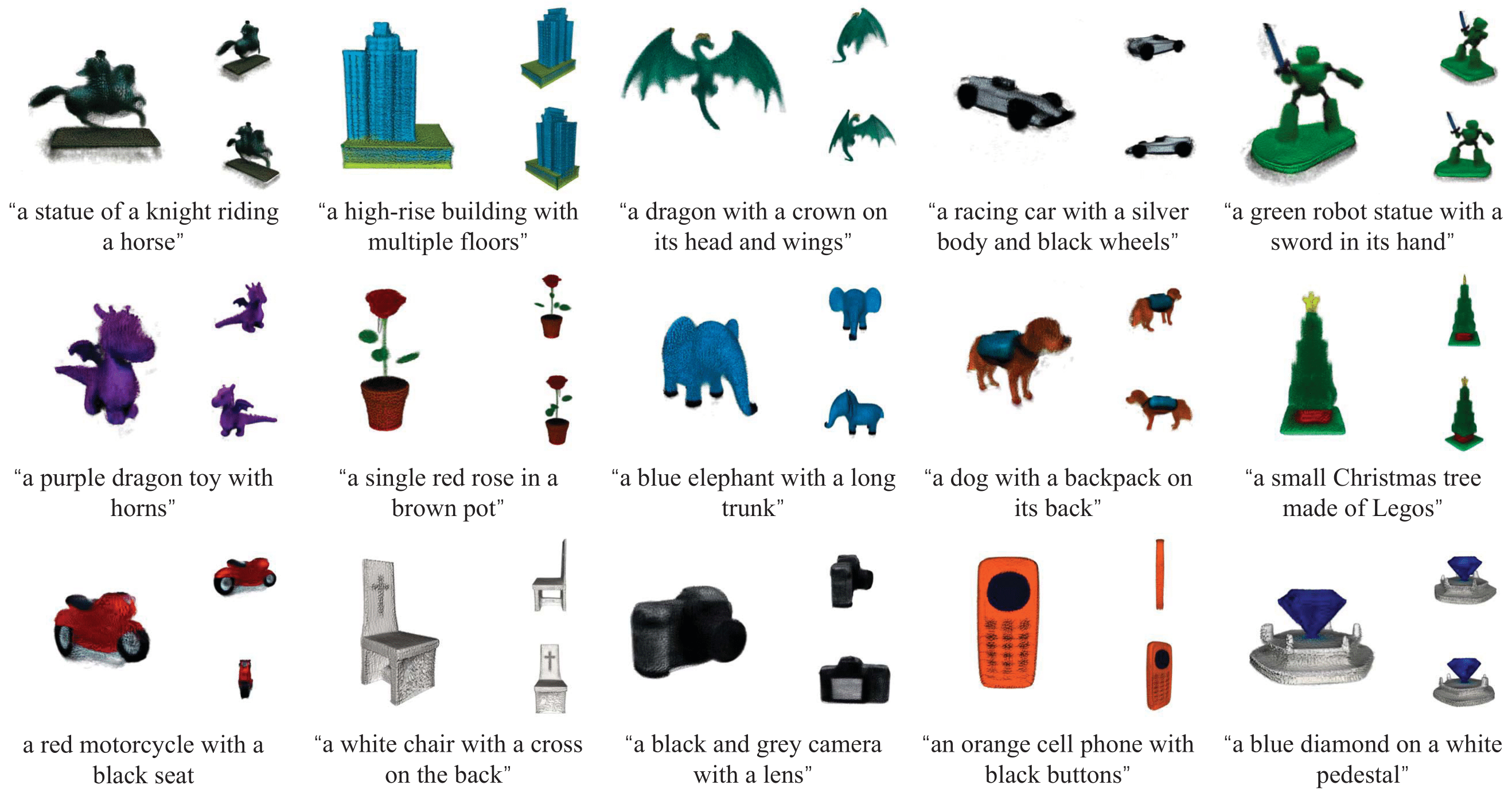

Diversity (Figure 11 in paper)

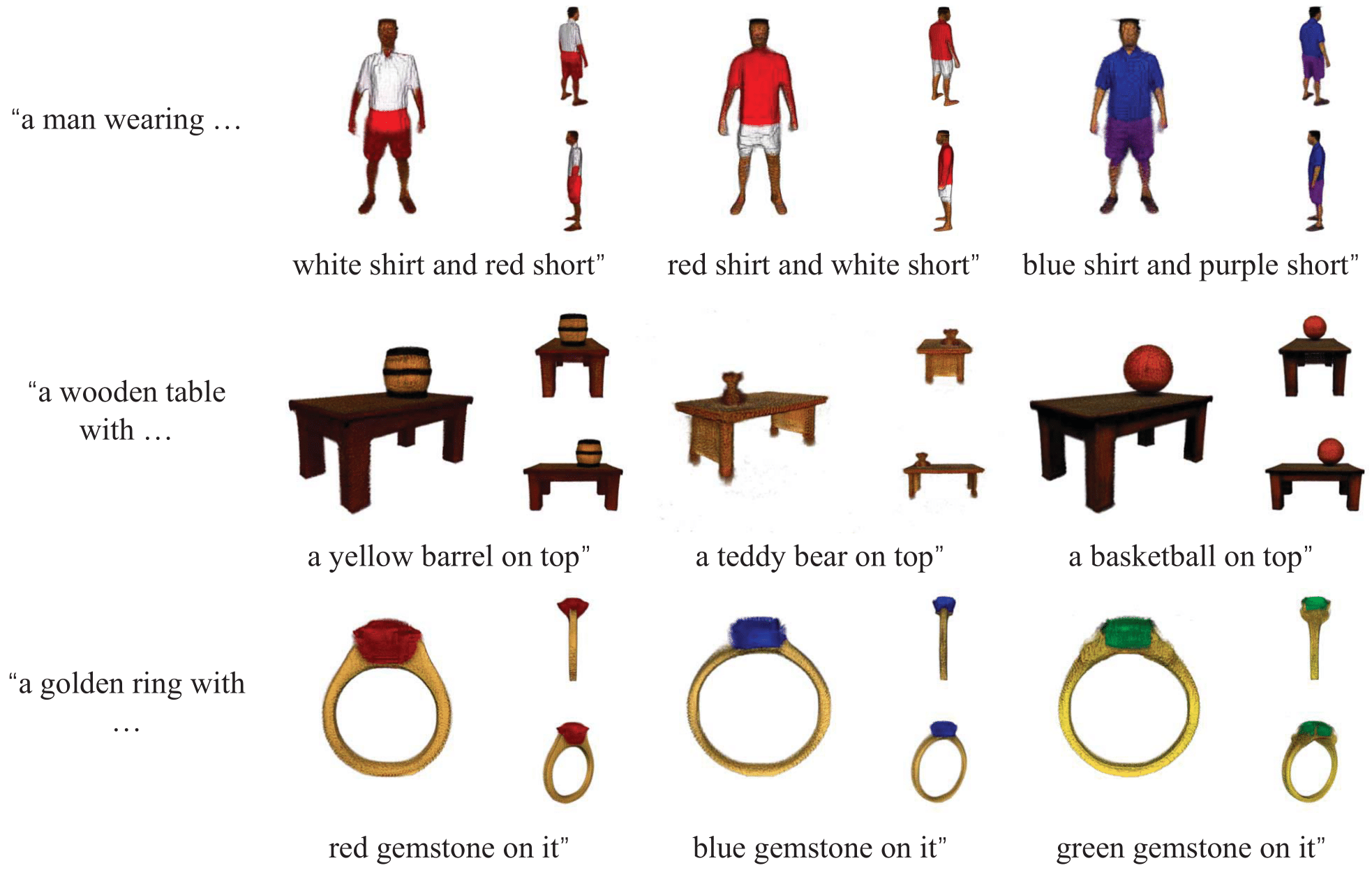
Flexibility (Figure 12 in paper)
Method
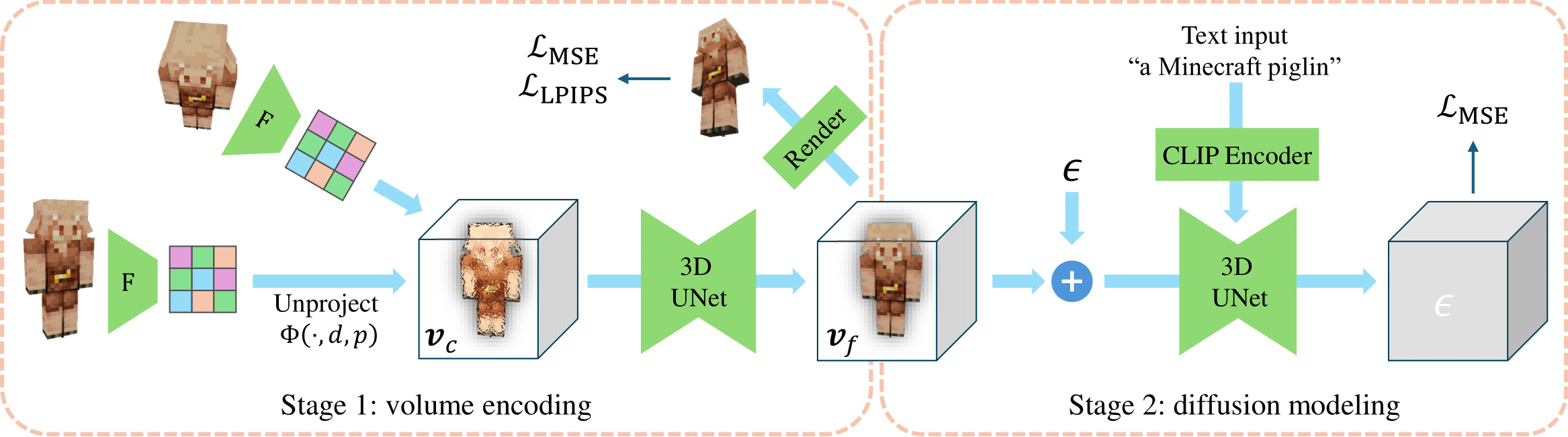
Framework of VolumeDiffusion. It comprises the volume encoding stage and the diffusion modeling stage.
The encoder unprojects multi-view images into a feature volume and do refinements.
The diffusion model learns to predict ground-truths given noised volumes and text conditions.
Citation
@misc{tang2023volumediffusion,
title={VolumeDiffusion: Flexible Text-to-3D Generation with Efficient Volumetric Encoder},
author={Zhicong Tang and Shuyang Gu and Chunyu Wang and Ting Zhang and Jianmin Bao and Dong Chen and Baining Guo},
year={2023},
eprint={2312.11459},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Installation
Run sh install.sh and start enjoying your generation!
We recommend and have tested the code with the docker image pytorch/pytorch:2.1.0-cuda12.1-cudnn8-devel.
Inference
Download the Volume Encoder and Diffusion Model checkpoints and put them right here.
We use DeepFloyd/IF-I-XL-v1.0 for refinement. Ensure you have the access and login with huggingface-cli login --token your_huggingface_token.
Then you can generate objects with
python inference.py --prompt "a yellow hat with a bunny ear on top" --image_channel 4
Also, you can use different prompts for diffusion generation and refinement. This is useful when generating complicated object with multiple concepts and attributes:
python inference.py --prompt "a teapot with a spout and handle" --prompt_refine "a blue teapot with a spout and handle" --image_channel 4
Training
You can train with your custom dataset. We also provide assets/example_data.zip as an example of data format.
To train a volume encoder:
python train_encoder.py path/to/object_list path/to/save --data_root path/to/dataset --test_list path/to/test_object_list
To train a diffusion model:
python train_diffusion.py path/to/object_list path/to/save --data_root path/to/dataset --test_list path/to/test_object_list --encoder_ckpt path/to/trained_volume_encoder.pth --encoder_mean pre_calculated_mean --encoder_std pre_calculated_std
We recommend pre-calculating the mean and std of the outputs of the trained volume encoder on the dataset (or part of the dataset). This encourages the inputs close to the standard normal distribution and benefits the training of the diffusion model. Or you can directly set mean=0 and std=20.
Acknowledgments
This code borrows heavily from stable-dreamfusion.
We use threestudio and do two minor modifications for the refinement stage.
We use DeepFloyd/IF-I-XL-v1.0 model as supervision of the refinement stage.
We use dpm-solver as the solver of diffusion model inference.
The codes of diffusion and UNet model are borrowed from glide-text2im.
The codes of EMA are borrowed from pytorch_ema.
- Downloads last month
- 0