

Commit
•
651b002
1
Parent(s):
392c159
Init commit
Browse files- .gitignore +1 -0
- app.py +112 -0
- fsrs4anki_optimizer.ipynb +0 -0
- memory_states.py +35 -0
- model.py +93 -0
- plot.py +92 -0
- projects/.gitkeep +0 -0
- requirements.txt +7 -0
- utilities.py +296 -0
.gitignore
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
.idea/
|
app.py
ADDED
|
@@ -0,0 +1,112 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import pytz
|
| 3 |
+
|
| 4 |
+
from datetime import datetime
|
| 5 |
+
|
| 6 |
+
from utilities import extract, create_time_series_features, train_model, process_personalized_collection, my_loss, \
|
| 7 |
+
cleanup
|
| 8 |
+
from memory_states import get_my_memory_states
|
| 9 |
+
from plot import make_plot
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def anki_optimizer(file, timezone, next_day_starts_at, revlog_start_date, requestRetention,
|
| 13 |
+
progress=gr.Progress(track_tqdm=True)):
|
| 14 |
+
now = datetime.now()
|
| 15 |
+
prefix = now.strftime(f'%Y_%m_%d_%H_%M_%S')
|
| 16 |
+
proj_dir = extract(file, prefix)
|
| 17 |
+
type_sequence, df_out = create_time_series_features(revlog_start_date, timezone, next_day_starts_at, proj_dir)
|
| 18 |
+
w, dataset = train_model(proj_dir)
|
| 19 |
+
my_collection, rating_markdown = process_personalized_collection(requestRetention, w)
|
| 20 |
+
difficulty_distribution_padding, difficulty_distribution = get_my_memory_states(proj_dir, dataset, my_collection)
|
| 21 |
+
fig, suggested_retention_markdown = make_plot(proj_dir, type_sequence, w, difficulty_distribution_padding)
|
| 22 |
+
loss_markdown = my_loss(dataset, w)
|
| 23 |
+
difficulty_distribution = difficulty_distribution.to_string().replace("\n", "\n\n")
|
| 24 |
+
markdown_out = f"""
|
| 25 |
+
{suggested_retention_markdown}
|
| 26 |
+
|
| 27 |
+
# Loss Information
|
| 28 |
+
{loss_markdown}
|
| 29 |
+
|
| 30 |
+
# Difficulty Distribution
|
| 31 |
+
{difficulty_distribution}
|
| 32 |
+
|
| 33 |
+
# Ratings
|
| 34 |
+
{rating_markdown}
|
| 35 |
+
"""
|
| 36 |
+
|
| 37 |
+
w_markdown = f"""
|
| 38 |
+
# These are the weights for step 5
|
| 39 |
+
`var w = {w};`"""
|
| 40 |
+
files = ['prediction.tsv', 'revlog.csv', 'revlog_history.tsv', 'stability_for_analysis.tsv',
|
| 41 |
+
'expected_repetitions.csv']
|
| 42 |
+
files_out = [proj_dir / file for file in files]
|
| 43 |
+
cleanup(proj_dir, files)
|
| 44 |
+
return w_markdown, df_out, fig, markdown_out, files_out
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
with gr.Blocks() as demo:
|
| 48 |
+
with gr.Tab("FSRS4Anki Optimizer"):
|
| 49 |
+
with gr.Box():
|
| 50 |
+
gr.Markdown("""
|
| 51 |
+
Based on the [tutorial](https://medium.com/@JarrettYe/how-to-use-the-next-generation-spaced-repetition-algorithm-fsrs-on-anki-5a591ca562e2) of [Jarrett Ye](https://github.com/L-M-Sherlock)
|
| 52 |
+
Check out the instructions on the next tab.
|
| 53 |
+
""")
|
| 54 |
+
with gr.Box():
|
| 55 |
+
with gr.Row():
|
| 56 |
+
file = gr.File(label='Review Logs')
|
| 57 |
+
timezone = gr.Dropdown(label="Choose your timezone", choices=pytz.all_timezones)
|
| 58 |
+
with gr.Row():
|
| 59 |
+
next_day_starts_at = gr.Number(value=4,
|
| 60 |
+
label="Replace it with your Anki's setting in Preferences -> Scheduling.",
|
| 61 |
+
precision=0)
|
| 62 |
+
with gr.Accordion(label="Advanced Settings", open=False):
|
| 63 |
+
requestRetention = gr.Number(value=.9, label="Recommended to set between 0.8 0.9")
|
| 64 |
+
with gr.Row():
|
| 65 |
+
revlog_start_date = gr.Textbox(value="2006-10-05",
|
| 66 |
+
label="Replace it if you don't want the optimizer to use the review logs before a specific date.")
|
| 67 |
+
with gr.Row():
|
| 68 |
+
btn_plot = gr.Button('Optimize your Anki!')
|
| 69 |
+
with gr.Row():
|
| 70 |
+
w_output = gr.Markdown()
|
| 71 |
+
with gr.Tab("Instructions"):
|
| 72 |
+
with gr.Box():
|
| 73 |
+
gr.Markdown("""
|
| 74 |
+
# How to get personalized Anki parameters
|
| 75 |
+
If you have been using Anki for some time and have accumulated a lot of review logs, you can try this FSRS4Anki
|
| 76 |
+
optimizer app to generate parameters for you.
|
| 77 |
+
|
| 78 |
+
This is based on the amazing work of [Jarrett Ye](https://github.com/L-M-Sherlock)
|
| 79 |
+
# Step 1 - Get the review logs to upload
|
| 80 |
+
1. Click the gear icon to the right of a deck’s name
|
| 81 |
+
2. Export
|
| 82 |
+
3. Check “Include scheduling information” and “Support older Anki versions”
|
| 83 |
+
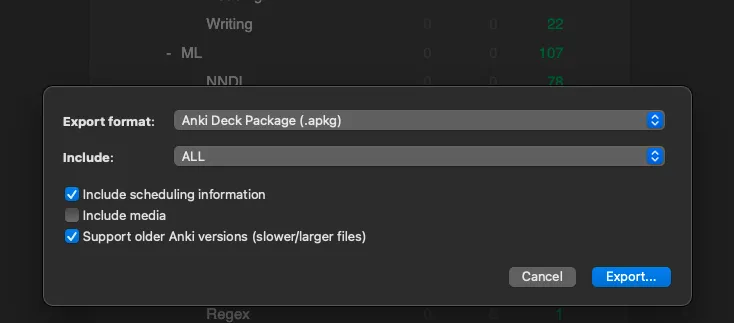
|
| 84 |
+
4. Export and upload that file to the app
|
| 85 |
+
|
| 86 |
+
# Step 2 - Get the `next_day_starts_at` parameter
|
| 87 |
+
1. Open preferences
|
| 88 |
+
2. Copy the next day starts at value and paste it in the app
|
| 89 |
+
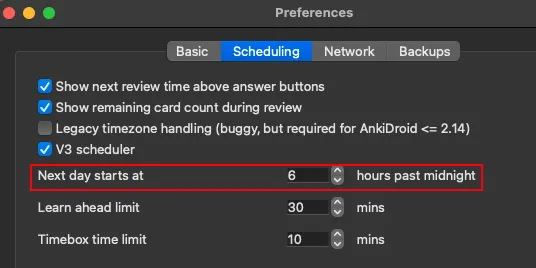
|
| 90 |
+
|
| 91 |
+
# Step 3 - Fill in the rest of the settings
|
| 92 |
+
|
| 93 |
+
# Step 4 Click run
|
| 94 |
+
|
| 95 |
+
# Step 5 - Replace the default parameters in FSRS4Anki with the optimized parameters
|
| 96 |
+
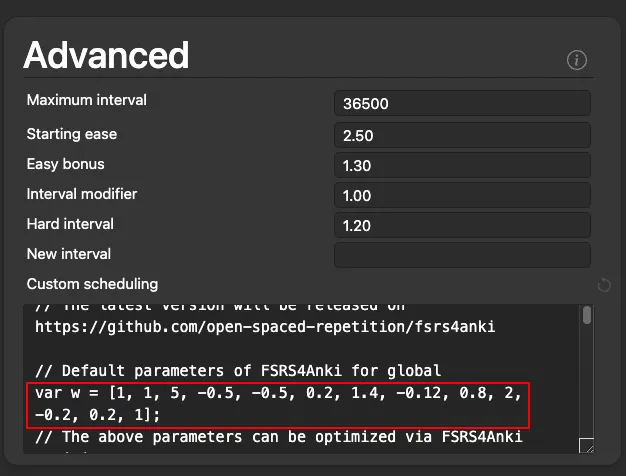
|
| 97 |
+
""")
|
| 98 |
+
with gr.Tab("Analysis"):
|
| 99 |
+
with gr.Row():
|
| 100 |
+
markdown_output = gr.Markdown()
|
| 101 |
+
df_output = gr.DataFrame()
|
| 102 |
+
with gr.Row():
|
| 103 |
+
plot_output = gr.Plot()
|
| 104 |
+
with gr.Row():
|
| 105 |
+
files_output = gr.Files(label="Analysis Files")
|
| 106 |
+
|
| 107 |
+
btn_plot.click(anki_optimizer,
|
| 108 |
+
inputs=[file, timezone, next_day_starts_at, revlog_start_date, requestRetention],
|
| 109 |
+
outputs=[w_output, df_output, plot_output, markdown_output, files_output])
|
| 110 |
+
demo.queue().launch(debug=True, show_error=True)
|
| 111 |
+
|
| 112 |
+
# demo.queue().launch(debug=True)
|
fsrs4anki_optimizer.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
memory_states.py
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
from functools import partial
|
| 3 |
+
|
| 4 |
+
import pandas as pd
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def predict_memory_states(my_collection, group):
|
| 8 |
+
states = my_collection.states(*group.name)
|
| 9 |
+
group['stability'] = float(states[0])
|
| 10 |
+
group['difficulty'] = float(states[1])
|
| 11 |
+
group['count'] = len(group)
|
| 12 |
+
return pd.DataFrame({
|
| 13 |
+
'r_history': [group.name[1]],
|
| 14 |
+
't_history': [group.name[0]],
|
| 15 |
+
'stability': [round(float(states[0]), 2)],
|
| 16 |
+
'difficulty': [round(float(states[1]), 2)],
|
| 17 |
+
'count': [len(group)]
|
| 18 |
+
})
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def get_my_memory_states(proj_dir, dataset, my_collection):
|
| 22 |
+
prediction = dataset.groupby(by=['t_history', 'r_history']).progress_apply(
|
| 23 |
+
partial(predict_memory_states, my_collection))
|
| 24 |
+
prediction.reset_index(drop=True, inplace=True)
|
| 25 |
+
prediction.sort_values(by=['r_history'], inplace=True)
|
| 26 |
+
prediction.to_csv(proj_dir / "prediction.tsv", sep='\t', index=None)
|
| 27 |
+
print("prediction.tsv saved.")
|
| 28 |
+
prediction['difficulty'] = prediction['difficulty'].map(lambda x: int(round(x)))
|
| 29 |
+
difficulty_distribution = prediction.groupby(by=['difficulty'])['count'].sum() / prediction['count'].sum()
|
| 30 |
+
print(difficulty_distribution)
|
| 31 |
+
difficulty_distribution_padding = np.zeros(10)
|
| 32 |
+
for i in range(10):
|
| 33 |
+
if i + 1 in difficulty_distribution.index:
|
| 34 |
+
difficulty_distribution_padding[i] = difficulty_distribution.loc[i + 1]
|
| 35 |
+
return difficulty_distribution_padding, difficulty_distribution
|
model.py
ADDED
|
@@ -0,0 +1,93 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import torch
|
| 3 |
+
from torch import nn
|
| 4 |
+
|
| 5 |
+
init_w = [1, 1, 5, -0.5, -0.5, 0.2, 1.4, -0.02, 0.8, 2, -0.2, 0.5, 1]
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class FSRS(nn.Module):
|
| 9 |
+
def __init__(self, w):
|
| 10 |
+
super(FSRS, self).__init__()
|
| 11 |
+
self.w = nn.Parameter(torch.FloatTensor(w))
|
| 12 |
+
self.zero = torch.FloatTensor([0.0])
|
| 13 |
+
|
| 14 |
+
def forward(self, x, s, d):
|
| 15 |
+
'''
|
| 16 |
+
:param x: [review interval, review response]
|
| 17 |
+
:param s: stability
|
| 18 |
+
:param d: difficulty
|
| 19 |
+
:return:
|
| 20 |
+
'''
|
| 21 |
+
if torch.equal(s, self.zero):
|
| 22 |
+
# first learn, init memory states
|
| 23 |
+
new_s = self.w[0] + self.w[1] * (x[1] - 1)
|
| 24 |
+
new_d = self.w[2] + self.w[3] * (x[1] - 3)
|
| 25 |
+
new_d = new_d.clamp(1, 10)
|
| 26 |
+
else:
|
| 27 |
+
r = torch.exp(np.log(0.9) * x[0] / s)
|
| 28 |
+
new_d = d + self.w[4] * (x[1] - 3)
|
| 29 |
+
new_d = self.mean_reversion(self.w[2], new_d)
|
| 30 |
+
new_d = new_d.clamp(1, 10)
|
| 31 |
+
# recall
|
| 32 |
+
if x[1] > 1:
|
| 33 |
+
new_s = s * (1 + torch.exp(self.w[6]) *
|
| 34 |
+
(11 - new_d) *
|
| 35 |
+
torch.pow(s, self.w[7]) *
|
| 36 |
+
(torch.exp((1 - r) * self.w[8]) - 1))
|
| 37 |
+
# forget
|
| 38 |
+
else:
|
| 39 |
+
new_s = self.w[9] * torch.pow(new_d, self.w[10]) * torch.pow(
|
| 40 |
+
s, self.w[11]) * torch.exp((1 - r) * self.w[12])
|
| 41 |
+
return new_s, new_d
|
| 42 |
+
|
| 43 |
+
def loss(self, s, t, r):
|
| 44 |
+
return - (r * np.log(0.9) * t / s + (1 - r) * torch.log(1 - torch.exp(np.log(0.9) * t / s)))
|
| 45 |
+
|
| 46 |
+
def mean_reversion(self, init, current):
|
| 47 |
+
return self.w[5] * init + (1-self.w[5]) * current
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
class WeightClipper(object):
|
| 51 |
+
def __init__(self, frequency=1):
|
| 52 |
+
self.frequency = frequency
|
| 53 |
+
|
| 54 |
+
def __call__(self, module):
|
| 55 |
+
if hasattr(module, 'w'):
|
| 56 |
+
w = module.w.data
|
| 57 |
+
w[0] = w[0].clamp(0.1, 10) # initStability
|
| 58 |
+
w[1] = w[1].clamp(0.1, 5) # initStabilityRatingFactor
|
| 59 |
+
w[2] = w[2].clamp(1, 10) # initDifficulty
|
| 60 |
+
w[3] = w[3].clamp(-5, -0.1) # initDifficultyRatingFactor
|
| 61 |
+
w[4] = w[4].clamp(-5, -0.1) # updateDifficultyRatingFactor
|
| 62 |
+
w[5] = w[5].clamp(0, 0.5) # difficultyMeanReversionFactor
|
| 63 |
+
w[6] = w[6].clamp(0, 2) # recallFactor
|
| 64 |
+
w[7] = w[7].clamp(-0.2, -0.01) # recallStabilityDecay
|
| 65 |
+
w[8] = w[8].clamp(0.01, 1.5) # recallRetrievabilityFactor
|
| 66 |
+
w[9] = w[9].clamp(0.5, 5) # forgetFactor
|
| 67 |
+
w[10] = w[10].clamp(-2, -0.01) # forgetDifficultyDecay
|
| 68 |
+
w[11] = w[11].clamp(0.01, 0.9) # forgetStabilityDecay
|
| 69 |
+
w[12] = w[12].clamp(0.01, 2) # forgetRetrievabilityFactor
|
| 70 |
+
module.w.data = w
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def lineToTensor(line):
|
| 74 |
+
ivl = line[0].split(',')
|
| 75 |
+
response = line[1].split(',')
|
| 76 |
+
tensor = torch.zeros(len(response), 2)
|
| 77 |
+
for li, response in enumerate(response):
|
| 78 |
+
tensor[li][0] = int(ivl[li])
|
| 79 |
+
tensor[li][1] = int(response)
|
| 80 |
+
return tensor
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
class Collection:
|
| 84 |
+
def __init__(self, w):
|
| 85 |
+
self.model = FSRS(w)
|
| 86 |
+
|
| 87 |
+
def states(self, t_history, r_history):
|
| 88 |
+
with torch.no_grad():
|
| 89 |
+
line_tensor = lineToTensor(list(zip([t_history], [r_history]))[0])
|
| 90 |
+
output_t = [(self.model.zero, self.model.zero)]
|
| 91 |
+
for input_t in line_tensor:
|
| 92 |
+
output_t.append(self.model(input_t, *output_t[-1]))
|
| 93 |
+
return output_t[-1]
|
plot.py
ADDED
|
@@ -0,0 +1,92 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from tqdm.auto import trange
|
| 2 |
+
import gradio as gr
|
| 3 |
+
import pandas as pd
|
| 4 |
+
import numpy as np
|
| 5 |
+
import plotly.express as px
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def make_plot(proj_dir, type_sequence, w, difficulty_distribution_padding, progress=gr.Progress(track_tqdm=True)):
|
| 9 |
+
base = 1.01
|
| 10 |
+
index_len = 800
|
| 11 |
+
index_offset = 150
|
| 12 |
+
d_range = 10
|
| 13 |
+
d_offset = 1
|
| 14 |
+
r_repetitions = 1
|
| 15 |
+
f_repetitions = 2.3
|
| 16 |
+
max_repetitions = 200000
|
| 17 |
+
|
| 18 |
+
type_block = dict()
|
| 19 |
+
type_count = dict()
|
| 20 |
+
last_t = type_sequence[0]
|
| 21 |
+
type_block[last_t] = 1
|
| 22 |
+
type_count[last_t] = 1
|
| 23 |
+
for t in type_sequence[1:]:
|
| 24 |
+
type_count[t] = type_count.setdefault(t, 0) + 1
|
| 25 |
+
if t != last_t:
|
| 26 |
+
type_block[t] = type_block.setdefault(t, 0) + 1
|
| 27 |
+
last_t = t
|
| 28 |
+
if 2 in type_count and 2 in type_block:
|
| 29 |
+
f_repetitions = round(type_count[2] / type_block[2] + 1, 1)
|
| 30 |
+
|
| 31 |
+
def stability2index(stability):
|
| 32 |
+
return int(round(np.log(stability) / np.log(base)) + index_offset)
|
| 33 |
+
|
| 34 |
+
def init_stability(d):
|
| 35 |
+
return max(((d - w[2]) / w[3] + 2) * w[1] + w[0], np.power(base, -index_offset))
|
| 36 |
+
|
| 37 |
+
def cal_next_recall_stability(s, r, d, response):
|
| 38 |
+
if response == 1:
|
| 39 |
+
return s * (1 + np.exp(w[6]) * (11 - d) * np.power(s, w[7]) * (np.exp((1 - r) * w[8]) - 1))
|
| 40 |
+
else:
|
| 41 |
+
return w[9] * np.power(d, w[10]) * np.power(s, w[11]) * np.exp((1 - r) * w[12])
|
| 42 |
+
|
| 43 |
+
stability_list = np.array([np.power(base, i - index_offset) for i in range(index_len)])
|
| 44 |
+
print(f"terminal stability: {stability_list.max(): .2f}")
|
| 45 |
+
df = pd.DataFrame(columns=["retention", "difficulty", "repetitions"])
|
| 46 |
+
|
| 47 |
+
for percentage in trange(96, 70, -2, desc='Repetition vs Retention plot'):
|
| 48 |
+
recall = percentage / 100
|
| 49 |
+
repetitions_list = np.zeros((d_range, index_len))
|
| 50 |
+
repetitions_list[:, :-1] = max_repetitions
|
| 51 |
+
for d in range(d_range, 0, -1):
|
| 52 |
+
s0 = init_stability(d)
|
| 53 |
+
s0_index = stability2index(s0)
|
| 54 |
+
diff = max_repetitions
|
| 55 |
+
while diff > 0.1:
|
| 56 |
+
s0_repetitions = repetitions_list[d - 1][s0_index]
|
| 57 |
+
for s_index in range(index_len - 2, -1, -1):
|
| 58 |
+
stability = stability_list[s_index];
|
| 59 |
+
interval = max(1, round(stability * np.log(recall) / np.log(0.9)))
|
| 60 |
+
p_recall = np.power(0.9, interval / stability)
|
| 61 |
+
recall_s = cal_next_recall_stability(stability, p_recall, d, 1)
|
| 62 |
+
forget_d = min(d + d_offset, 10)
|
| 63 |
+
forget_s = cal_next_recall_stability(stability, p_recall, forget_d, 0)
|
| 64 |
+
recall_s_index = min(stability2index(recall_s), index_len - 1)
|
| 65 |
+
forget_s_index = min(max(stability2index(forget_s), 0), index_len - 1)
|
| 66 |
+
recall_repetitions = repetitions_list[d - 1][recall_s_index] + r_repetitions
|
| 67 |
+
forget_repetitions = repetitions_list[forget_d - 1][forget_s_index] + f_repetitions
|
| 68 |
+
exp_repetitions = p_recall * recall_repetitions + (1.0 - p_recall) * forget_repetitions
|
| 69 |
+
if exp_repetitions < repetitions_list[d - 1][s_index]:
|
| 70 |
+
repetitions_list[d - 1][s_index] = exp_repetitions
|
| 71 |
+
diff = s0_repetitions - repetitions_list[d - 1][s0_index]
|
| 72 |
+
df.loc[0 if pd.isnull(df.index.max()) else df.index.max() + 1] = [recall, d, s0_repetitions]
|
| 73 |
+
|
| 74 |
+
df.sort_values(by=["difficulty", "retention"], inplace=True)
|
| 75 |
+
df.to_csv(proj_dir/"expected_repetitions.csv", index=False)
|
| 76 |
+
print("expected_repetitions.csv saved.")
|
| 77 |
+
|
| 78 |
+
optimal_retention_list = np.zeros(10)
|
| 79 |
+
df2 = pd.DataFrame()
|
| 80 |
+
for d in range(1, d_range + 1):
|
| 81 |
+
retention = df[df["difficulty"] == d]["retention"]
|
| 82 |
+
repetitions = df[df["difficulty"] == d]["repetitions"]
|
| 83 |
+
optimal_retention = retention.iat[repetitions.argmin()]
|
| 84 |
+
optimal_retention_list[d - 1] = optimal_retention
|
| 85 |
+
df2 = df2.append(
|
| 86 |
+
pd.DataFrame({'retention': retention, 'expected repetitions': repetitions, 'd': d, 'r': optimal_retention}))
|
| 87 |
+
|
| 88 |
+
fig = px.line(df2, x="retention", y="expected repetitions", color='d', log_y=True)
|
| 89 |
+
|
| 90 |
+
print(f"\n-----suggested retention: {np.inner(difficulty_distribution_padding, optimal_retention_list):.2f}-----")
|
| 91 |
+
suggested_retention_markdown = f"""# Suggested Retention: `{np.inner(difficulty_distribution_padding, optimal_retention_list):.2f}`"""
|
| 92 |
+
return fig, suggested_retention_markdown
|
projects/.gitkeep
ADDED
|
File without changes
|
requirements.txt
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
matplotlib==3.4.3
|
| 2 |
+
numpy==1.23.3
|
| 3 |
+
pandas==1.3.2
|
| 4 |
+
scikit_learn==1.1.2
|
| 5 |
+
torch==1.9.0
|
| 6 |
+
tqdm==4.64.1
|
| 7 |
+
plotly==5.13.0
|
utilities.py
ADDED
|
@@ -0,0 +1,296 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from functools import partial
|
| 2 |
+
import datetime
|
| 3 |
+
from zipfile import ZipFile
|
| 4 |
+
|
| 5 |
+
import sqlite3
|
| 6 |
+
import time
|
| 7 |
+
|
| 8 |
+
import gradio as gr
|
| 9 |
+
from tqdm.auto import tqdm
|
| 10 |
+
import pandas as pd
|
| 11 |
+
import numpy as np
|
| 12 |
+
import os
|
| 13 |
+
from datetime import timedelta, datetime
|
| 14 |
+
from pathlib import Path
|
| 15 |
+
|
| 16 |
+
import torch
|
| 17 |
+
from sklearn.utils import shuffle
|
| 18 |
+
|
| 19 |
+
from model import Collection, init_w, FSRS, WeightClipper, lineToTensor
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
# Extract the collection file or deck file to get the .anki21 database.
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def extract(file, prefix):
|
| 26 |
+
proj_dir = Path(f'projects/{prefix}_{file.orig_name.replace(".", "_").replace("@", "_")}')
|
| 27 |
+
with ZipFile(file, 'r') as zip_ref:
|
| 28 |
+
zip_ref.extractall(proj_dir)
|
| 29 |
+
print(f"Extracted {file.orig_name} successfully!")
|
| 30 |
+
return proj_dir
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def create_time_series_features(revlog_start_date, timezone, next_day_starts_at, proj_dir,
|
| 34 |
+
progress=gr.Progress(track_tqdm=True)):
|
| 35 |
+
if os.path.isfile(proj_dir / "collection.anki21b"):
|
| 36 |
+
os.remove(proj_dir / "collection.anki21b")
|
| 37 |
+
raise Exception(
|
| 38 |
+
"Please export the file with `support older Anki versions` if you use the latest version of Anki.")
|
| 39 |
+
elif os.path.isfile(proj_dir / "collection.anki21"):
|
| 40 |
+
con = sqlite3.connect(proj_dir / "collection.anki21")
|
| 41 |
+
elif os.path.isfile(proj_dir / "collection.anki2"):
|
| 42 |
+
con = sqlite3.connect(proj_dir / "collection.anki2")
|
| 43 |
+
else:
|
| 44 |
+
raise Exception("Collection not exist!")
|
| 45 |
+
cur = con.cursor()
|
| 46 |
+
res = cur.execute("SELECT * FROM revlog")
|
| 47 |
+
revlog = res.fetchall()
|
| 48 |
+
|
| 49 |
+
df = pd.DataFrame(revlog)
|
| 50 |
+
df.columns = ['id', 'cid', 'usn', 'r', 'ivl',
|
| 51 |
+
'last_lvl', 'factor', 'time', 'type']
|
| 52 |
+
df = df[(df['cid'] <= time.time() * 1000) &
|
| 53 |
+
(df['id'] <= time.time() * 1000) &
|
| 54 |
+
(df['r'] > 0) &
|
| 55 |
+
(df['id'] >= time.mktime(datetime.strptime(revlog_start_date, "%Y-%m-%d").timetuple()) * 1000)].copy()
|
| 56 |
+
df['create_date'] = pd.to_datetime(df['cid'] // 1000, unit='s')
|
| 57 |
+
df['create_date'] = df['create_date'].dt.tz_localize(
|
| 58 |
+
'UTC').dt.tz_convert(timezone)
|
| 59 |
+
df['review_date'] = pd.to_datetime(df['id'] // 1000, unit='s')
|
| 60 |
+
df['review_date'] = df['review_date'].dt.tz_localize(
|
| 61 |
+
'UTC').dt.tz_convert(timezone)
|
| 62 |
+
df.drop(df[df['review_date'].dt.year < 2006].index, inplace=True)
|
| 63 |
+
df.sort_values(by=['cid', 'id'], inplace=True, ignore_index=True)
|
| 64 |
+
type_sequence = np.array(df['type'])
|
| 65 |
+
df.to_csv(proj_dir / "revlog.csv", index=False)
|
| 66 |
+
print("revlog.csv saved.")
|
| 67 |
+
df = df[(df['type'] == 0) | (df['type'] == 1)].copy()
|
| 68 |
+
df['real_days'] = df['review_date'] - timedelta(hours=next_day_starts_at)
|
| 69 |
+
df['real_days'] = pd.DatetimeIndex(df['real_days'].dt.floor('D')).to_julian_date()
|
| 70 |
+
df.drop_duplicates(['cid', 'real_days'], keep='first', inplace=True)
|
| 71 |
+
df['delta_t'] = df.real_days.diff()
|
| 72 |
+
df.dropna(inplace=True)
|
| 73 |
+
df['delta_t'] = df['delta_t'].astype(dtype=int)
|
| 74 |
+
df['i'] = 1
|
| 75 |
+
df['r_history'] = ""
|
| 76 |
+
df['t_history'] = ""
|
| 77 |
+
col_idx = {key: i for i, key in enumerate(df.columns)}
|
| 78 |
+
|
| 79 |
+
# code from https://github.com/L-M-Sherlock/anki_revlog_analysis/blob/main/revlog_analysis.py
|
| 80 |
+
def get_feature(x):
|
| 81 |
+
for idx, log in enumerate(x.itertuples()):
|
| 82 |
+
if idx == 0:
|
| 83 |
+
x.iloc[idx, col_idx['delta_t']] = 0
|
| 84 |
+
if idx == x.shape[0] - 1:
|
| 85 |
+
break
|
| 86 |
+
x.iloc[idx + 1, col_idx['i']] = x.iloc[idx, col_idx['i']] + 1
|
| 87 |
+
x.iloc[idx + 1, col_idx[
|
| 88 |
+
't_history']] = f"{x.iloc[idx, col_idx['t_history']]},{x.iloc[idx, col_idx['delta_t']]}"
|
| 89 |
+
x.iloc[idx + 1, col_idx['r_history']] = f"{x.iloc[idx, col_idx['r_history']]},{x.iloc[idx, col_idx['r']]}"
|
| 90 |
+
return x
|
| 91 |
+
|
| 92 |
+
tqdm.pandas(desc='Saving Trainset')
|
| 93 |
+
df = df.groupby('cid', as_index=False).progress_apply(get_feature)
|
| 94 |
+
df["t_history"] = df["t_history"].map(lambda x: x[1:] if len(x) > 1 else x)
|
| 95 |
+
df["r_history"] = df["r_history"].map(lambda x: x[1:] if len(x) > 1 else x)
|
| 96 |
+
df.to_csv(proj_dir / 'revlog_history.tsv', sep="\t", index=False)
|
| 97 |
+
print("Trainset saved.")
|
| 98 |
+
|
| 99 |
+
def cal_retention(group: pd.DataFrame) -> pd.DataFrame:
|
| 100 |
+
group['retention'] = round(group['r'].map(lambda x: {1: 0, 2: 1, 3: 1, 4: 1}[x]).mean(), 4)
|
| 101 |
+
group['total_cnt'] = group.shape[0]
|
| 102 |
+
return group
|
| 103 |
+
|
| 104 |
+
tqdm.pandas(desc='Calculating Retention')
|
| 105 |
+
df = df.groupby(by=['r_history', 'delta_t']).progress_apply(cal_retention)
|
| 106 |
+
print("Retention calculated.")
|
| 107 |
+
df = df.drop(columns=['id', 'cid', 'usn', 'ivl', 'last_lvl', 'factor', 'time', 'type', 'create_date', 'review_date',
|
| 108 |
+
'real_days', 'r', 't_history'])
|
| 109 |
+
df.drop_duplicates(inplace=True)
|
| 110 |
+
df = df[(df['retention'] < 1) & (df['retention'] > 0)]
|
| 111 |
+
|
| 112 |
+
def cal_stability(group: pd.DataFrame) -> pd.DataFrame:
|
| 113 |
+
if group['i'].values[0] > 1:
|
| 114 |
+
r_ivl_cnt = sum(group['delta_t'] * group['retention'].map(np.log) * pow(group['total_cnt'], 2))
|
| 115 |
+
ivl_ivl_cnt = sum(group['delta_t'].map(lambda x: x ** 2) * pow(group['total_cnt'], 2))
|
| 116 |
+
group['stability'] = round(np.log(0.9) / (r_ivl_cnt / ivl_ivl_cnt), 1)
|
| 117 |
+
else:
|
| 118 |
+
group['stability'] = 0.0
|
| 119 |
+
group['group_cnt'] = sum(group['total_cnt'])
|
| 120 |
+
group['avg_retention'] = round(
|
| 121 |
+
sum(group['retention'] * pow(group['total_cnt'], 2)) / sum(pow(group['total_cnt'], 2)), 3)
|
| 122 |
+
group['avg_interval'] = round(
|
| 123 |
+
sum(group['delta_t'] * pow(group['total_cnt'], 2)) / sum(pow(group['total_cnt'], 2)), 1)
|
| 124 |
+
del group['total_cnt']
|
| 125 |
+
del group['retention']
|
| 126 |
+
del group['delta_t']
|
| 127 |
+
return group
|
| 128 |
+
|
| 129 |
+
tqdm.pandas(desc='Calculating Stability')
|
| 130 |
+
df = df.groupby(by=['r_history']).progress_apply(cal_stability)
|
| 131 |
+
print("Stability calculated.")
|
| 132 |
+
df.reset_index(drop=True, inplace=True)
|
| 133 |
+
df.drop_duplicates(inplace=True)
|
| 134 |
+
df.sort_values(by=['r_history'], inplace=True, ignore_index=True)
|
| 135 |
+
|
| 136 |
+
df_out = pd.DataFrame()
|
| 137 |
+
if df.shape[0] > 0:
|
| 138 |
+
for idx in tqdm(df.index):
|
| 139 |
+
item = df.loc[idx]
|
| 140 |
+
index = df[(df['i'] == item['i'] + 1) & (df['r_history'].str.startswith(item['r_history']))].index
|
| 141 |
+
df.loc[index, 'last_stability'] = item['stability']
|
| 142 |
+
df['factor'] = round(df['stability'] / df['last_stability'], 2)
|
| 143 |
+
df = df[(df['i'] >= 2) & (df['group_cnt'] >= 100)]
|
| 144 |
+
df['last_recall'] = df['r_history'].map(lambda x: x[-1])
|
| 145 |
+
df = df[df.groupby(['i', 'r_history'])['group_cnt'].transform(max) == df['group_cnt']]
|
| 146 |
+
df.to_csv(proj_dir / 'stability_for_analysis.tsv', sep='\t', index=None)
|
| 147 |
+
print("1:again, 2:hard, 3:good, 4:easy\n")
|
| 148 |
+
print(df[df['r_history'].str.contains(r'^[1-4][^124]*$', regex=True)][
|
| 149 |
+
['r_history', 'avg_interval', 'avg_retention', 'stability', 'factor', 'group_cnt']].to_string(
|
| 150 |
+
index=False))
|
| 151 |
+
print("Analysis saved!")
|
| 152 |
+
|
| 153 |
+
df_out = df[df['r_history'].str.contains(r'^[1-4][^124]*$', regex=True)][
|
| 154 |
+
['r_history', 'avg_interval', 'avg_retention', 'stability', 'factor', 'group_cnt']]
|
| 155 |
+
return type_sequence, df_out
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
def train_model(proj_dir, progress=gr.Progress(track_tqdm=True)):
|
| 159 |
+
model = FSRS(init_w)
|
| 160 |
+
|
| 161 |
+
clipper = WeightClipper()
|
| 162 |
+
optimizer = torch.optim.Adam(model.parameters(), lr=5e-4)
|
| 163 |
+
|
| 164 |
+
dataset = pd.read_csv(proj_dir / "revlog_history.tsv", sep='\t', index_col=None,
|
| 165 |
+
dtype={'r_history': str, 't_history': str})
|
| 166 |
+
dataset = dataset[(dataset['i'] > 1) & (dataset['delta_t'] > 0) & (dataset['t_history'].str.count(',0') == 0)]
|
| 167 |
+
|
| 168 |
+
tqdm.pandas(desc='Tensorizing Line')
|
| 169 |
+
dataset['tensor'] = dataset.progress_apply(lambda x: lineToTensor(list(zip([x['t_history']], [x['r_history']]))[0]),
|
| 170 |
+
axis=1)
|
| 171 |
+
print("Tensorized!")
|
| 172 |
+
|
| 173 |
+
pre_train_set = dataset[dataset['i'] == 2]
|
| 174 |
+
# pretrain
|
| 175 |
+
epoch_len = len(pre_train_set)
|
| 176 |
+
n_epoch = 1
|
| 177 |
+
pbar = tqdm(desc="Pre-training", colour="red", total=epoch_len * n_epoch)
|
| 178 |
+
|
| 179 |
+
for k in range(n_epoch):
|
| 180 |
+
for i, (_, row) in enumerate(shuffle(pre_train_set, random_state=2022 + k).iterrows()):
|
| 181 |
+
model.train()
|
| 182 |
+
optimizer.zero_grad()
|
| 183 |
+
output_t = [(model.zero, model.zero)]
|
| 184 |
+
for input_t in row['tensor']:
|
| 185 |
+
output_t.append(model(input_t, *output_t[-1]))
|
| 186 |
+
loss = model.loss(output_t[-1][0], row['delta_t'],
|
| 187 |
+
{1: 0, 2: 1, 3: 1, 4: 1}[row['r']])
|
| 188 |
+
if np.isnan(loss.data.item()):
|
| 189 |
+
# Exception Case
|
| 190 |
+
print(row, output_t)
|
| 191 |
+
raise Exception('error case')
|
| 192 |
+
loss.backward()
|
| 193 |
+
optimizer.step()
|
| 194 |
+
model.apply(clipper)
|
| 195 |
+
pbar.update()
|
| 196 |
+
pbar.close()
|
| 197 |
+
for name, param in model.named_parameters():
|
| 198 |
+
print(f"{name}: {list(map(lambda x: round(float(x), 4), param))}")
|
| 199 |
+
|
| 200 |
+
train_set = dataset[dataset['i'] > 2]
|
| 201 |
+
epoch_len = len(train_set)
|
| 202 |
+
n_epoch = 1
|
| 203 |
+
print_len = max(epoch_len * n_epoch // 10, 1)
|
| 204 |
+
pbar = tqdm(desc="Training", total=epoch_len * n_epoch)
|
| 205 |
+
|
| 206 |
+
for k in range(n_epoch):
|
| 207 |
+
for i, (_, row) in enumerate(shuffle(train_set, random_state=2022 + k).iterrows()):
|
| 208 |
+
model.train()
|
| 209 |
+
optimizer.zero_grad()
|
| 210 |
+
output_t = [(model.zero, model.zero)]
|
| 211 |
+
for input_t in row['tensor']:
|
| 212 |
+
output_t.append(model(input_t, *output_t[-1]))
|
| 213 |
+
loss = model.loss(output_t[-1][0], row['delta_t'],
|
| 214 |
+
{1: 0, 2: 1, 3: 1, 4: 1}[row['r']])
|
| 215 |
+
if np.isnan(loss.data.item()):
|
| 216 |
+
# Exception Case
|
| 217 |
+
print(row, output_t)
|
| 218 |
+
raise Exception('error case')
|
| 219 |
+
loss.backward()
|
| 220 |
+
for param in model.parameters():
|
| 221 |
+
param.grad[:2] = torch.zeros(2)
|
| 222 |
+
optimizer.step()
|
| 223 |
+
model.apply(clipper)
|
| 224 |
+
pbar.update()
|
| 225 |
+
|
| 226 |
+
if (k * epoch_len + i) % print_len == 0:
|
| 227 |
+
print(f"iteration: {k * epoch_len + i + 1}")
|
| 228 |
+
for name, param in model.named_parameters():
|
| 229 |
+
print(f"{name}: {list(map(lambda x: round(float(x), 4), param))}")
|
| 230 |
+
pbar.close()
|
| 231 |
+
|
| 232 |
+
w = list(map(lambda x: round(float(x), 4), dict(model.named_parameters())['w'].data))
|
| 233 |
+
|
| 234 |
+
print("\nTraining finished!")
|
| 235 |
+
return w, dataset
|
| 236 |
+
|
| 237 |
+
|
| 238 |
+
def process_personalized_collection(requestRetention, w):
|
| 239 |
+
my_collection = Collection(w)
|
| 240 |
+
rating_dict = {1: "again", 2: "hard", 3: "good", 4: "easy"}
|
| 241 |
+
rating_markdown = []
|
| 242 |
+
for first_rating in (1, 2, 3, 4):
|
| 243 |
+
rating_markdown.append(f'## First Rating: {first_rating} ({rating_dict[first_rating]})')
|
| 244 |
+
t_history = "0"
|
| 245 |
+
d_history = "0"
|
| 246 |
+
r_history = f"{first_rating}" # the first rating of the new card
|
| 247 |
+
# print("stability, difficulty, lapses")
|
| 248 |
+
for i in range(10):
|
| 249 |
+
states = my_collection.states(t_history, r_history)
|
| 250 |
+
# print('{0:9.2f} {1:11.2f} {2:7.0f}'.format(
|
| 251 |
+
# *list(map(lambda x: round(float(x), 4), states))))
|
| 252 |
+
next_t = max(round(float(np.log(requestRetention) / np.log(0.9) * states[0])), 1)
|
| 253 |
+
difficulty = round(float(states[1]), 1)
|
| 254 |
+
t_history += f',{int(next_t)}'
|
| 255 |
+
d_history += f',{difficulty}'
|
| 256 |
+
r_history += f",3"
|
| 257 |
+
rating_markdown.append(f"*rating history*: {r_history}")
|
| 258 |
+
rating_markdown.append(f"*interval history*: {t_history}")
|
| 259 |
+
rating_markdown.append(f"*difficulty history*: {d_history}\n")
|
| 260 |
+
rating_markdown = '\n\n'.join(rating_markdown)
|
| 261 |
+
return my_collection, rating_markdown
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
def log_loss(my_collection, row):
|
| 265 |
+
states = my_collection.states(row['t_history'], row['r_history'])
|
| 266 |
+
row['log_loss'] = float(my_collection.model.loss(states[0], row['delta_t'], {1: 0, 2: 1, 3: 1, 4: 1}[row['r']]))
|
| 267 |
+
return row
|
| 268 |
+
|
| 269 |
+
|
| 270 |
+
def my_loss(dataset, w):
|
| 271 |
+
my_collection = Collection(init_w)
|
| 272 |
+
tqdm.pandas(desc='Calculating Loss before Training')
|
| 273 |
+
dataset = dataset.progress_apply(partial(log_loss, my_collection), axis=1)
|
| 274 |
+
print(f"Loss before training: {dataset['log_loss'].mean():.4f}")
|
| 275 |
+
my_collection = Collection(w)
|
| 276 |
+
tqdm.pandas(desc='Calculating Loss After Training')
|
| 277 |
+
dataset = dataset.progress_apply(partial(log_loss, my_collection), axis=1)
|
| 278 |
+
print(f"Loss after training: {dataset['log_loss'].mean():.4f}")
|
| 279 |
+
return f"""
|
| 280 |
+
*Loss before training*: {dataset['log_loss'].mean():.4f}
|
| 281 |
+
|
| 282 |
+
*Loss after training*: {dataset['log_loss'].mean():.4f}
|
| 283 |
+
"""
|
| 284 |
+
|
| 285 |
+
|
| 286 |
+
def cleanup(proj_dir: Path, files):
|
| 287 |
+
"""
|
| 288 |
+
Delete all files in prefix that dont have filenames in files
|
| 289 |
+
:param proj_dir:
|
| 290 |
+
:param files:
|
| 291 |
+
:return:
|
| 292 |
+
"""
|
| 293 |
+
for file in proj_dir.glob('*'):
|
| 294 |
+
if file.name not in files:
|
| 295 |
+
os.remove(file)
|
| 296 |
+
|