
File size: 5,585 Bytes
651b002 63a3946 7405c46 d791b3c 651b002 7405c46 651b002 7405c46 651b002 7405c46 651b002 61d242b 651b002 61d242b 7405c46 651b002 7405c46 651b002 7405c46 651b002 7405c46 651b002 7405c46 651b002 a79f7cd 651b002 7405c46 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 |
import gradio as gr
import pytz
from datetime import datetime
from utilities import extract, create_time_series_features, train_model, process_personalized_collection, my_loss, \
cleanup
from memory_states import get_my_memory_states
from plot import make_plot
def anki_optimizer(file, timezone, next_day_starts_at, revlog_start_date, requestRetention,
progress=gr.Progress(track_tqdm=True)):
now = datetime.now()
prefix = now.strftime(f'%Y_%m_%d_%H_%M_%S')
proj_dir = extract(file, prefix)
type_sequence, df_out = create_time_series_features(revlog_start_date, timezone, next_day_starts_at, proj_dir)
w, dataset = train_model(proj_dir)
my_collection, rating_markdown = process_personalized_collection(requestRetention, w)
difficulty_distribution_padding, difficulty_distribution = get_my_memory_states(proj_dir, dataset, my_collection)
fig, suggested_retention_markdown = make_plot(proj_dir, type_sequence, w, difficulty_distribution_padding)
loss_markdown = my_loss(dataset, w)
difficulty_distribution = difficulty_distribution.to_string().replace("\n", "\n\n")
markdown_out = f"""
{suggested_retention_markdown}
# Loss Information
{loss_markdown}
# Difficulty Distribution
{difficulty_distribution}
# Ratings
{rating_markdown}
"""
w_markdown = f"""
# Updated Parameters
Copy and paste these as shown in step 5 of the instructions:
`var w = {w};`
Check out the Analysis tab for more detailed information."""
files = ['prediction.tsv', 'revlog.csv', 'revlog_history.tsv', 'stability_for_analysis.tsv',
'expected_repetitions.csv']
files_out = [proj_dir / file for file in files]
cleanup(proj_dir, files)
return w_markdown, df_out, fig, markdown_out, files_out
description = """
# FSRS4Anki Optimizer App
Based on the [tutorial](https://medium.com/@JarrettYe/how-to-use-the-next-generation-spaced-repetition-algorithm-fsrs-on-anki-5a591ca562e2)
of [Jarrett Ye](https://github.com/L-M-Sherlock). This application can give you personalized parameters without having to code.
Read the `Instructions` if its your first time using the app.
"""
with gr.Blocks() as demo:
with gr.Tab("FSRS4Anki Optimizer"):
with gr.Box():
gr.Markdown(description)
with gr.Box():
with gr.Row():
file = gr.File(label='Review Logs (Step 1)')
with gr.Column():
next_day_starts_at = gr.Number(value=4,
label="Next Day Starts at (Step 2)",
precision=0)
timezone = gr.Dropdown(label="Timezone (Step 3.1)", choices=pytz.all_timezones)
with gr.Accordion(label="Advanced Settings (Step 3.2)", open=False):
requestRetention = gr.Number(value=.9, label="Recommended to set between 0.8 0.9")
revlog_start_date = gr.Textbox(value="2006-10-05",
label="Replace it if you don't want the optimizer to use the review logs before a specific date.")
with gr.Row():
btn_plot = gr.Button('Optimize your Anki!')
with gr.Row():
w_output = gr.Markdown()
with gr.Tab("Instructions"):
with gr.Box():
gr.Markdown("""
# How to get personalized FSRS Anki parameters
If you have been using Anki for some time and have accumulated a lot of review logs, you can try this
FSRS4Anki optimizer app to generate parameters for you.
This is based on the amazing work of [Jarrett Ye](https://github.com/L-M-Sherlock). My goal is to further
democratize this technology so anyone can use it!
# Step 1 - Get the `Review Logs` to upload
1. Click the gear icon to the right of a deck’s name
2. Export
3. Check “Include scheduling information” and “Support older Anki versions”
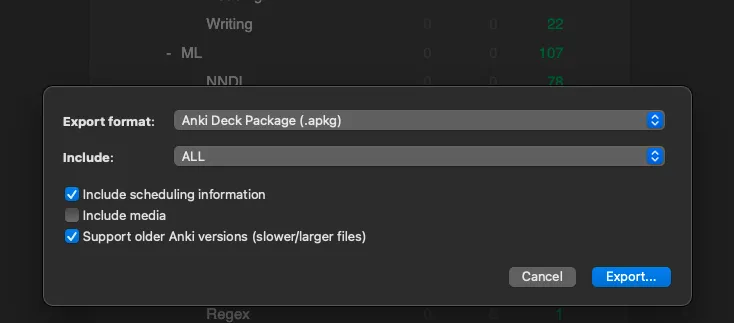
4. Export and upload that file to the app
# Step 2 - Get the `Next Day Starts At` parameter
1. Open preferences
2. Copy the next day starts at value and paste it in the app
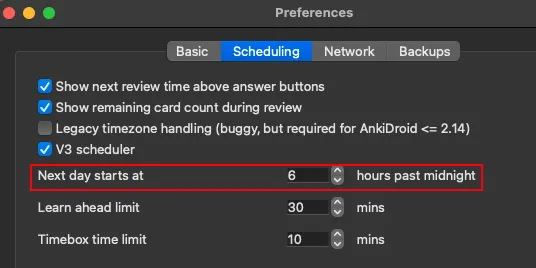
# Step 3 - Fill in the rest of the settings
1. Your `Time Zone`
2. `Advanced settings` if you know what you are doing
# Step 4 - Click `Optimize your Anki!`
1. After it runs copy `var w = [...]`
2. Check out the analysis tab for more info
# Step 5 - Update FSRS4Anki with the optimized parameters
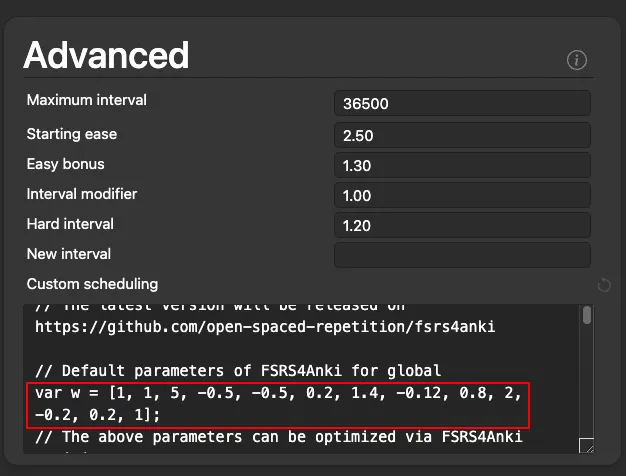
""")
with gr.Tab("Analysis"):
with gr.Row():
markdown_output = gr.Markdown()
with gr.Column():
df_output = gr.DataFrame()
plot_output = gr.Plot()
files_output = gr.Files(label="Analysis Files")
btn_plot.click(anki_optimizer,
inputs=[file, timezone, next_day_starts_at, revlog_start_date, requestRetention],
outputs=[w_output, df_output, plot_output, markdown_output, files_output])
if __name__ == '__main__':
demo.queue().launch(show_error=True)
|