Spaces:
Build error

Build error
File size: 4,809 Bytes
c16e8d3 279a80e 2bb501c 279a80e c16e8d3 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 |
---
title: Relate Anything
emoji: 👁
colorFrom: green
colorTo: red
sdk: gradio
sdk_version: 3.27.0
app_file: app.py
pinned: false
license: mit
---
<p align="center" width="100%">
<img src="assets/ram_logo.png" width="60%" height="30%">
</p>
# RAM: Relate-Anything-Model
The following developers have equally contributed to this project in their spare time, the names are in alphabetical order.
[Zujin Guo](https://scholar.google.com/citations?user=G8DPsoUAAAAJ&hl=zh-CN),
[Bo Li](https://brianboli.com/),
[Jingkang Yang](https://jingkang50.github.io/),
[Zijian Zhou](https://sites.google.com/view/zijian-zhou/home).
**Affiliate: [MMLab@NTU](https://www.mmlab-ntu.com/)** & **[VisCom Lab, KCL/TongJi](https://viscom.nms.kcl.ac.uk/)**
---
🚀 🚀 🚀 This is a demo that combine Meta's [Segment-Anything](https://segment-anything.com/) model with the ECCV'22 paper: [Panoptic Scene Graph Generation](https://psgdataset.org/).
🔥🔥🔥 Please star our codebase [OpenPSG](https://github.com/Jingkang50/OpenPSG) and [RAM](https://github.com/Luodian/RelateAnything) if you find it useful/interesting.
[[`Huggingface Demo`](#method)]
[[`Dataset`](https://psgdataset.org/)]
Relate Anything Model is capable of taking an image as input and utilizing SAM to identify the corresponding mask within the image. Subsequently, RAM can provide an analysis of the relationship between any arbitrary objects mask.
The object masks are generated using SAM. RAM was trained to detect the relationships between the object masks using the OpenPSG dataset, and the specifics of this method are outlined in a subsequent section.
[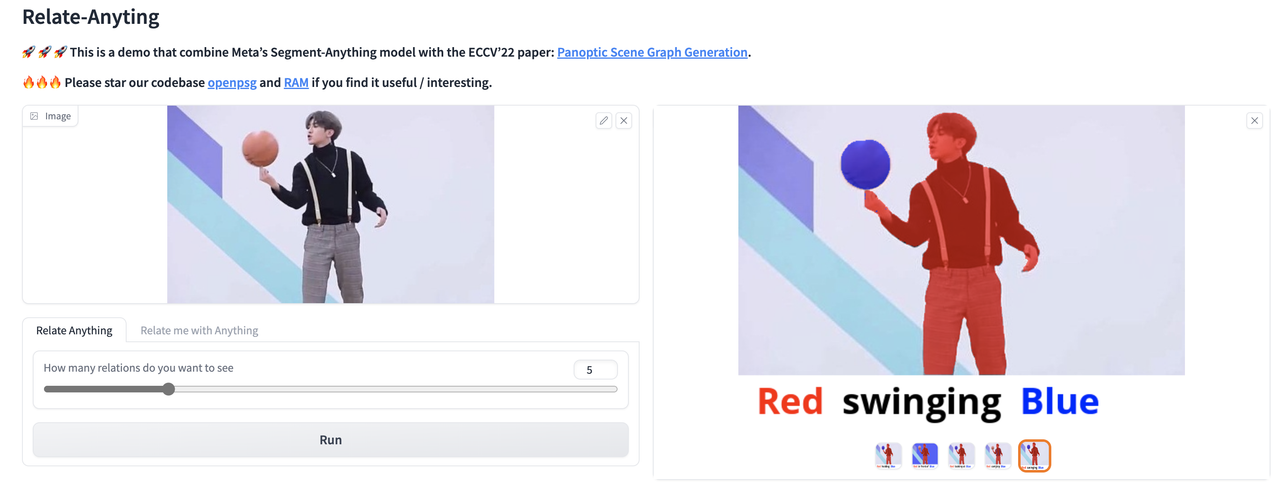](https://postimg.cc/k2HDRryV)
## Examples
Our current demo supports:
(1) generate arbitary objects masks and reason relationships in between.
(2) given coordinates then generate object masks and reason the relationship between given objects and other objects in the image.
We will soon add support for detecting semantic labels of objects with the help of [OVSeg](https://github.com/facebookresearch/ov-seg).
Here are some examples of the Relate Anything Model in action about playing soccer, dancing, and playing basketball.
<!--  -->





## Method
RAM utilizes the Segment Anything Model (SAM) to accurately mask objects within an image, and subsequently extract features corresponding to the segmented regions. Employ a Transformer module to facilitate feature interaction among distinct objects, and ultimately compute pairwise object relationships, thereby categorizing their interrelations.
## Setup
To set up the environment, we use Conda to manage dependencies.
To specify the appropriate version of cudatoolkit to install on your machine, you can modify the environment.yml file, and then create the Conda environment by running the following command:
```bash
conda env create -f environment.yml
```
Make sure to use `segment_anything` in this repository, which includes the mask feature extraction operation.
Download the pretrained model
1. SAM: [link](https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth)
2. RAM: [link](https://1drv.ms/u/s!AgCc-d5Aw1cumQapZwcaKob8InQm?e=qyMeTS)
Place these two models in `./checkpoints/` from the root directory.
Run our demo locally by running the following command:
```bash
python app.py
```
<!-- ## Developers
We have equally contributed to this project in our spare time, in alphabetical order.
[Zujin Guo](https://scholar.google.com/citations?user=G8DPsoUAAAAJ&hl=zh-CN),
[Bo Li](https://brianboli.com/),
[Jingkang Yang](https://jingkang50.github.io/),
[Zijian Zhou](https://sites.google.com/view/zijian-zhou/home).
**[MMLab@NTU](https://www.mmlab-ntu.com/)** & **[VisCom Lab, KCL](https://viscom.nms.kcl.ac.uk/)** -->
## Acknowledgement
We thank [Chunyuan Li](https://chunyuan.li/) for his help in setting up the demo.
## Citation
If you find this project helpful for your research, please consider citing the following BibTeX entry.
```BibTex
@inproceedings{yang2022psg,
author = {Yang, Jingkang and Ang, Yi Zhe and Guo, Zujin and Zhou, Kaiyang and Zhang, Wayne and Liu, Ziwei},
title = {Panoptic Scene Graph Generation},
booktitle = {ECCV}
year = {2022}
}
@inproceedings{yang2023pvsg,
author = {Yang, Jingkang and Peng, Wenxuan and Li, Xiangtai and Guo, Zujin and Chen, Liangyu and Li, Bo and Ma, Zheng and Zhou, Kaiyang and Zhang, Wayne and Loy, Chen Change and Liu, Ziwei},
title = {Panoptic Video Scene Graph Generation},
booktitle = {CVPR},
year = {2023},
}
``` |