|
--- |
|
pipeline_tag: text-generation |
|
tags: |
|
- text-generation-inference |
|
- backpack |
|
- backpackmodel |
|
library_name: transformers |
|
license: apache-2.0 |
|
datasets: |
|
- openwebtext |
|
language: |
|
- en |
|
--- |
|
|
|
|
|
# Model Card for Backpack-GPT2 |
|
|
|
<!-- Provide a quick summary of what the model is/does. [Optional] --> |
|
The Backpack-GPT2 language model is an instance of the [Backpack architecture](https://arxiv.org/abs/2305.16765), intended to combine strong modeling performance with an interface for interpretability and control. |
|
Most details about this model and its training should be accessed in the paper, [Backpack Language Models](https://arxiv.org/abs/2305.16765). |
|
|
|
See also [backpackmodels.science](backpackmodels.science). |
|
|
|
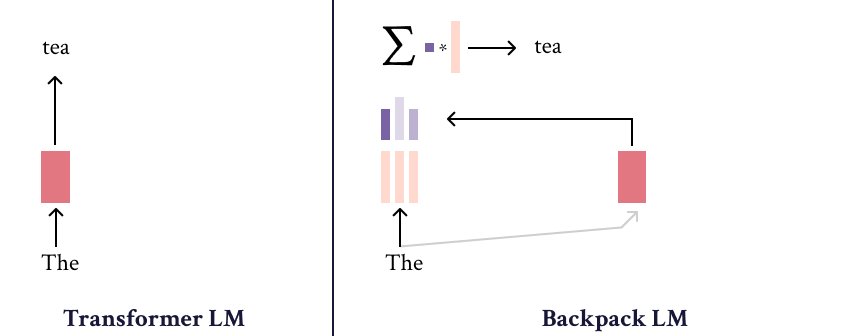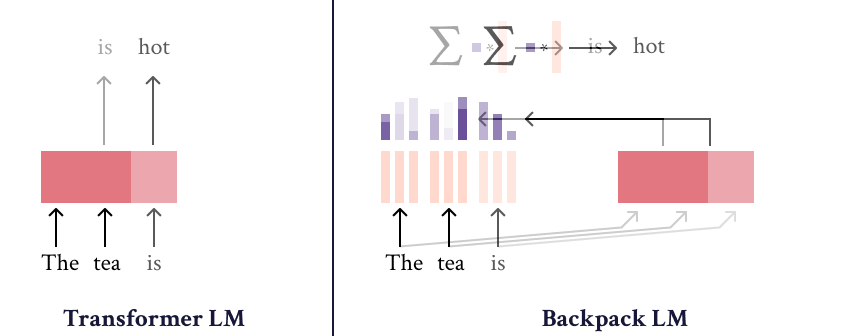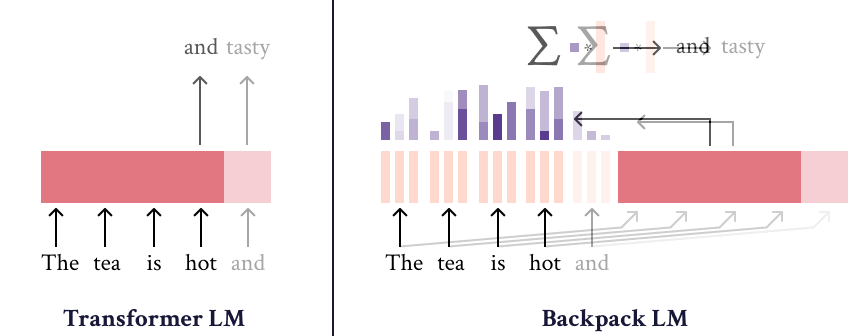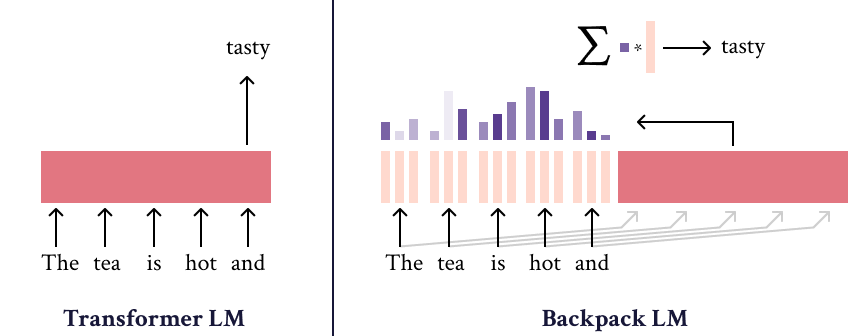 |
|
|
|
## Table of Contents |
|
|
|
- [Model Card for Backpack-GPT2](#model-card-for--model_id-) |
|
- [Table of Contents](#table-of-contents) |
|
- [Model Details](#model-details) |
|
- [Model Description](#model-description) |
|
- [Uses](#uses) |
|
- [Bias, Risks, and Limitations](#bias-risks-and-limitations) |
|
- [Training Details](#training-details) |
|
- [Training Data](#training-data) |
|
- [Training Procedure](#training-procedure) |
|
- [Environmental Impact](#environmental-impact) |
|
- [Technical Specifications [optional]](#technical-specifications-optional) |
|
- [Model Architecture and Objective](#model-architecture-and-objective) |
|
- [Compute Infrastructure](#compute-infrastructure) |
|
- [Hardware](#hardware) |
|
- [Software](#software) |
|
- [Citation](#citation) |
|
- [Model Card Authors [optional]](#model-card-authors-optional) |
|
- [Model Card Contact](#model-card-contact) |
|
- [How to Get Started with the Model](#how-to-get-started-with-the-model) |
|
|
|
|
|
## Model Details |
|
|
|
### Model Description |
|
|
|
<!-- Provide a longer summary of what this model is/does. --> |
|
The Backpack-GPT2 is a [Backpack-based language model](https://arxiv.org/abs/2305.16765), an architecture intended to combine strong modeling performance with an interface for interpretability and control. |
|
|
|
- **Developed by:** John Hewitt, John Thickstun, Christopher D. Manning, Percy Liang |
|
- **Shared by [Optional]:** More information needed |
|
- **Model type:** Language model |
|
- **Language(s) (NLP):** en |
|
- **License:** apache-2.0 |
|
- **Resources for more information:** |
|
- [GitHub Repo](https://github.com/john-hewitt/backpacks-flash-attn) |
|
- [Associated Paper](https://huggingface.co/datasets/openwebtext) |
|
|
|
## Uses |
|
|
|
This model is intended for use in the study and development of increasingly interpretable methods in natural language processing. |
|
It is not directly fit for any production use. |
|
|
|
|
|
## Bias, Risks, and Limitations |
|
|
|
<!-- This section is meant to convey both technical and sociotechnical limitations. --> |
|
|
|
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by the model may include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups. |
|
This model in particular is limited in its capabilities, and with a brand new architecture, less is known about its biases than, e.g., Transformer-based models. |
|
|
|
## How to Get Started with the Model |
|
|
|
```python |
|
import torch |
|
from transformers import AutoConfig, AutoModelForCausalLM |
|
|
|
model_id = "stanfordnlp/backpack-gpt2" |
|
config = AutoConfig.from_pretrained(model_id, trust_remote_code=True) |
|
torch_model = AutoModelForCausalLM.from_pretrained(model_id, config=config, trust_remote_code=True) |
|
torch_model.eval() |
|
|
|
input = torch.randint(0, 50264, (1, 512), dtype=torch.long) |
|
torch_out = torch_model( |
|
input, |
|
position_ids=None, |
|
) |
|
torch_out = torch.nn.functional.softmax(torch_out.logits, dim=-1) |
|
print(torch_out) |
|
``` |
|
|
|
## Training Details |
|
|
|
### Training Data |
|
|
|
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. --> |
|
|
|
This model was trained on the [OpenWebText](https://huggingface.co/datasets/openwebtext) corpus. |
|
|
|
|
|
### Training Procedure |
|
|
|
This model was trained for 100k gradient steps with a batch size of 512k tokens and a linearly decaying learning rate from 6e-4 to zero, with a linear warmup of 5k steps. |
|
|
|
### Environmental Impact |
|
|
|
- **Hardware Type:** 4 A100 GPUs (40G) |
|
- **Hours used:** Roughly 4 days. |
|
- **Cloud Provider:** Stanford compute. |
|
- **Compute Region:** Stanford energy grid. |
|
|
|
### Model Architecture and Objective |
|
|
|
This model was trained to minimize the cross-entropy loss, and is a [Backpack language model](https://arxiv.org/pdf/2305.16765.pdf). |
|
|
|
### Compute Infrastructure |
|
|
|
This model was trained on a slurm cluster. |
|
|
|
### Hardware |
|
|
|
This model was trained on 4 A100s. |
|
|
|
### Software |
|
|
|
This model was trained with [FlashAttention](https://github.com/HazyResearch/flash-attention) and [PyTorch](https://pytorch.org/) |
|
|
|
## Citation |
|
|
|
**BibTeX:** |
|
|
|
``` |
|
@InProceedings{hewitt2023backpack, |
|
author = "Hewitt, John and Thickstun, John and Manning, Christopher D. and Liang, Percy", |
|
title = "Backpack Language Models", |
|
booktitle = "Proceedings of the Association for Computational Linguistics", |
|
year = "2023", |
|
publisher = "Association for Computational Linguistics", |
|
location = "Toronto, Canada", |
|
} |
|
``` |
|
|
|
|
|
## Model Card Authors [optional] |
|
|
|
<!-- This section provides another layer of transparency and accountability. Whose views is this model card representing? How many voices were included in its construction? Etc. --> |
|
|
|
John Hewitt |
|
|
|
## Model Card Contact |
|
|
|
johnhew@cs.stanford.edu |
|
|
|
|
|
|

