


Commit
·
cc87d27
1
Parent(s):
a9697cc
Misc minor suggestions for the model card (#2)
Browse files- Misc minor suggestions for the model card (eaa6b77646f9ee9badb1ec407b8fc139c5d40c0d)
Co-authored-by: Omar Sanseviero <osanseviero@users.noreply.huggingface.co>
README.md
CHANGED
|
@@ -12,10 +12,6 @@ language:
|
|
| 12 |
- en
|
| 13 |
---
|
| 14 |
|
| 15 |
-
---
|
| 16 |
-
|
| 17 |
-
---
|
| 18 |
-
|
| 19 |
|
| 20 |
# Model Card for Backpack-GPT2
|
| 21 |
|
|
@@ -27,7 +23,7 @@ See also [backpackmodels.science](backpackmodels.science).
|
|
| 27 |
|
| 28 |
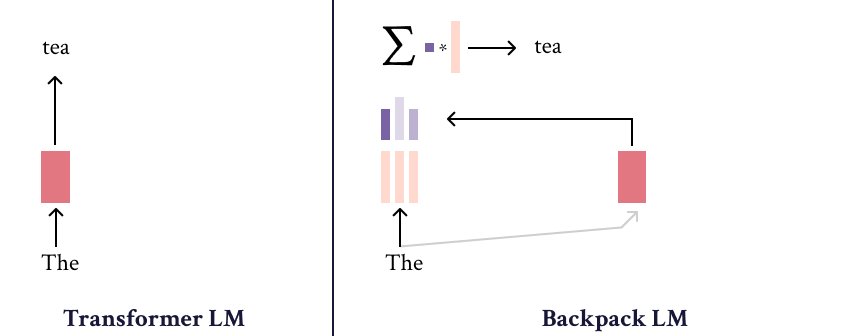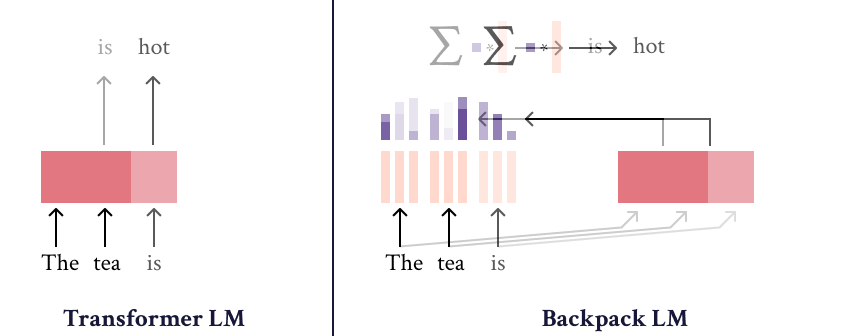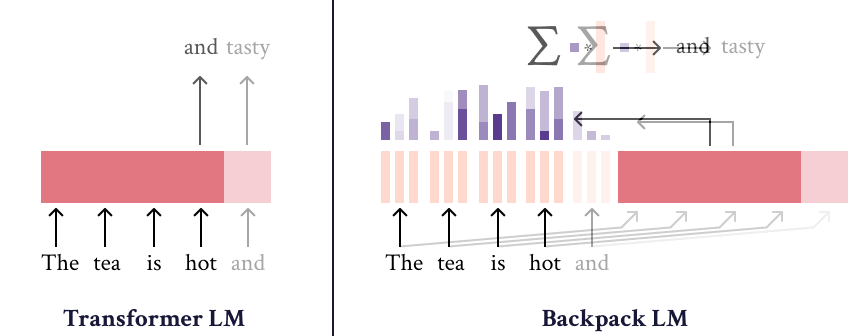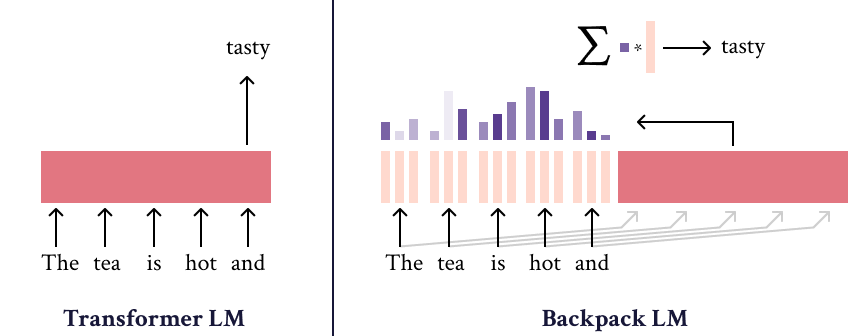
|
| 29 |
|
| 30 |
-
|
| 31 |
|
| 32 |
- [Model Card for Backpack-GPT2](#model-card-for--model_id-)
|
| 33 |
- [Table of Contents](#table-of-contents)
|
|
@@ -50,9 +46,9 @@ See also [backpackmodels.science](backpackmodels.science).
|
|
| 50 |
- [How to Get Started with the Model](#how-to-get-started-with-the-model)
|
| 51 |
|
| 52 |
|
| 53 |
-
|
| 54 |
|
| 55 |
-
|
| 56 |
|
| 57 |
<!-- Provide a longer summary of what this model is/does. -->
|
| 58 |
The Backpack-GPT2 is a [Backpack-based language model](https://arxiv.org/abs/2305.16765), an architecture intended to combine strong modeling performance with an interface for interpretability and control.
|
|
@@ -66,45 +62,64 @@ The Backpack-GPT2 is a [Backpack-based language model](https://arxiv.org/abs/230
|
|
| 66 |
- [GitHub Repo](https://github.com/john-hewitt/backpacks-flash-attn)
|
| 67 |
- [Associated Paper](https://huggingface.co/datasets/openwebtext)
|
| 68 |
|
| 69 |
-
|
| 70 |
|
| 71 |
This model is intended for use in the study and development of increasingly interpretable methods in natural language processing.
|
| 72 |
It is not directly fit for any production use.
|
| 73 |
|
| 74 |
|
| 75 |
-
|
| 76 |
|
| 77 |
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
|
| 78 |
|
| 79 |
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by the model may include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
|
| 80 |
This model in particular is limited in its capabilities, and with a brand new architecture, less is known about its biases than, e.g., Transformer-based models.
|
| 81 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 82 |
|
| 83 |
-
|
| 84 |
|
| 85 |
-
|
| 86 |
|
| 87 |
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
|
| 88 |
|
| 89 |
This model was trained on the [OpenWebText](https://huggingface.co/datasets/openwebtext) corpus.
|
| 90 |
|
| 91 |
|
| 92 |
-
|
| 93 |
|
| 94 |
This model was trained for 100k gradient steps with a batch size of 512k tokens and a linearly decaying learning rate from 6e-4 to zero, with a linear warmup of 5k steps.
|
| 95 |
|
| 96 |
-
|
| 97 |
|
| 98 |
- **Hardware Type:** 4 A100 GPUs (40G)
|
| 99 |
- **Hours used:** Roughly 4 days.
|
| 100 |
- **Cloud Provider:** Stanford compute.
|
| 101 |
- **Compute Region:** Stanford energy grid.
|
| 102 |
|
| 103 |
-
|
| 104 |
|
| 105 |
This model was trained to minimize the cross-entropy loss, and is a [Backpack language model](https://arxiv.org/pdf/2305.16765.pdf).
|
| 106 |
|
| 107 |
-
|
| 108 |
|
| 109 |
This model was trained on a slurm cluster.
|
| 110 |
|
|
@@ -116,7 +131,7 @@ This model was trained on 4 A100s.
|
|
| 116 |
|
| 117 |
This model was trained with [FlashAttention](https://github.com/HazyResearch/flash-attention) and [PyTorch](https://pytorch.org/)
|
| 118 |
|
| 119 |
-
|
| 120 |
|
| 121 |
**BibTeX:**
|
| 122 |
|
|
@@ -132,42 +147,14 @@ This model was trained with [FlashAttention](https://github.com/HazyResearch/fla
|
|
| 132 |
```
|
| 133 |
|
| 134 |
|
| 135 |
-
|
| 136 |
|
| 137 |
<!-- This section provides another layer of transparency and accountability. Whose views is this model card representing? How many voices were included in its construction? Etc. -->
|
| 138 |
|
| 139 |
John Hewitt
|
| 140 |
|
| 141 |
-
|
| 142 |
|
| 143 |
johnhew@cs.stanford.edu
|
| 144 |
|
| 145 |
-
# How to Get Started with the Model
|
| 146 |
-
|
| 147 |
-
```
|
| 148 |
-
import torch
|
| 149 |
-
import transformers
|
| 150 |
-
from transformers import AutoModelForCausalLM
|
| 151 |
-
|
| 152 |
-
|
| 153 |
-
model_id = "stanfordnlp/backpack-gpt2"
|
| 154 |
-
config = transformers.AutoConfig.from_pretrained(model_id, trust_remote_code=True)
|
| 155 |
-
torch_model = AutoModelForCausalLM.from_pretrained(model_id, config=config, trust_remote_code=True)
|
| 156 |
-
torch_model.eval()
|
| 157 |
-
|
| 158 |
-
input = torch.randint(0, 50264, (1, 512), dtype=torch.long)
|
| 159 |
-
torch_out = torch_model(
|
| 160 |
-
input,
|
| 161 |
-
position_ids=None,
|
| 162 |
-
)
|
| 163 |
-
torch_out = torch.nn.functional.softmax(torch_out.logits, dim=-1)
|
| 164 |
-
print(torch_out)
|
| 165 |
-
```
|
| 166 |
-
|
| 167 |
-
|
| 168 |
-
<details>
|
| 169 |
-
<summary> Click to expand </summary>
|
| 170 |
-
|
| 171 |
-
More information needed
|
| 172 |
|
| 173 |
-
</details>
|
|
|
|
| 12 |
- en
|
| 13 |
---
|
| 14 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 15 |
|
| 16 |
# Model Card for Backpack-GPT2
|
| 17 |
|
|
|
|
| 23 |
|
| 24 |

|
| 25 |
|
| 26 |
+
## Table of Contents
|
| 27 |
|
| 28 |
- [Model Card for Backpack-GPT2](#model-card-for--model_id-)
|
| 29 |
- [Table of Contents](#table-of-contents)
|
|
|
|
| 46 |
- [How to Get Started with the Model](#how-to-get-started-with-the-model)
|
| 47 |
|
| 48 |
|
| 49 |
+
## Model Details
|
| 50 |
|
| 51 |
+
### Model Description
|
| 52 |
|
| 53 |
<!-- Provide a longer summary of what this model is/does. -->
|
| 54 |
The Backpack-GPT2 is a [Backpack-based language model](https://arxiv.org/abs/2305.16765), an architecture intended to combine strong modeling performance with an interface for interpretability and control.
|
|
|
|
| 62 |
- [GitHub Repo](https://github.com/john-hewitt/backpacks-flash-attn)
|
| 63 |
- [Associated Paper](https://huggingface.co/datasets/openwebtext)
|
| 64 |
|
| 65 |
+
## Uses
|
| 66 |
|
| 67 |
This model is intended for use in the study and development of increasingly interpretable methods in natural language processing.
|
| 68 |
It is not directly fit for any production use.
|
| 69 |
|
| 70 |
|
| 71 |
+
## Bias, Risks, and Limitations
|
| 72 |
|
| 73 |
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
|
| 74 |
|
| 75 |
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by the model may include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
|
| 76 |
This model in particular is limited in its capabilities, and with a brand new architecture, less is known about its biases than, e.g., Transformer-based models.
|
| 77 |
|
| 78 |
+
## How to Get Started with the Model
|
| 79 |
+
|
| 80 |
+
```python
|
| 81 |
+
import torch
|
| 82 |
+
from transformers import AutoConfig, AutoModelForCausalLM
|
| 83 |
+
|
| 84 |
+
model_id = "stanfordnlp/backpack-gpt2"
|
| 85 |
+
config = AutoConfig.from_pretrained(model_id, trust_remote_code=True)
|
| 86 |
+
torch_model = AutoModelForCausalLM.from_pretrained(model_id, config=config, trust_remote_code=True)
|
| 87 |
+
torch_model.eval()
|
| 88 |
+
|
| 89 |
+
input = torch.randint(0, 50264, (1, 512), dtype=torch.long)
|
| 90 |
+
torch_out = torch_model(
|
| 91 |
+
input,
|
| 92 |
+
position_ids=None,
|
| 93 |
+
)
|
| 94 |
+
torch_out = torch.nn.functional.softmax(torch_out.logits, dim=-1)
|
| 95 |
+
print(torch_out)
|
| 96 |
+
```
|
| 97 |
|
| 98 |
+
## Training Details
|
| 99 |
|
| 100 |
+
### Training Data
|
| 101 |
|
| 102 |
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
|
| 103 |
|
| 104 |
This model was trained on the [OpenWebText](https://huggingface.co/datasets/openwebtext) corpus.
|
| 105 |
|
| 106 |
|
| 107 |
+
### Training Procedure
|
| 108 |
|
| 109 |
This model was trained for 100k gradient steps with a batch size of 512k tokens and a linearly decaying learning rate from 6e-4 to zero, with a linear warmup of 5k steps.
|
| 110 |
|
| 111 |
+
### Environmental Impact
|
| 112 |
|
| 113 |
- **Hardware Type:** 4 A100 GPUs (40G)
|
| 114 |
- **Hours used:** Roughly 4 days.
|
| 115 |
- **Cloud Provider:** Stanford compute.
|
| 116 |
- **Compute Region:** Stanford energy grid.
|
| 117 |
|
| 118 |
+
### Model Architecture and Objective
|
| 119 |
|
| 120 |
This model was trained to minimize the cross-entropy loss, and is a [Backpack language model](https://arxiv.org/pdf/2305.16765.pdf).
|
| 121 |
|
| 122 |
+
### Compute Infrastructure
|
| 123 |
|
| 124 |
This model was trained on a slurm cluster.
|
| 125 |
|
|
|
|
| 131 |
|
| 132 |
This model was trained with [FlashAttention](https://github.com/HazyResearch/flash-attention) and [PyTorch](https://pytorch.org/)
|
| 133 |
|
| 134 |
+
## Citation
|
| 135 |
|
| 136 |
**BibTeX:**
|
| 137 |
|
|
|
|
| 147 |
```
|
| 148 |
|
| 149 |
|
| 150 |
+
## Model Card Authors [optional]
|
| 151 |
|
| 152 |
<!-- This section provides another layer of transparency and accountability. Whose views is this model card representing? How many voices were included in its construction? Etc. -->
|
| 153 |
|
| 154 |
John Hewitt
|
| 155 |
|
| 156 |
+
## Model Card Contact
|
| 157 |
|
| 158 |
johnhew@cs.stanford.edu
|
| 159 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 160 |
|
|
|