Spaces:
Build error

Build error

Add application file
Browse files- .gitattributes +1 -0
- .gitignore +14 -0
- LICENSE +201 -0
- README.md +111 -11
- app.py +295 -0
- assets/OpenSans-Bold.ttf +0 -0
- assets/basketball.gif +0 -0
- assets/basketball.png +3 -0
- assets/dog.jpg +0 -0
- assets/ram.png +3 -0
- assets/ram_logo.png +3 -0
- assets/soccer.png +3 -0
- environment.yml +16 -0
- ram_train_eval.py +417 -0
- segment_anything/__init__.py +15 -0
- segment_anything/automatic_mask_generator.py +374 -0
- segment_anything/build_sam.py +107 -0
- segment_anything/modeling/__init__.py +11 -0
- segment_anything/modeling/common.py +43 -0
- segment_anything/modeling/image_encoder.py +395 -0
- segment_anything/modeling/mask_decoder.py +177 -0
- segment_anything/modeling/prompt_encoder.py +214 -0
- segment_anything/modeling/sam.py +175 -0
- segment_anything/modeling/transformer.py +240 -0
- segment_anything/predictor.py +269 -0
- segment_anything/utils/__init__.py +5 -0
- segment_anything/utils/amg.py +346 -0
- segment_anything/utils/onnx.py +144 -0
- segment_anything/utils/transforms.py +102 -0
- utils.py +152 -0
.gitattributes
CHANGED
|
@@ -32,3 +32,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*.png filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.h
|
| 2 |
+
*.cpp
|
| 3 |
+
*.o
|
| 4 |
+
*.so
|
| 5 |
+
*.pyc
|
| 6 |
+
*.pth
|
| 7 |
+
.vscode/*
|
| 8 |
+
|
| 9 |
+
.ipynb_checkpoints/
|
| 10 |
+
data
|
| 11 |
+
feats/
|
| 12 |
+
*.npz
|
| 13 |
+
share/
|
| 14 |
+
|
LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright 2020 - present, Facebook, Inc
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
README.md
CHANGED
|
@@ -1,13 +1,113 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
-
title: Relate Anything
|
| 3 |
-
emoji: 📈
|
| 4 |
-
colorFrom: green
|
| 5 |
-
colorTo: red
|
| 6 |
-
sdk: gradio
|
| 7 |
-
sdk_version: 3.27.0
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
-
license: mit
|
| 11 |
-
---
|
| 12 |
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<p align="center" width="100%">
|
| 2 |
+
<img src="assets/ram_logo.png" width="60%" height="30%">
|
| 3 |
+
</p>
|
| 4 |
+
|
| 5 |
+
# RAM: Relate-Anything-Model
|
| 6 |
+
|
| 7 |
+
The following developers have equally contributed to this project in their spare time, the names are in alphabetical order.
|
| 8 |
+
|
| 9 |
+
[Zujin Guo](https://scholar.google.com/citations?user=G8DPsoUAAAAJ&hl=zh-CN),
|
| 10 |
+
[Bo Li](https://brianboli.com/),
|
| 11 |
+
[Jingkang Yang](https://jingkang50.github.io/),
|
| 12 |
+
[Zijian Zhou](https://sites.google.com/view/zijian-zhou/home).
|
| 13 |
+
|
| 14 |
+
**Affiliate: [MMLab@NTU](https://www.mmlab-ntu.com/)** & **[VisCom Lab, KCL/TongJi](https://viscom.nms.kcl.ac.uk/)**
|
| 15 |
+
|
| 16 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 17 |
|
| 18 |
+
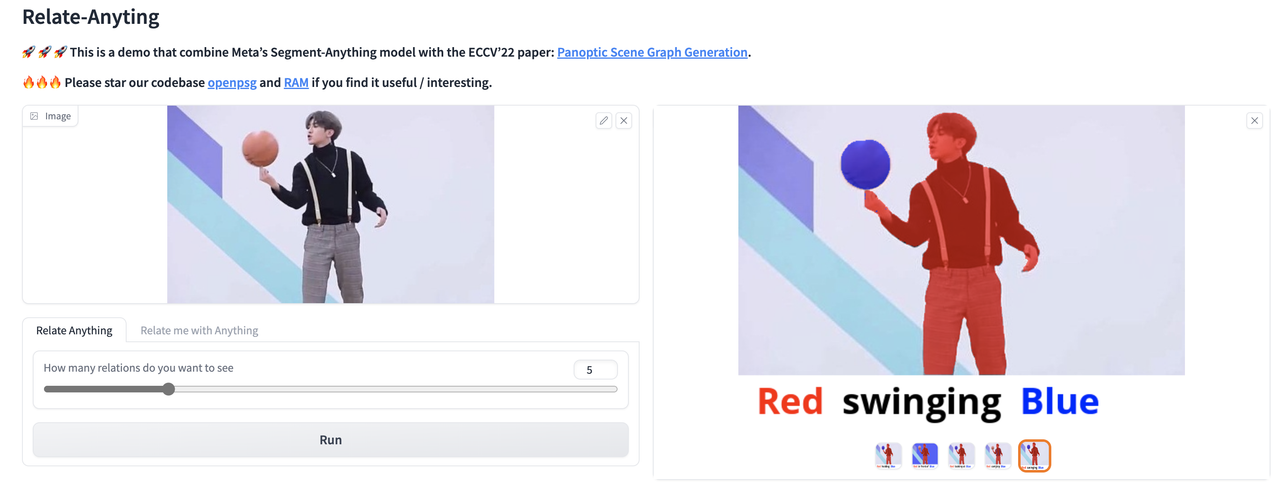
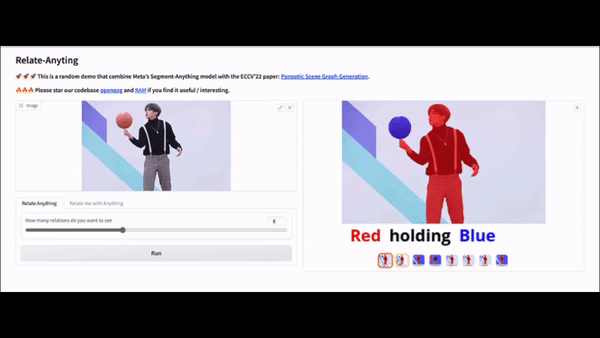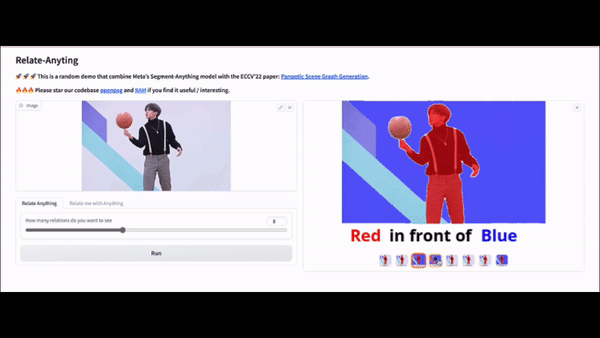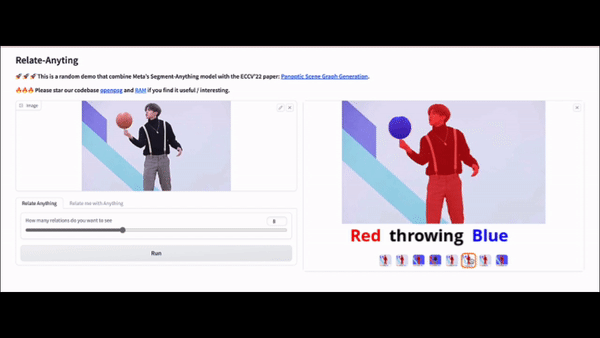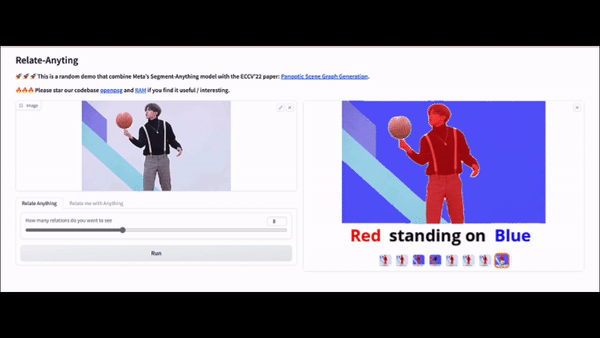
🚀 🚀 🚀 This is a demo that combine Meta's [Segment-Anything](https://segment-anything.com/) model with the ECCV'22 paper: [Panoptic Scene Graph Generation](https://psgdataset.org/).
|
| 19 |
+
|
| 20 |
+
🔥🔥🔥 Please star our codebase [OpenPSG](https://github.com/Jingkang50/OpenPSG) and [RAM](https://github.com/Luodian/RelateAnything) if you find it useful/interesting.
|
| 21 |
+
|
| 22 |
+
[[`Huggingface Demo`](#method)]
|
| 23 |
+
|
| 24 |
+
[[`Dataset`](https://psgdataset.org/)]
|
| 25 |
+
|
| 26 |
+
Relate Anything Model is capable of taking an image as input and utilizing SAM to identify the corresponding mask within the image. Subsequently, RAM can provide an analysis of the relationship between any arbitrary objects mask.
|
| 27 |
+
|
| 28 |
+
The object masks are generated using SAM. RAM was trained to detect the relationships between the object masks using the OpenPSG dataset, and the specifics of this method are outlined in a subsequent section.
|
| 29 |
+
|
| 30 |
+
[](https://postimg.cc/k2HDRryV)
|
| 31 |
+
|
| 32 |
+
## Examples
|
| 33 |
+
|
| 34 |
+
Our current demo supports:
|
| 35 |
+
|
| 36 |
+
(1) generate arbitary objects masks and reason relationships in between.
|
| 37 |
+
|
| 38 |
+
(2) given coordinates then generate object masks and reason the relationship between given objects and other objects in the image.
|
| 39 |
+
|
| 40 |
+
We will soon add support for detecting semantic labels of objects with the help of [OVSeg](https://github.com/facebookresearch/ov-seg).
|
| 41 |
+
|
| 42 |
+
Here are some examples of the Relate Anything Model in action about playing soccer, dancing, and playing basketball.
|
| 43 |
+
|
| 44 |
+
<!--  -->
|
| 45 |
+
|
| 46 |
+

|
| 47 |
+
|
| 48 |
+

|
| 49 |
+
|
| 50 |
+

|
| 51 |
+
|
| 52 |
+

|
| 53 |
+
|
| 54 |
+

|
| 55 |
+
|
| 56 |
+
## Method
|
| 57 |
+
|
| 58 |
+
RAM utilizes the Segment Anything Model (SAM) to accurately mask objects within an image, and subsequently extract features corresponding to the segmented regions. Employ a Transformer module to facilitate feature interaction among distinct objects, and ultimately compute pairwise object relationships, thereby categorizing their interrelations.
|
| 59 |
+
|
| 60 |
+
## Setup
|
| 61 |
+
|
| 62 |
+
To set up the environment, we use Conda to manage dependencies.
|
| 63 |
+
To specify the appropriate version of cudatoolkit to install on your machine, you can modify the environment.yml file, and then create the Conda environment by running the following command:
|
| 64 |
+
|
| 65 |
+
```bash
|
| 66 |
+
conda env create -f environment.yml
|
| 67 |
+
```
|
| 68 |
+
|
| 69 |
+
Make sure to use `segment_anything` in this repository, which includes the mask feature extraction operation.
|
| 70 |
+
|
| 71 |
+
Download the pretrained model
|
| 72 |
+
1. SAM: [link](https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth)
|
| 73 |
+
2. RAM: [link](https://1drv.ms/u/s!AgCc-d5Aw1cumQapZwcaKob8InQm?e=qyMeTS)
|
| 74 |
+
|
| 75 |
+
Place these two models in `./checkpoints/` from the root directory.
|
| 76 |
+
|
| 77 |
+
Run our demo locally by running the following command:
|
| 78 |
+
|
| 79 |
+
```bash
|
| 80 |
+
python app.py
|
| 81 |
+
```
|
| 82 |
+
|
| 83 |
+
<!-- ## Developers
|
| 84 |
+
|
| 85 |
+
We have equally contributed to this project in our spare time, in alphabetical order.
|
| 86 |
+
[Zujin Guo](https://scholar.google.com/citations?user=G8DPsoUAAAAJ&hl=zh-CN),
|
| 87 |
+
[Bo Li](https://brianboli.com/),
|
| 88 |
+
[Jingkang Yang](https://jingkang50.github.io/),
|
| 89 |
+
[Zijian Zhou](https://sites.google.com/view/zijian-zhou/home).
|
| 90 |
+
|
| 91 |
+
**[MMLab@NTU](https://www.mmlab-ntu.com/)** & **[VisCom Lab, KCL](https://viscom.nms.kcl.ac.uk/)** -->
|
| 92 |
+
|
| 93 |
+
## Acknowledgement
|
| 94 |
+
|
| 95 |
+
We thank [Chunyuan Li](https://chunyuan.li/) for his help in setting up the demo.
|
| 96 |
+
|
| 97 |
+
## Citation
|
| 98 |
+
If you find this project helpful for your research, please consider citing the following BibTeX entry.
|
| 99 |
+
```BibTex
|
| 100 |
+
@inproceedings{yang2022psg,
|
| 101 |
+
author = {Yang, Jingkang and Ang, Yi Zhe and Guo, Zujin and Zhou, Kaiyang and Zhang, Wayne and Liu, Ziwei},
|
| 102 |
+
title = {Panoptic Scene Graph Generation},
|
| 103 |
+
booktitle = {ECCV}
|
| 104 |
+
year = {2022}
|
| 105 |
+
}
|
| 106 |
+
|
| 107 |
+
@inproceedings{yang2023pvsg,
|
| 108 |
+
author = {Yang, Jingkang and Peng, Wenxuan and Li, Xiangtai and Guo, Zujin and Chen, Liangyu and Li, Bo and Ma, Zheng and Zhou, Kaiyang and Zhang, Wayne and Loy, Chen Change and Liu, Ziwei},
|
| 109 |
+
title = {Panoptic Video Scene Graph Generation},
|
| 110 |
+
booktitle = {CVPR},
|
| 111 |
+
year = {2023},
|
| 112 |
+
}
|
| 113 |
+
```
|
app.py
ADDED
|
@@ -0,0 +1,295 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
sys.path.append('.')
|
| 3 |
+
|
| 4 |
+
from segment_anything import build_sam, SamPredictor, SamAutomaticMaskGenerator
|
| 5 |
+
import numpy as np
|
| 6 |
+
import gradio as gr
|
| 7 |
+
from PIL import Image, ImageDraw, ImageFont
|
| 8 |
+
from utils import iou, sort_and_deduplicate, relation_classes, MLP, show_anns, show_mask
|
| 9 |
+
import torch
|
| 10 |
+
|
| 11 |
+
from ram_train_eval import RamModel,RamPredictor
|
| 12 |
+
from mmengine.config import Config
|
| 13 |
+
|
| 14 |
+
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
| 15 |
+
|
| 16 |
+
input_size = 512
|
| 17 |
+
hidden_size = 256
|
| 18 |
+
num_classes = 56
|
| 19 |
+
|
| 20 |
+
# load sam model
|
| 21 |
+
sam = build_sam(checkpoint="./checkpoints/sam_vit_h_4b8939.pth").to(device)
|
| 22 |
+
predictor = SamPredictor(sam)
|
| 23 |
+
mask_generator = SamAutomaticMaskGenerator(sam)
|
| 24 |
+
|
| 25 |
+
# load ram model
|
| 26 |
+
model_path = "./checkpoints/ram_epoch12.pth"
|
| 27 |
+
config = dict(
|
| 28 |
+
model=dict(
|
| 29 |
+
pretrained_model_name_or_path='bert-base-uncased',
|
| 30 |
+
load_pretrained_weights=False,
|
| 31 |
+
num_transformer_layer=2,
|
| 32 |
+
input_feature_size=256,
|
| 33 |
+
output_feature_size=768,
|
| 34 |
+
cls_feature_size=512,
|
| 35 |
+
num_relation_classes=56,
|
| 36 |
+
pred_type='attention',
|
| 37 |
+
loss_type='multi_label_ce',
|
| 38 |
+
),
|
| 39 |
+
load_from=model_path,
|
| 40 |
+
)
|
| 41 |
+
config = Config(config)
|
| 42 |
+
|
| 43 |
+
class Predictor(RamPredictor):
|
| 44 |
+
def __init__(self,config):
|
| 45 |
+
self.config = config
|
| 46 |
+
self.device = torch.device(
|
| 47 |
+
'cuda' if torch.cuda.is_available() else 'cpu')
|
| 48 |
+
self._build_model()
|
| 49 |
+
|
| 50 |
+
def _build_model(self):
|
| 51 |
+
self.model = RamModel(**self.config.model).to(self.device)
|
| 52 |
+
if self.config.load_from is not None:
|
| 53 |
+
self.model.load_state_dict(torch.load(self.config.load_from, map_location=self.device))
|
| 54 |
+
self.model.train()
|
| 55 |
+
|
| 56 |
+
model = Predictor(config)
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
# visualization
|
| 60 |
+
def draw_selected_mask(mask, draw):
|
| 61 |
+
color = (255, 0, 0, 153)
|
| 62 |
+
nonzero_coords = np.transpose(np.nonzero(mask))
|
| 63 |
+
for coord in nonzero_coords:
|
| 64 |
+
draw.point(coord[::-1], fill=color)
|
| 65 |
+
|
| 66 |
+
def draw_object_mask(mask, draw):
|
| 67 |
+
color = (0, 0, 255, 153)
|
| 68 |
+
nonzero_coords = np.transpose(np.nonzero(mask))
|
| 69 |
+
for coord in nonzero_coords:
|
| 70 |
+
draw.point(coord[::-1], fill=color)
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def vis_selected(pil_image, coords):
|
| 74 |
+
# get coords
|
| 75 |
+
coords_x, coords_y = coords.split(',')
|
| 76 |
+
input_point = np.array([[int(coords_x), int(coords_y)]])
|
| 77 |
+
input_label = np.array([1])
|
| 78 |
+
# load image
|
| 79 |
+
image = np.array(pil_image)
|
| 80 |
+
predictor.set_image(image)
|
| 81 |
+
mask1, score1, logit1, feat1 = predictor.predict(
|
| 82 |
+
point_coords=input_point,
|
| 83 |
+
point_labels=input_label,
|
| 84 |
+
multimask_output=False,
|
| 85 |
+
)
|
| 86 |
+
pil_image = pil_image.convert('RGBA')
|
| 87 |
+
mask_image = Image.new('RGBA', pil_image.size, color=(0, 0, 0, 0))
|
| 88 |
+
mask_draw = ImageDraw.Draw(mask_image)
|
| 89 |
+
draw_selected_mask(mask1[0], mask_draw)
|
| 90 |
+
pil_image.alpha_composite(mask_image)
|
| 91 |
+
|
| 92 |
+
yield [pil_image]
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
def create_title_image(word1, word2, word3, width, font_path='./assets/OpenSans-Bold.ttf'):
|
| 96 |
+
# Define the colors to use for each word
|
| 97 |
+
color_red = (255, 0, 0)
|
| 98 |
+
color_black = (0, 0, 0)
|
| 99 |
+
color_blue = (0, 0, 255)
|
| 100 |
+
|
| 101 |
+
# Define the initial font size and spacing between words
|
| 102 |
+
font_size = 40
|
| 103 |
+
|
| 104 |
+
# Create a new image with the specified width and white background
|
| 105 |
+
image = Image.new('RGB', (width, 60), (255, 255, 255))
|
| 106 |
+
|
| 107 |
+
# Load the specified font
|
| 108 |
+
font = ImageFont.truetype(font_path, font_size)
|
| 109 |
+
|
| 110 |
+
# Keep increasing the font size until all words fit within the desired width
|
| 111 |
+
while True:
|
| 112 |
+
# Create a draw object for the image
|
| 113 |
+
draw = ImageDraw.Draw(image)
|
| 114 |
+
|
| 115 |
+
word_spacing = font_size / 2
|
| 116 |
+
# Draw each word in the appropriate color
|
| 117 |
+
x_offset = word_spacing
|
| 118 |
+
draw.text((x_offset, 0), word1, color_red, font=font)
|
| 119 |
+
x_offset += font.getsize(word1)[0] + word_spacing
|
| 120 |
+
draw.text((x_offset, 0), word2, color_black, font=font)
|
| 121 |
+
x_offset += font.getsize(word2)[0] + word_spacing
|
| 122 |
+
draw.text((x_offset, 0), word3, color_blue, font=font)
|
| 123 |
+
|
| 124 |
+
word_sizes = [font.getsize(word) for word in [word1, word2, word3]]
|
| 125 |
+
total_width = sum([size[0] for size in word_sizes]) + word_spacing * 3
|
| 126 |
+
|
| 127 |
+
# Stop increasing font size if the image is within the desired width
|
| 128 |
+
if total_width <= width:
|
| 129 |
+
break
|
| 130 |
+
|
| 131 |
+
# Increase font size and reset the draw object
|
| 132 |
+
font_size -= 1
|
| 133 |
+
image = Image.new('RGB', (width, 50), (255, 255, 255))
|
| 134 |
+
font = ImageFont.truetype(font_path, font_size)
|
| 135 |
+
draw = None
|
| 136 |
+
|
| 137 |
+
return image
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
def concatenate_images_vertical(image1, image2):
|
| 141 |
+
# Get the dimensions of the two images
|
| 142 |
+
width1, height1 = image1.size
|
| 143 |
+
width2, height2 = image2.size
|
| 144 |
+
|
| 145 |
+
# Create a new image with the combined height and the maximum width
|
| 146 |
+
new_image = Image.new('RGBA', (max(width1, width2), height1 + height2))
|
| 147 |
+
|
| 148 |
+
# Paste the first image at the top of the new image
|
| 149 |
+
new_image.paste(image1, (0, 0))
|
| 150 |
+
|
| 151 |
+
# Paste the second image below the first image
|
| 152 |
+
new_image.paste(image2, (0, height1))
|
| 153 |
+
|
| 154 |
+
return new_image
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
def relate_selected(input_image, k, coords):
|
| 158 |
+
# load image
|
| 159 |
+
pil_image = input_image.convert('RGBA')
|
| 160 |
+
|
| 161 |
+
w, h = pil_image.size
|
| 162 |
+
if w > 800:
|
| 163 |
+
pil_image.thumbnail((800, 800*h/w))
|
| 164 |
+
input_image.thumbnail((800, 800*h/w))
|
| 165 |
+
coords = str(int(int(coords.split(',')[0]) * 800 / w)) + ',' + str(int(int(coords.split(',')[1]) * 800 / w))
|
| 166 |
+
|
| 167 |
+
image = np.array(input_image)
|
| 168 |
+
sam_masks = mask_generator.generate(image)
|
| 169 |
+
# get old mask
|
| 170 |
+
coords_x, coords_y = coords.split(',')
|
| 171 |
+
input_point = np.array([[int(coords_x), int(coords_y)]])
|
| 172 |
+
input_label = np.array([1])
|
| 173 |
+
mask1, score1, logit1, feat1 = predictor.predict(
|
| 174 |
+
point_coords=input_point,
|
| 175 |
+
point_labels=input_label,
|
| 176 |
+
multimask_output=False,
|
| 177 |
+
)
|
| 178 |
+
|
| 179 |
+
filtered_masks = sort_and_deduplicate(sam_masks)
|
| 180 |
+
filtered_masks = [d for d in sam_masks if iou(d['segmentation'], mask1[0]) < 0.95][:k]
|
| 181 |
+
pil_image_list = []
|
| 182 |
+
|
| 183 |
+
# run model
|
| 184 |
+
feat = feat1
|
| 185 |
+
for fm in filtered_masks:
|
| 186 |
+
feat2 = torch.Tensor(fm['feat']).unsqueeze(0).unsqueeze(0).to(device)
|
| 187 |
+
feat = torch.cat((feat, feat2), dim=1)
|
| 188 |
+
matrix_output, rel_triplets = model.predict(feat)
|
| 189 |
+
subject_output = matrix_output.permute([0,2,3,1])[:,0,1:]
|
| 190 |
+
|
| 191 |
+
for i in range(len(filtered_masks)):
|
| 192 |
+
|
| 193 |
+
output = subject_output[:,i]
|
| 194 |
+
|
| 195 |
+
topk_indices = torch.argsort(-output).flatten()
|
| 196 |
+
relation = relation_classes[topk_indices[:1][0]]
|
| 197 |
+
|
| 198 |
+
mask_image = Image.new('RGBA', pil_image.size, color=(0, 0, 0, 0))
|
| 199 |
+
mask_draw = ImageDraw.Draw(mask_image)
|
| 200 |
+
|
| 201 |
+
draw_selected_mask(mask1[0], mask_draw)
|
| 202 |
+
draw_object_mask(filtered_masks[i]['segmentation'], mask_draw)
|
| 203 |
+
|
| 204 |
+
current_pil_image = pil_image.copy()
|
| 205 |
+
current_pil_image.alpha_composite(mask_image)
|
| 206 |
+
|
| 207 |
+
title_image = create_title_image('Red', relation, 'Blue', current_pil_image.size[0])
|
| 208 |
+
concate_pil_image = concatenate_images_vertical(current_pil_image, title_image)
|
| 209 |
+
pil_image_list.append(concate_pil_image)
|
| 210 |
+
|
| 211 |
+
yield pil_image_list
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
def relate_anything(input_image, k):
|
| 215 |
+
# load image
|
| 216 |
+
pil_image = input_image.convert('RGBA')
|
| 217 |
+
w, h = pil_image.size
|
| 218 |
+
if w > 800:
|
| 219 |
+
pil_image.thumbnail((800, 800*h/w))
|
| 220 |
+
input_image.thumbnail((800, 800*h/w))
|
| 221 |
+
image = np.array(input_image)
|
| 222 |
+
sam_masks = mask_generator.generate(image)
|
| 223 |
+
filtered_masks = sort_and_deduplicate(sam_masks)
|
| 224 |
+
|
| 225 |
+
feat_list = []
|
| 226 |
+
for fm in filtered_masks:
|
| 227 |
+
feat = torch.Tensor(fm['feat']).unsqueeze(0).unsqueeze(0).to(device)
|
| 228 |
+
feat_list.append(feat)
|
| 229 |
+
feat = torch.cat(feat_list, dim=1).to(device)
|
| 230 |
+
matrix_output, rel_triplets = model.predict(feat)
|
| 231 |
+
|
| 232 |
+
pil_image_list = []
|
| 233 |
+
for i, rel in enumerate(rel_triplets[:k]):
|
| 234 |
+
s,o,r = int(rel[0]),int(rel[1]),int(rel[2])
|
| 235 |
+
relation = relation_classes[r]
|
| 236 |
+
|
| 237 |
+
mask_image = Image.new('RGBA', pil_image.size, color=(0, 0, 0, 0))
|
| 238 |
+
mask_draw = ImageDraw.Draw(mask_image)
|
| 239 |
+
|
| 240 |
+
draw_selected_mask(filtered_masks[s]['segmentation'], mask_draw)
|
| 241 |
+
draw_object_mask(filtered_masks[o]['segmentation'], mask_draw)
|
| 242 |
+
|
| 243 |
+
current_pil_image = pil_image.copy()
|
| 244 |
+
current_pil_image.alpha_composite(mask_image)
|
| 245 |
+
|
| 246 |
+
title_image = create_title_image('Red', relation, 'Blue', current_pil_image.size[0])
|
| 247 |
+
concate_pil_image = concatenate_images_vertical(current_pil_image, title_image)
|
| 248 |
+
pil_image_list.append(concate_pil_image)
|
| 249 |
+
|
| 250 |
+
yield pil_image_list
|
| 251 |
+
|
| 252 |
+
DESCRIPTION = '''# Relate-Anyting
|
| 253 |
+
|
| 254 |
+
### 🚀 🚀 🚀 This is a demo that combine Meta's Segment-Anything model with the ECCV'22 paper: [Panoptic Scene Graph Generation](https://psgdataset.org/).
|
| 255 |
+
|
| 256 |
+
### 🔥🔥🔥 Please star our codebase [openpsg](https://github.com/Jingkang50/OpenPSG) and [RAM](https://github.com/Luodian/RelateAnything) if you find it useful / interesting.
|
| 257 |
+
'''
|
| 258 |
+
|
| 259 |
+
block = gr.Blocks()
|
| 260 |
+
block = block.queue()
|
| 261 |
+
with block:
|
| 262 |
+
gr.Markdown(DESCRIPTION)
|
| 263 |
+
with gr.Row():
|
| 264 |
+
with gr.Column():
|
| 265 |
+
input_image = gr.Image(source="upload", type="pil", value="assets/dog.jpg")
|
| 266 |
+
|
| 267 |
+
with gr.Tab("Relate Anything"):
|
| 268 |
+
num_relation = gr.Slider(label="How many relations do you want to see", minimum=1, maximum=20, value=5, step=1)
|
| 269 |
+
relate_all_button = gr.Button(label="Relate Anything!")
|
| 270 |
+
|
| 271 |
+
with gr.Tab("Relate me with Anything"):
|
| 272 |
+
img_input_coords = gr.Textbox(label="Click anything to get input coords")
|
| 273 |
+
|
| 274 |
+
def select_handler(evt: gr.SelectData):
|
| 275 |
+
coords = evt.index
|
| 276 |
+
return f"{coords[0]},{coords[1]}"
|
| 277 |
+
|
| 278 |
+
input_image.select(select_handler, None, img_input_coords)
|
| 279 |
+
run_button_vis = gr.Button(label="Visualize the Select Thing")
|
| 280 |
+
selected_gallery = gr.Gallery(label="Selected Thing", show_label=True, elem_id="gallery").style(preview=True, grid=2, object_fit="scale-down")
|
| 281 |
+
|
| 282 |
+
k = gr.Slider(label="Number of things you want to relate", minimum=1, maximum=20, value=5, step=1)
|
| 283 |
+
relate_selected_button = gr.Button(value="Relate it with Anything", interactive=True)
|
| 284 |
+
|
| 285 |
+
with gr.Column():
|
| 286 |
+
image_gallery = gr.Gallery(label="Your Result", show_label=True, elem_id="gallery").style(preview=True, columns=5, object_fit="scale-down")
|
| 287 |
+
|
| 288 |
+
# relate anything
|
| 289 |
+
relate_all_button.click(fn=relate_anything, inputs=[input_image, num_relation], outputs=[image_gallery], show_progress=True, queue=True)
|
| 290 |
+
|
| 291 |
+
# relate selected
|
| 292 |
+
run_button_vis.click(fn=vis_selected, inputs=[input_image, img_input_coords], outputs=[selected_gallery], show_progress=True, queue=True)
|
| 293 |
+
relate_selected_button.click(fn=relate_selected, inputs=[input_image, k, img_input_coords], outputs=[image_gallery], show_progress=True, queue=True)
|
| 294 |
+
|
| 295 |
+
block.launch(debug=True, share=True)
|
assets/OpenSans-Bold.ttf
ADDED
|
Binary file (225 kB). View file
|
|
|
assets/basketball.gif
ADDED
|
assets/basketball.png
ADDED

|
Git LFS Details
|
assets/dog.jpg
ADDED

|
assets/ram.png
ADDED

|
Git LFS Details
|
assets/ram_logo.png
ADDED
|
|
Git LFS Details
|
assets/soccer.png
ADDED

|
Git LFS Details
|
environment.yml
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: relate_anything
|
| 2 |
+
channels:
|
| 3 |
+
- pytorch
|
| 4 |
+
- conda-forge
|
| 5 |
+
dependencies:
|
| 6 |
+
- python=3.8
|
| 7 |
+
- pytorch=1.7.0
|
| 8 |
+
- torchvision=0.8.0
|
| 9 |
+
- torchaudio==0.7.0
|
| 10 |
+
- cudatoolkit=10.1
|
| 11 |
+
- pip
|
| 12 |
+
- pip:
|
| 13 |
+
- openmim
|
| 14 |
+
- mmcv==2.0.0
|
| 15 |
+
- pre-commit
|
| 16 |
+
- git+https://github.com/Jingkang50/OpenPSG
|
ram_train_eval.py
ADDED
|
@@ -0,0 +1,417 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import time
|
| 3 |
+
from datetime import timedelta
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
import torch.nn.functional as F
|
| 8 |
+
|
| 9 |
+
from mmengine.config import Config
|
| 10 |
+
from mmengine.utils import ProgressBar
|
| 11 |
+
from transformers import AutoConfig, AutoModel
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class RamDataset(torch.utils.data.Dataset):
|
| 15 |
+
def __init__(self, data_path, is_train=True, num_relation_classes=56):
|
| 16 |
+
super().__init__()
|
| 17 |
+
self.num_relation_classes = num_relation_classes
|
| 18 |
+
data = np.load(data_path, allow_pickle=True)
|
| 19 |
+
self.samples = data["arr_0"]
|
| 20 |
+
sample_num = self.samples.size
|
| 21 |
+
self.sample_idx_list = []
|
| 22 |
+
for idx in range(sample_num):
|
| 23 |
+
if self.samples[idx]["is_train"] == is_train:
|
| 24 |
+
self.sample_idx_list.append(idx)
|
| 25 |
+
|
| 26 |
+
def __getitem__(self, idx):
|
| 27 |
+
sample = self.samples[self.sample_idx_list[idx]]
|
| 28 |
+
object_num = sample["feat"].shape[0]
|
| 29 |
+
embedding = torch.from_numpy(sample["feat"])
|
| 30 |
+
gt_rels = sample["relations"]
|
| 31 |
+
rel_target = self._get_target(object_num, gt_rels)
|
| 32 |
+
return embedding, rel_target, gt_rels
|
| 33 |
+
|
| 34 |
+
def __len__(self):
|
| 35 |
+
return len(self.sample_idx_list)
|
| 36 |
+
|
| 37 |
+
def _get_target(self, object_num, gt_rels):
|
| 38 |
+
rel_target = torch.zeros([self.num_relation_classes, object_num, object_num])
|
| 39 |
+
for ii, jj, cls_relationship in gt_rels:
|
| 40 |
+
rel_target[cls_relationship, ii, jj] = 1
|
| 41 |
+
return rel_target
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
class RamModel(nn.Module):
|
| 45 |
+
def __init__(
|
| 46 |
+
self,
|
| 47 |
+
pretrained_model_name_or_path,
|
| 48 |
+
load_pretrained_weights=True,
|
| 49 |
+
num_transformer_layer=2,
|
| 50 |
+
input_feature_size=256,
|
| 51 |
+
output_feature_size=768,
|
| 52 |
+
cls_feature_size=512,
|
| 53 |
+
num_relation_classes=56,
|
| 54 |
+
pred_type="attention",
|
| 55 |
+
loss_type="bce",
|
| 56 |
+
):
|
| 57 |
+
super().__init__()
|
| 58 |
+
# 0. config
|
| 59 |
+
self.cls_feature_size = cls_feature_size
|
| 60 |
+
self.num_relation_classes = num_relation_classes
|
| 61 |
+
self.pred_type = pred_type
|
| 62 |
+
self.loss_type = loss_type
|
| 63 |
+
|
| 64 |
+
# 1. fc input and output
|
| 65 |
+
self.fc_input = nn.Sequential(
|
| 66 |
+
nn.Linear(input_feature_size, output_feature_size),
|
| 67 |
+
nn.LayerNorm(output_feature_size),
|
| 68 |
+
)
|
| 69 |
+
self.fc_output = nn.Sequential(
|
| 70 |
+
nn.Linear(output_feature_size, output_feature_size),
|
| 71 |
+
nn.LayerNorm(output_feature_size),
|
| 72 |
+
)
|
| 73 |
+
# 2. transformer model
|
| 74 |
+
if load_pretrained_weights:
|
| 75 |
+
self.model = AutoModel.from_pretrained(pretrained_model_name_or_path)
|
| 76 |
+
else:
|
| 77 |
+
config = AutoConfig.from_pretrained(pretrained_model_name_or_path)
|
| 78 |
+
self.model = AutoModel.from_config(config)
|
| 79 |
+
if num_transformer_layer != "all" and isinstance(num_transformer_layer, int):
|
| 80 |
+
self.model.encoder.layer = self.model.encoder.layer[:num_transformer_layer]
|
| 81 |
+
# 3. predict head
|
| 82 |
+
self.cls_sub = nn.Linear(output_feature_size, cls_feature_size * num_relation_classes)
|
| 83 |
+
self.cls_obj = nn.Linear(output_feature_size, cls_feature_size * num_relation_classes)
|
| 84 |
+
# 4. loss
|
| 85 |
+
if self.loss_type == "bce":
|
| 86 |
+
self.bce_loss = nn.BCEWithLogitsLoss()
|
| 87 |
+
elif self.loss_type == "multi_label_ce":
|
| 88 |
+
print("Use Multi Label Cross Entropy Loss.")
|
| 89 |
+
|
| 90 |
+
def forward(self, embeds, attention_mask=None):
|
| 91 |
+
"""
|
| 92 |
+
embeds: (batch_size, token_num, feature_size)
|
| 93 |
+
attention_mask: (batch_size, token_num)
|
| 94 |
+
"""
|
| 95 |
+
# 1. fc input
|
| 96 |
+
embeds = self.fc_input(embeds)
|
| 97 |
+
# 2. transformer model
|
| 98 |
+
position_ids = torch.ones([1, embeds.shape[1]]).to(embeds.device).to(torch.long)
|
| 99 |
+
outputs = self.model.forward(inputs_embeds=embeds, attention_mask=attention_mask, position_ids=position_ids)
|
| 100 |
+
embeds = outputs["last_hidden_state"]
|
| 101 |
+
# 3. fc output
|
| 102 |
+
embeds = self.fc_output(embeds)
|
| 103 |
+
# 4. predict head
|
| 104 |
+
batch_size, token_num, feature_size = embeds.shape
|
| 105 |
+
sub_embeds = self.cls_sub(embeds).reshape([batch_size, token_num, self.num_relation_classes, self.cls_feature_size]).permute([0, 2, 1, 3])
|
| 106 |
+
obj_embeds = self.cls_obj(embeds).reshape([batch_size, token_num, self.num_relation_classes, self.cls_feature_size]).permute([0, 2, 1, 3])
|
| 107 |
+
if self.pred_type == "attention":
|
| 108 |
+
cls_pred = sub_embeds @ torch.transpose(obj_embeds, 2, 3) / self.cls_feature_size**0.5 # noqa
|
| 109 |
+
elif self.pred_type == "einsum":
|
| 110 |
+
cls_pred = torch.einsum("nrsc,nroc->nrso", sub_embeds, obj_embeds)
|
| 111 |
+
return cls_pred
|
| 112 |
+
|
| 113 |
+
def loss(self, pred, target, attention_mask):
|
| 114 |
+
loss_dict = dict()
|
| 115 |
+
batch_size, relation_num, _, _ = pred.shape
|
| 116 |
+
|
| 117 |
+
mask = torch.zeros_like(pred).to(pred.device)
|
| 118 |
+
for idx in range(batch_size):
|
| 119 |
+
n = torch.sum(attention_mask[idx]).to(torch.int)
|
| 120 |
+
mask[idx, :, :n, :n] = 1
|
| 121 |
+
pred = pred * mask - 9999 * (1 - mask)
|
| 122 |
+
|
| 123 |
+
if self.loss_type == "bce":
|
| 124 |
+
loss = self.bce_loss(pred, target)
|
| 125 |
+
elif self.loss_type == "multi_label_ce":
|
| 126 |
+
input_tensor = torch.permute(pred, (1, 0, 2, 3))
|
| 127 |
+
target_tensor = torch.permute(target, (1, 0, 2, 3))
|
| 128 |
+
input_tensor = pred.reshape([relation_num, -1])
|
| 129 |
+
target_tensor = target.reshape([relation_num, -1])
|
| 130 |
+
loss = self.multilabel_categorical_crossentropy(target_tensor, input_tensor)
|
| 131 |
+
weight = loss / loss.max()
|
| 132 |
+
loss = loss * weight
|
| 133 |
+
loss = loss.mean()
|
| 134 |
+
loss_dict["loss"] = loss
|
| 135 |
+
|
| 136 |
+
# running metric
|
| 137 |
+
recall_20 = get_recall_N(pred, target, object_num=20)
|
| 138 |
+
loss_dict["recall@20"] = recall_20
|
| 139 |
+
return loss_dict
|
| 140 |
+
|
| 141 |
+
def multilabel_categorical_crossentropy(self, y_true, y_pred):
|
| 142 |
+
"""
|
| 143 |
+
https://kexue.fm/archives/7359
|
| 144 |
+
"""
|
| 145 |
+
y_pred = (1 - 2 * y_true) * y_pred
|
| 146 |
+
y_pred_neg = y_pred - y_true * 9999
|
| 147 |
+
y_pred_pos = y_pred - (1 - y_true) * 9999
|
| 148 |
+
zeros = torch.zeros_like(y_pred[..., :1])
|
| 149 |
+
y_pred_neg = torch.cat([y_pred_neg, zeros], dim=-1)
|
| 150 |
+
y_pred_pos = torch.cat([y_pred_pos, zeros], dim=-1)
|
| 151 |
+
neg_loss = torch.logsumexp(y_pred_neg, dim=-1)
|
| 152 |
+
pos_loss = torch.logsumexp(y_pred_pos, dim=-1)
|
| 153 |
+
return neg_loss + pos_loss
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
def get_recall_N(y_pred, y_true, object_num=20):
|
| 157 |
+
"""
|
| 158 |
+
y_pred: [batch_size, 56, object_num, object_num]
|
| 159 |
+
y_true: [batch_size, 56, object_num, object_num]
|
| 160 |
+
"""
|
| 161 |
+
|
| 162 |
+
device = y_pred.device
|
| 163 |
+
recall_list = []
|
| 164 |
+
|
| 165 |
+
for idx in range(len(y_true)):
|
| 166 |
+
sample_y_true = []
|
| 167 |
+
sample_y_pred = []
|
| 168 |
+
|
| 169 |
+
# find topk
|
| 170 |
+
_, topk_indices = torch.topk(
|
| 171 |
+
y_true[idx : idx + 1].reshape(
|
| 172 |
+
[
|
| 173 |
+
-1,
|
| 174 |
+
]
|
| 175 |
+
),
|
| 176 |
+
k=object_num,
|
| 177 |
+
)
|
| 178 |
+
for index in topk_indices:
|
| 179 |
+
pred_cls = index // (y_true.shape[2] ** 2)
|
| 180 |
+
index_subject_object = index % (y_true.shape[2] ** 2)
|
| 181 |
+
pred_subject = index_subject_object // y_true.shape[2]
|
| 182 |
+
pred_object = index_subject_object % y_true.shape[2]
|
| 183 |
+
if y_true[idx, pred_cls, pred_subject, pred_object] == 0:
|
| 184 |
+
continue
|
| 185 |
+
sample_y_true.append([pred_subject, pred_object, pred_cls])
|
| 186 |
+
|
| 187 |
+
# find topk
|
| 188 |
+
_, topk_indices = torch.topk(
|
| 189 |
+
y_pred[idx : idx + 1].reshape(
|
| 190 |
+
[
|
| 191 |
+
-1,
|
| 192 |
+
]
|
| 193 |
+
),
|
| 194 |
+
k=object_num,
|
| 195 |
+
)
|
| 196 |
+
for index in topk_indices:
|
| 197 |
+
pred_cls = index // (y_pred.shape[2] ** 2)
|
| 198 |
+
index_subject_object = index % (y_pred.shape[2] ** 2)
|
| 199 |
+
pred_subject = index_subject_object // y_pred.shape[2]
|
| 200 |
+
pred_object = index_subject_object % y_pred.shape[2]
|
| 201 |
+
sample_y_pred.append([pred_subject, pred_object, pred_cls])
|
| 202 |
+
|
| 203 |
+
recall = len([x for x in sample_y_pred if x in sample_y_true]) / (len(sample_y_true) + 1e-8)
|
| 204 |
+
recall_list.append(recall)
|
| 205 |
+
|
| 206 |
+
recall = torch.tensor(recall_list).to(device).mean() * 100
|
| 207 |
+
return recall
|
| 208 |
+
|
| 209 |
+
|
| 210 |
+
class RamTrainer(object):
|
| 211 |
+
def __init__(self, config):
|
| 212 |
+
self.config = config
|
| 213 |
+
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 214 |
+
self._build_dataset()
|
| 215 |
+
self._build_dataloader()
|
| 216 |
+
self._build_model()
|
| 217 |
+
self._build_optimizer()
|
| 218 |
+
self._build_lr_scheduler()
|
| 219 |
+
|
| 220 |
+
def _build_dataset(self):
|
| 221 |
+
self.dataset = RamDataset(**self.config.dataset)
|
| 222 |
+
|
| 223 |
+
def _build_dataloader(self):
|
| 224 |
+
self.dataloader = torch.utils.data.DataLoader(
|
| 225 |
+
self.dataset,
|
| 226 |
+
batch_size=self.config.dataloader.batch_size,
|
| 227 |
+
shuffle=True if self.config.dataset.is_train else False,
|
| 228 |
+
)
|
| 229 |
+
|
| 230 |
+
def _build_model(self):
|
| 231 |
+
self.model = RamModel(**self.config.model).to(self.device)
|
| 232 |
+
if self.config.load_from is not None:
|
| 233 |
+
self.model.load_state_dict(torch.load(self.config.load_from))
|
| 234 |
+
self.model.train()
|
| 235 |
+
|
| 236 |
+
def _build_optimizer(self):
|
| 237 |
+
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=self.config.optim.lr, weight_decay=self.config.optim.weight_decay, eps=self.config.optim.eps, betas=self.config.optim.betas)
|
| 238 |
+
|
| 239 |
+
def _build_lr_scheduler(self):
|
| 240 |
+
self.lr_scheduler = torch.optim.lr_scheduler.MultiStepLR(self.optimizer, milestones=self.config.optim.lr_scheduler.step, gamma=self.config.optim.lr_scheduler.gamma)
|
| 241 |
+
|
| 242 |
+
def train(self):
|
| 243 |
+
t_start = time.time()
|
| 244 |
+
running_avg_loss = 0
|
| 245 |
+
for epoch_idx in range(self.config.num_epoch):
|
| 246 |
+
for batch_idx, batch_data in enumerate(self.dataloader):
|
| 247 |
+
batch_embeds = batch_data[0].to(torch.float32).to(self.device)
|
| 248 |
+
batch_target = batch_data[1].to(torch.float32).to(self.device)
|
| 249 |
+
attention_mask = batch_embeds.new_ones((batch_embeds.shape[0], batch_embeds.shape[1]))
|
| 250 |
+
batch_pred = self.model.forward(batch_embeds, attention_mask)
|
| 251 |
+
loss_dict = self.model.loss(batch_pred, batch_target, attention_mask)
|
| 252 |
+
loss = loss_dict["loss"]
|
| 253 |
+
recall_20 = loss_dict["recall@20"]
|
| 254 |
+
self.optimizer.zero_grad()
|
| 255 |
+
loss.backward()
|
| 256 |
+
torch.nn.utils.clip_grad_norm_(self.model.parameters(), self.config.optim.max_norm, self.config.optim.norm_type)
|
| 257 |
+
self.optimizer.step()
|
| 258 |
+
running_avg_loss += loss.item()
|
| 259 |
+
|
| 260 |
+
if batch_idx % 100 == 0:
|
| 261 |
+
t_current = time.time()
|
| 262 |
+
num_finished_step = epoch_idx * self.config.num_epoch * len(self.dataloader) + batch_idx + 1
|
| 263 |
+
num_to_do_step = (self.config.num_epoch - epoch_idx - 1) * len(self.dataloader) + (len(self.dataloader) - batch_idx - 1)
|
| 264 |
+
avg_speed = num_finished_step / (t_current - t_start)
|
| 265 |
+
eta = num_to_do_step / avg_speed
|
| 266 |
+
print(
|
| 267 |
+
"ETA={:0>8}, Epoch={}, Batch={}/{}, LR={}, Loss={:.4f}, RunningAvgLoss={:.4f}, Recall@20={:.2f}%".format(
|
| 268 |
+
str(timedelta(seconds=int(eta))), epoch_idx + 1, batch_idx, len(self.dataloader), self.lr_scheduler.get_last_lr()[0], loss.item(), running_avg_loss / num_finished_step, recall_20.item()
|
| 269 |
+
)
|
| 270 |
+
)
|
| 271 |
+
self.lr_scheduler.step()
|
| 272 |
+
if not os.path.exists(self.config.output_dir):
|
| 273 |
+
os.makedirs(self.config.output_dir)
|
| 274 |
+
save_path = os.path.join(self.config.output_dir, "epoch_{}.pth".format(epoch_idx + 1))
|
| 275 |
+
print("Save epoch={} checkpoint to {}".format(epoch_idx + 1, save_path))
|
| 276 |
+
torch.save(self.model.state_dict(), save_path)
|
| 277 |
+
return save_path
|
| 278 |
+
|
| 279 |
+
|
| 280 |
+
class RamPredictor(object):
|
| 281 |
+
def __init__(self, config):
|
| 282 |
+
self.config = config
|
| 283 |
+
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 284 |
+
self._build_dataset()
|
| 285 |
+
self._build_dataloader()
|
| 286 |
+
self._build_model()
|
| 287 |
+
|
| 288 |
+
def _build_dataset(self):
|
| 289 |
+
self.dataset = RamDataset(**self.config.dataset)
|
| 290 |
+
|
| 291 |
+
def _build_dataloader(self):
|
| 292 |
+
self.dataloader = torch.utils.data.DataLoader(self.dataset, batch_size=self.config.dataloader.batch_size, shuffle=False)
|
| 293 |
+
|
| 294 |
+
def _build_model(self):
|
| 295 |
+
self.model = RamModel(**self.config.model).to(self.device)
|
| 296 |
+
if self.config.load_from is not None:
|
| 297 |
+
self.model.load_state_dict(torch.load(self.config.load_from))
|
| 298 |
+
self.model.eval()
|
| 299 |
+
|
| 300 |
+
def predict(self, batch_embeds, pred_keep_num=100):
|
| 301 |
+
"""
|
| 302 |
+
Parameters
|
| 303 |
+
----------
|
| 304 |
+
batch_embeds: (batch_size=1, token_num, feature_size)
|
| 305 |
+
pred_keep_num: int
|
| 306 |
+
Returns
|
| 307 |
+
-------
|
| 308 |
+
batch_pred: (batch_size, relation_num, object_num, object_num)
|
| 309 |
+
pred_rels: [[sub_id, obj_id, rel_id], ...]
|
| 310 |
+
"""
|
| 311 |
+
if not isinstance(batch_embeds, torch.Tensor):
|
| 312 |
+
batch_embeds = torch.asarray(batch_embeds)
|
| 313 |
+
batch_embeds = batch_embeds.to(torch.float32).to(self.device)
|
| 314 |
+
attention_mask = batch_embeds.new_ones((batch_embeds.shape[0], batch_embeds.shape[1]))
|
| 315 |
+
batch_pred = self.model.forward(batch_embeds, attention_mask)
|
| 316 |
+
for idx_i in range(batch_pred.shape[2]):
|
| 317 |
+
batch_pred[:, :, idx_i, idx_i] = -9999
|
| 318 |
+
batch_pred = batch_pred.sigmoid()
|
| 319 |
+
|
| 320 |
+
pred_rels = []
|
| 321 |
+
_, topk_indices = torch.topk(
|
| 322 |
+
batch_pred.reshape(
|
| 323 |
+
[
|
| 324 |
+
-1,
|
| 325 |
+
]
|
| 326 |
+
),
|
| 327 |
+
k=pred_keep_num,
|
| 328 |
+
)
|
| 329 |
+
|
| 330 |
+
# subject, object, relation
|
| 331 |
+
for index in topk_indices:
|
| 332 |
+
pred_relation = index // (batch_pred.shape[2] ** 2)
|
| 333 |
+
index_subject_object = index % (batch_pred.shape[2] ** 2)
|
| 334 |
+
pred_subject = index_subject_object // batch_pred.shape[2]
|
| 335 |
+
pred_object = index_subject_object % batch_pred.shape[2]
|
| 336 |
+
pred = [pred_subject.item(), pred_object.item(), pred_relation.item()]
|
| 337 |
+
pred_rels.append(pred)
|
| 338 |
+
return batch_pred, pred_rels
|
| 339 |
+
|
| 340 |
+
def eval(self):
|
| 341 |
+
sum_recall_20 = 0.0
|
| 342 |
+
sum_recall_50 = 0.0
|
| 343 |
+
sum_recall_100 = 0.0
|
| 344 |
+
prog_bar = ProgressBar(len(self.dataloader))
|
| 345 |
+
for batch_idx, batch_data in enumerate(self.dataloader):
|
| 346 |
+
batch_embeds = batch_data[0]
|
| 347 |
+
batch_target = batch_data[1]
|
| 348 |
+
gt_rels = batch_data[2]
|
| 349 |
+
batch_pred, pred_rels = self.predict(batch_embeds)
|
| 350 |
+
this_recall_20 = get_recall_N(batch_pred, batch_target, object_num=20)
|
| 351 |
+
this_recall_50 = get_recall_N(batch_pred, batch_target, object_num=50)
|
| 352 |
+
this_recall_100 = get_recall_N(batch_pred, batch_target, object_num=100)
|
| 353 |
+
sum_recall_20 += this_recall_20.item()
|
| 354 |
+
sum_recall_50 += this_recall_50.item()
|
| 355 |
+
sum_recall_100 += this_recall_100.item()
|
| 356 |
+
prog_bar.update()
|
| 357 |
+
recall_20 = sum_recall_20 / len(self.dataloader)
|
| 358 |
+
recall_50 = sum_recall_50 / len(self.dataloader)
|
| 359 |
+
recall_100 = sum_recall_100 / len(self.dataloader)
|
| 360 |
+
metric = {
|
| 361 |
+
"recall_20": recall_20,
|
| 362 |
+
"recall_50": recall_50,
|
| 363 |
+
"recall_100": recall_100,
|
| 364 |
+
}
|
| 365 |
+
return metric
|
| 366 |
+
|
| 367 |
+
|
| 368 |
+
if __name__ == "__main__":
|
| 369 |
+
# Config
|
| 370 |
+
config = dict(
|
| 371 |
+
dataset=dict(
|
| 372 |
+
data_path="./data/feat_0420.npz",
|
| 373 |
+
is_train=True,
|
| 374 |
+
num_relation_classes=56,
|
| 375 |
+
),
|
| 376 |
+
dataloader=dict(
|
| 377 |
+
batch_size=4,
|
| 378 |
+
),
|
| 379 |
+
model=dict(
|
| 380 |
+
pretrained_model_name_or_path="bert-base-uncased",
|
| 381 |
+
load_pretrained_weights=True,
|
| 382 |
+
num_transformer_layer=2,
|
| 383 |
+
input_feature_size=256,
|
| 384 |
+
output_feature_size=768,
|
| 385 |
+
cls_feature_size=512,
|
| 386 |
+
num_relation_classes=56,
|
| 387 |
+
pred_type="attention",
|
| 388 |
+
loss_type="multi_label_ce",
|
| 389 |
+
),
|
| 390 |
+
optim=dict(
|
| 391 |
+
lr=1e-4,
|
| 392 |
+
weight_decay=0.05,
|
| 393 |
+
eps=1e-8,
|
| 394 |
+
betas=(0.9, 0.999),
|
| 395 |
+
max_norm=0.01,
|
| 396 |
+
norm_type=2,
|
| 397 |
+
lr_scheduler=dict(
|
| 398 |
+
step=[6, 10],
|
| 399 |
+
gamma=0.1,
|
| 400 |
+
),
|
| 401 |
+
),
|
| 402 |
+
num_epoch=12,
|
| 403 |
+
output_dir="./work_dirs",
|
| 404 |
+
load_from=None,
|
| 405 |
+
)
|
| 406 |
+
|
| 407 |
+
# Train
|
| 408 |
+
config = Config(config)
|
| 409 |
+
trainer = RamTrainer(config)
|
| 410 |
+
last_model_path = trainer.train()
|
| 411 |
+
|
| 412 |
+
# Test/Eval
|
| 413 |
+
config.dataset.is_train = False
|
| 414 |
+
config.load_from = last_model_path
|
| 415 |
+
predictor = RamPredictor(config)
|
| 416 |
+
metric = predictor.eval()
|
| 417 |
+
print(metric)
|
segment_anything/__init__.py
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
from .build_sam import (
|
| 8 |
+
build_sam,
|
| 9 |
+
build_sam_vit_h,
|
| 10 |
+
build_sam_vit_l,
|
| 11 |
+
build_sam_vit_b,
|
| 12 |
+
sam_model_registry,
|
| 13 |
+
)
|
| 14 |
+
from .predictor import SamPredictor
|
| 15 |
+
from .automatic_mask_generator import SamAutomaticMaskGenerator
|
segment_anything/automatic_mask_generator.py
ADDED
|
@@ -0,0 +1,374 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import numpy as np
|
| 8 |
+
import torch
|
| 9 |
+
from torchvision.ops.boxes import batched_nms, box_area # type: ignore
|
| 10 |
+
|
| 11 |
+
from typing import Any, Dict, List, Optional, Tuple
|
| 12 |
+
|
| 13 |
+
from .modeling import Sam
|
| 14 |
+
from .predictor import SamPredictor
|
| 15 |
+
from .utils.amg import (
|
| 16 |
+
MaskData,
|
| 17 |
+
area_from_rle,
|
| 18 |
+
batch_iterator,
|
| 19 |
+
batched_mask_to_box,
|
| 20 |
+
box_xyxy_to_xywh,
|
| 21 |
+
build_all_layer_point_grids,
|
| 22 |
+
calculate_stability_score,
|
| 23 |
+
coco_encode_rle,
|
| 24 |
+
generate_crop_boxes,
|
| 25 |
+
is_box_near_crop_edge,
|
| 26 |
+
mask_to_rle_pytorch,
|
| 27 |
+
remove_small_regions,
|
| 28 |
+
rle_to_mask,
|
| 29 |
+
uncrop_boxes_xyxy,
|
| 30 |
+
uncrop_masks,
|
| 31 |
+
uncrop_points,
|
| 32 |
+
)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
class SamAutomaticMaskGenerator:
|
| 36 |
+
def __init__(
|
| 37 |
+
self,
|
| 38 |
+
model: Sam,
|
| 39 |
+
points_per_side: Optional[int] = 32,
|
| 40 |
+
points_per_batch: int = 64,
|
| 41 |
+
pred_iou_thresh: float = 0.88,
|
| 42 |
+
stability_score_thresh: float = 0.95,
|
| 43 |
+
stability_score_offset: float = 1.0,
|
| 44 |
+
box_nms_thresh: float = 0.7,
|
| 45 |
+
crop_n_layers: int = 0,
|
| 46 |
+
crop_nms_thresh: float = 0.7,
|
| 47 |
+
crop_overlap_ratio: float = 512 / 1500,
|
| 48 |
+
crop_n_points_downscale_factor: int = 1,
|
| 49 |
+
point_grids: Optional[List[np.ndarray]] = None,
|
| 50 |
+
min_mask_region_area: int = 0,
|
| 51 |
+
output_mode: str = "binary_mask",
|
| 52 |
+
) -> None:
|
| 53 |
+
"""
|
| 54 |
+
Using a SAM model, generates masks for the entire image.
|
| 55 |
+
Generates a grid of point prompts over the image, then filters
|
| 56 |
+
low quality and duplicate masks. The default settings are chosen
|
| 57 |
+
for SAM with a ViT-H backbone.
|
| 58 |
+
|
| 59 |
+
Arguments:
|
| 60 |
+
model (Sam): The SAM model to use for mask prediction.
|
| 61 |
+
points_per_side (int or None): The number of points to be sampled
|
| 62 |
+
along one side of the image. The total number of points is
|
| 63 |
+
points_per_side**2. If None, 'point_grids' must provide explicit
|
| 64 |
+
point sampling.
|
| 65 |
+
points_per_batch (int): Sets the number of points run simultaneously
|
| 66 |
+
by the model. Higher numbers may be faster but use more GPU memory.
|
| 67 |
+
pred_iou_thresh (float): A filtering threshold in [0,1], using the
|
| 68 |
+
model's predicted mask quality.
|
| 69 |
+
stability_score_thresh (float): A filtering threshold in [0,1], using
|
| 70 |
+
the stability of the mask under changes to the cutoff used to binarize
|
| 71 |
+
the model's mask predictions.
|
| 72 |
+
stability_score_offset (float): The amount to shift the cutoff when
|
| 73 |
+
calculated the stability score.
|
| 74 |
+
box_nms_thresh (float): The box IoU cutoff used by non-maximal
|
| 75 |
+
suppression to filter duplicate masks.
|
| 76 |
+
crops_n_layers (int): If >0, mask prediction will be run again on
|
| 77 |
+
crops of the image. Sets the number of layers to run, where each
|
| 78 |
+
layer has 2**i_layer number of image crops.
|
| 79 |
+
crops_nms_thresh (float): The box IoU cutoff used by non-maximal
|
| 80 |
+
suppression to filter duplicate masks between different crops.
|
| 81 |
+
crop_overlap_ratio (float): Sets the degree to which crops overlap.
|
| 82 |
+
In the first crop layer, crops will overlap by this fraction of
|
| 83 |
+
the image length. Later layers with more crops scale down this overlap.
|
| 84 |
+
crop_n_points_downscale_factor (int): The number of points-per-side
|
| 85 |
+
sampled in layer n is scaled down by crop_n_points_downscale_factor**n.
|
| 86 |
+
point_grids (list(np.ndarray) or None): A list over explicit grids
|
| 87 |
+
of points used for sampling, normalized to [0,1]. The nth grid in the
|
| 88 |
+
list is used in the nth crop layer. Exclusive with points_per_side.
|
| 89 |
+
min_mask_region_area (int): If >0, postprocessing will be applied
|
| 90 |
+
to remove disconnected regions and holes in masks with area smaller
|
| 91 |
+
than min_mask_region_area. Requires opencv.
|
| 92 |
+
output_mode (str): The form masks are returned in. Can be 'binary_mask',
|
| 93 |
+
'uncompressed_rle', or 'coco_rle'. 'coco_rle' requires pycocotools.
|
| 94 |
+
For large resolutions, 'binary_mask' may consume large amounts of
|
| 95 |
+
memory.
|
| 96 |
+
"""
|
| 97 |
+
|
| 98 |
+
assert (points_per_side is None) != (
|
| 99 |
+
point_grids is None
|
| 100 |
+
), "Exactly one of points_per_side or point_grid must be provided."
|
| 101 |
+
if points_per_side is not None:
|
| 102 |
+
self.point_grids = build_all_layer_point_grids(
|
| 103 |
+
points_per_side,
|
| 104 |
+
crop_n_layers,
|
| 105 |
+
crop_n_points_downscale_factor,
|
| 106 |
+
)
|
| 107 |
+
elif point_grids is not None:
|
| 108 |
+
self.point_grids = point_grids
|
| 109 |
+
else:
|
| 110 |
+
raise ValueError("Can't have both points_per_side and point_grid be None.")
|
| 111 |
+
|
| 112 |
+
assert output_mode in [
|
| 113 |
+
"binary_mask",
|
| 114 |
+
"uncompressed_rle",
|
| 115 |
+
"coco_rle",
|
| 116 |
+
], f"Unknown output_mode {output_mode}."
|
| 117 |
+
if output_mode == "coco_rle":
|
| 118 |
+
from pycocotools import mask as mask_utils # type: ignore # noqa: F401
|
| 119 |
+
|
| 120 |
+
if min_mask_region_area > 0:
|
| 121 |
+
import cv2 # type: ignore # noqa: F401
|
| 122 |
+
|
| 123 |
+
self.predictor = SamPredictor(model)
|
| 124 |
+
self.points_per_batch = points_per_batch
|
| 125 |
+
self.pred_iou_thresh = pred_iou_thresh
|
| 126 |
+
self.stability_score_thresh = stability_score_thresh
|
| 127 |
+
self.stability_score_offset = stability_score_offset
|
| 128 |
+
self.box_nms_thresh = box_nms_thresh
|
| 129 |
+
self.crop_n_layers = crop_n_layers
|
| 130 |
+
self.crop_nms_thresh = crop_nms_thresh
|
| 131 |
+
self.crop_overlap_ratio = crop_overlap_ratio
|
| 132 |
+
self.crop_n_points_downscale_factor = crop_n_points_downscale_factor
|
| 133 |
+
self.min_mask_region_area = min_mask_region_area
|
| 134 |
+
self.output_mode = output_mode
|
| 135 |
+
|
| 136 |
+
@torch.no_grad()
|
| 137 |
+
def generate(self, image: np.ndarray) -> List[Dict[str, Any]]:
|
| 138 |
+
"""
|
| 139 |
+
Generates masks for the given image.
|
| 140 |
+
|
| 141 |
+
Arguments:
|
| 142 |
+
image (np.ndarray): The image to generate masks for, in HWC uint8 format.
|
| 143 |
+
|
| 144 |
+
Returns:
|
| 145 |
+
list(dict(str, any)): A list over records for masks. Each record is
|
| 146 |
+
a dict containing the following keys:
|
| 147 |
+
segmentation (dict(str, any) or np.ndarray): The mask. If
|
| 148 |
+
output_mode='binary_mask', is an array of shape HW. Otherwise,
|
| 149 |
+
is a dictionary containing the RLE.
|
| 150 |
+
bbox (list(float)): The box around the mask, in XYWH format.
|
| 151 |
+
area (int): The area in pixels of the mask.
|
| 152 |
+
predicted_iou (float): The model's own prediction of the mask's
|
| 153 |
+
quality. This is filtered by the pred_iou_thresh parameter.
|
| 154 |
+
point_coords (list(list(float))): The point coordinates input
|
| 155 |
+
to the model to generate this mask.
|
| 156 |
+
stability_score (float): A measure of the mask's quality. This
|
| 157 |
+
is filtered on using the stability_score_thresh parameter.
|
| 158 |
+
crop_box (list(float)): The crop of the image used to generate
|
| 159 |
+
the mask, given in XYWH format.
|
| 160 |
+
"""
|
| 161 |
+
|
| 162 |
+
# Generate masks
|
| 163 |
+
mask_data = self._generate_masks(image)
|
| 164 |
+
|
| 165 |
+
# Filter small disconnected regions and holes in masks
|
| 166 |
+
if self.min_mask_region_area > 0:
|
| 167 |
+
mask_data = self.postprocess_small_regions(
|
| 168 |
+
mask_data,
|
| 169 |
+
self.min_mask_region_area,
|
| 170 |
+
max(self.box_nms_thresh, self.crop_nms_thresh),
|
| 171 |
+
)
|
| 172 |
+
|
| 173 |
+
# Encode masks
|
| 174 |
+
if self.output_mode == "coco_rle":
|
| 175 |
+
mask_data["segmentations"] = [coco_encode_rle(rle) for rle in mask_data["rles"]]
|
| 176 |
+
elif self.output_mode == "binary_mask":
|
| 177 |
+
mask_data["segmentations"] = [rle_to_mask(rle) for rle in mask_data["rles"]]
|
| 178 |
+
else:
|
| 179 |
+
mask_data["segmentations"] = mask_data["rles"]
|
| 180 |
+
|
| 181 |
+
# Write mask records
|
| 182 |
+
curr_anns = []
|
| 183 |
+
for idx in range(len(mask_data["segmentations"])):
|
| 184 |
+
ann = {
|
| 185 |
+
"segmentation": mask_data["segmentations"][idx],
|
| 186 |
+
"area": area_from_rle(mask_data["rles"][idx]),
|
| 187 |
+
"bbox": box_xyxy_to_xywh(mask_data["boxes"][idx]).tolist(),
|
| 188 |
+
"predicted_iou": mask_data["iou_preds"][idx].item(),
|
| 189 |
+
"point_coords": [mask_data["points"][idx].tolist()],
|
| 190 |
+
"stability_score": mask_data["stability_score"][idx].item(),
|
| 191 |
+
"crop_box": box_xyxy_to_xywh(mask_data["crop_boxes"][idx]).tolist(),
|
| 192 |
+
"feat": mask_data["feats"][idx].tolist(),
|
| 193 |
+
}
|
| 194 |
+
curr_anns.append(ann)
|
| 195 |
+
|
| 196 |
+
return curr_anns
|
| 197 |
+
|
| 198 |
+
def _generate_masks(self, image: np.ndarray) -> MaskData:
|
| 199 |
+
orig_size = image.shape[:2]
|
| 200 |
+
crop_boxes, layer_idxs = generate_crop_boxes(
|
| 201 |
+
orig_size, self.crop_n_layers, self.crop_overlap_ratio
|
| 202 |
+
)
|
| 203 |
+
|
| 204 |
+
# Iterate over image crops
|
| 205 |
+
data = MaskData()
|
| 206 |
+
for crop_box, layer_idx in zip(crop_boxes, layer_idxs):
|
| 207 |
+
crop_data = self._process_crop(image, crop_box, layer_idx, orig_size)
|
| 208 |
+
data.cat(crop_data)
|
| 209 |
+
|
| 210 |
+
# Remove duplicate masks between crops
|
| 211 |
+
if len(crop_boxes) > 1:
|
| 212 |
+
# Prefer masks from smaller crops
|
| 213 |
+
scores = 1 / box_area(data["crop_boxes"])
|
| 214 |
+
scores = scores.to(data["boxes"].device)
|
| 215 |
+
keep_by_nms = batched_nms(
|
| 216 |
+
data["boxes"].float(),
|
| 217 |
+
scores,
|
| 218 |
+
torch.zeros(len(data["boxes"])), # categories
|
| 219 |
+
iou_threshold=self.crop_nms_thresh,
|
| 220 |
+
)
|
| 221 |
+
data.filter(keep_by_nms)
|
| 222 |
+
|
| 223 |
+
data.to_numpy()
|
| 224 |
+
return data
|
| 225 |
+
|
| 226 |
+
def _process_crop(
|
| 227 |
+
self,
|
| 228 |
+
image: np.ndarray,
|
| 229 |
+
crop_box: List[int],
|
| 230 |
+
crop_layer_idx: int,
|
| 231 |
+
orig_size: Tuple[int, ...],
|
| 232 |
+
) -> MaskData:
|
| 233 |
+
# Crop the image and calculate embeddings
|
| 234 |
+
x0, y0, x1, y1 = crop_box
|
| 235 |
+
cropped_im = image[y0:y1, x0:x1, :]
|
| 236 |
+
cropped_im_size = cropped_im.shape[:2]
|
| 237 |
+
self.predictor.set_image(cropped_im)
|
| 238 |
+
|
| 239 |
+
# Get points for this crop
|
| 240 |
+
points_scale = np.array(cropped_im_size)[None, ::-1]
|
| 241 |
+
points_for_image = self.point_grids[crop_layer_idx] * points_scale
|
| 242 |
+
|
| 243 |
+
# Generate masks for this crop in batches
|
| 244 |
+
data = MaskData()
|
| 245 |
+
for (points,) in batch_iterator(self.points_per_batch, points_for_image):
|
| 246 |
+
batch_data = self._process_batch(points, cropped_im_size, crop_box, orig_size)
|
| 247 |
+
data.cat(batch_data)
|
| 248 |
+
del batch_data
|
| 249 |
+
self.predictor.reset_image()
|
| 250 |
+
|
| 251 |
+
# Remove duplicates within this crop.
|
| 252 |
+
keep_by_nms = batched_nms(
|
| 253 |
+
data["boxes"].float(),
|
| 254 |
+
data["iou_preds"],
|
| 255 |
+
torch.zeros(len(data["boxes"])), # categories
|
| 256 |
+
iou_threshold=self.box_nms_thresh,
|
| 257 |
+
)
|
| 258 |
+
data.filter(keep_by_nms)
|
| 259 |
+
|
| 260 |
+
# Return to the original image frame
|
| 261 |
+
data["boxes"] = uncrop_boxes_xyxy(data["boxes"], crop_box)
|
| 262 |
+
data["points"] = uncrop_points(data["points"], crop_box)
|
| 263 |
+
data["crop_boxes"] = torch.tensor([crop_box for _ in range(len(data["rles"]))])
|
| 264 |
+
|
| 265 |
+
return data
|
| 266 |
+
|
| 267 |
+
def _process_batch(
|
| 268 |
+
self,
|
| 269 |
+
points: np.ndarray,
|
| 270 |
+
im_size: Tuple[int, ...],
|
| 271 |
+
crop_box: List[int],
|
| 272 |
+
orig_size: Tuple[int, ...],
|
| 273 |
+
) -> MaskData:
|
| 274 |
+
orig_h, orig_w = orig_size
|
| 275 |
+
|
| 276 |
+
# Run model on this batch
|
| 277 |
+
transformed_points = self.predictor.transform.apply_coords(points, im_size)
|
| 278 |
+
in_points = torch.as_tensor(transformed_points, device=self.predictor.device)
|
| 279 |
+
in_labels = torch.ones(in_points.shape[0], dtype=torch.int, device=in_points.device)
|
| 280 |
+
masks, iou_preds, _, feats = self.predictor.predict_torch(
|
| 281 |
+
in_points[:, None, :],
|
| 282 |
+
in_labels[:, None],
|
| 283 |
+
multimask_output=True,
|
| 284 |
+
return_logits=True,
|
| 285 |
+
)
|
| 286 |
+
|
| 287 |
+
# Serialize predictions and store in MaskData
|
| 288 |
+
data = MaskData(
|
| 289 |
+
feats=feats.flatten(0, 1),
|
| 290 |
+
masks=masks.flatten(0, 1),
|
| 291 |
+
iou_preds=iou_preds.flatten(0, 1),
|
| 292 |
+
points=torch.as_tensor(points.repeat(masks.shape[1], axis=0)),
|
| 293 |
+
)
|
| 294 |
+
del masks
|
| 295 |
+
|
| 296 |
+
# Filter by predicted IoU
|
| 297 |
+
if self.pred_iou_thresh > 0.0:
|
| 298 |
+
keep_mask = data["iou_preds"] > self.pred_iou_thresh
|
| 299 |
+
data.filter(keep_mask)
|
| 300 |
+
|
| 301 |
+
# Calculate stability score
|
| 302 |
+
data["stability_score"] = calculate_stability_score(
|
| 303 |
+
data["masks"], self.predictor.model.mask_threshold, self.stability_score_offset
|
| 304 |
+
)
|
| 305 |
+
if self.stability_score_thresh > 0.0:
|
| 306 |
+
keep_mask = data["stability_score"] >= self.stability_score_thresh
|
| 307 |
+
data.filter(keep_mask)
|
| 308 |
+
|
| 309 |
+
# Threshold masks and calculate boxes
|
| 310 |
+
data["masks"] = data["masks"] > self.predictor.model.mask_threshold
|
| 311 |
+
data["boxes"] = batched_mask_to_box(data["masks"])
|
| 312 |
+
|
| 313 |
+
# Filter boxes that touch crop boundaries
|
| 314 |
+
keep_mask = ~is_box_near_crop_edge(data["boxes"], crop_box, [0, 0, orig_w, orig_h])
|
| 315 |
+
if not torch.all(keep_mask):
|
| 316 |
+
data.filter(keep_mask)
|
| 317 |
+
|
| 318 |
+
# Compress to RLE
|
| 319 |
+
data["masks"] = uncrop_masks(data["masks"], crop_box, orig_h, orig_w)
|
| 320 |
+
data["rles"] = mask_to_rle_pytorch(data["masks"])
|
| 321 |
+
del data["masks"]
|
| 322 |
+
|
| 323 |
+
return data
|
| 324 |
+
|
| 325 |
+
@staticmethod
|
| 326 |
+
def postprocess_small_regions(
|
| 327 |
+
mask_data: MaskData, min_area: int, nms_thresh: float
|
| 328 |
+
) -> MaskData:
|
| 329 |
+
"""
|
| 330 |
+
Removes small disconnected regions and holes in masks, then reruns
|
| 331 |
+
box NMS to remove any new duplicates.
|
| 332 |
+
|
| 333 |
+
Edits mask_data in place.
|
| 334 |
+
|
| 335 |
+
Requires open-cv as a dependency.
|
| 336 |
+
"""
|
| 337 |
+
if len(mask_data["rles"]) == 0:
|
| 338 |
+
return mask_data
|
| 339 |
+
|
| 340 |
+
# Filter small disconnected regions and holes
|
| 341 |
+
new_masks = []
|
| 342 |
+
scores = []
|
| 343 |
+
for rle in mask_data["rles"]:
|
| 344 |
+
mask = rle_to_mask(rle)
|
| 345 |
+
|
| 346 |
+
mask, changed = remove_small_regions(mask, min_area, mode="holes")
|
| 347 |
+
unchanged = not changed
|
| 348 |
+
mask, changed = remove_small_regions(mask, min_area, mode="islands")
|
| 349 |
+
unchanged = unchanged and not changed
|
| 350 |
+
|
| 351 |
+
new_masks.append(torch.as_tensor(mask).unsqueeze(0))
|
| 352 |
+
# Give score=0 to changed masks and score=1 to unchanged masks
|
| 353 |
+
# so NMS will prefer ones that didn't need postprocessing
|
| 354 |
+
scores.append(float(unchanged))
|
| 355 |
+
|
| 356 |
+
# Recalculate boxes and remove any new duplicates
|
| 357 |
+
masks = torch.cat(new_masks, dim=0)
|
| 358 |
+
boxes = batched_mask_to_box(masks)
|
| 359 |
+
keep_by_nms = batched_nms(
|
| 360 |
+
boxes.float(),
|
| 361 |
+
torch.as_tensor(scores),
|
| 362 |
+
torch.zeros(len(boxes)), # categories
|
| 363 |
+
iou_threshold=nms_thresh,
|
| 364 |
+
)
|
| 365 |
+
|
| 366 |
+
# Only recalculate RLEs for masks that have changed
|
| 367 |
+
for i_mask in keep_by_nms:
|
| 368 |
+
if scores[i_mask] == 0.0:
|
| 369 |
+
mask_torch = masks[i_mask].unsqueeze(0)
|
| 370 |
+
mask_data["rles"][i_mask] = mask_to_rle_pytorch(mask_torch)[0]
|
| 371 |
+
mask_data["boxes"][i_mask] = boxes[i_mask] # update res directly
|
| 372 |
+
mask_data.filter(keep_by_nms)
|
| 373 |
+
|
| 374 |
+
return mask_data
|
segment_anything/build_sam.py
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
|
| 9 |
+
from functools import partial
|
| 10 |
+
|
| 11 |
+
from .modeling import ImageEncoderViT, MaskDecoder, PromptEncoder, Sam, TwoWayTransformer
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def build_sam_vit_h(checkpoint=None):
|
| 15 |
+
return _build_sam(
|
| 16 |
+
encoder_embed_dim=1280,
|
| 17 |
+
encoder_depth=32,
|
| 18 |
+
encoder_num_heads=16,
|
| 19 |
+
encoder_global_attn_indexes=[7, 15, 23, 31],
|
| 20 |
+
checkpoint=checkpoint,
|
| 21 |
+
)
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
build_sam = build_sam_vit_h
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def build_sam_vit_l(checkpoint=None):
|
| 28 |
+
return _build_sam(
|
| 29 |
+
encoder_embed_dim=1024,
|
| 30 |
+
encoder_depth=24,
|
| 31 |
+
encoder_num_heads=16,
|
| 32 |
+
encoder_global_attn_indexes=[5, 11, 17, 23],
|
| 33 |
+
checkpoint=checkpoint,
|
| 34 |
+
)
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def build_sam_vit_b(checkpoint=None):
|
| 38 |
+
return _build_sam(
|
| 39 |
+
encoder_embed_dim=768,
|
| 40 |
+
encoder_depth=12,
|
| 41 |
+
encoder_num_heads=12,
|
| 42 |
+
encoder_global_attn_indexes=[2, 5, 8, 11],
|
| 43 |
+
checkpoint=checkpoint,
|
| 44 |
+
)
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
sam_model_registry = {
|
| 48 |
+
"default": build_sam,
|
| 49 |
+
"vit_h": build_sam,
|
| 50 |
+
"vit_l": build_sam_vit_l,
|
| 51 |
+
"vit_b": build_sam_vit_b,
|
| 52 |
+
}
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def _build_sam(
|
| 56 |
+
encoder_embed_dim,
|
| 57 |
+
encoder_depth,
|
| 58 |
+
encoder_num_heads,
|
| 59 |
+
encoder_global_attn_indexes,
|
| 60 |
+
checkpoint=None,
|
| 61 |
+
):
|
| 62 |
+
prompt_embed_dim = 256
|
| 63 |
+
image_size = 1024
|
| 64 |
+
vit_patch_size = 16
|
| 65 |
+
image_embedding_size = image_size // vit_patch_size
|
| 66 |
+
sam = Sam(
|
| 67 |
+
image_encoder=ImageEncoderViT(
|
| 68 |
+
depth=encoder_depth,
|
| 69 |
+
embed_dim=encoder_embed_dim,
|
| 70 |
+
img_size=image_size,
|
| 71 |
+
mlp_ratio=4,
|
| 72 |
+
norm_layer=partial(torch.nn.LayerNorm, eps=1e-6),
|
| 73 |
+
num_heads=encoder_num_heads,
|
| 74 |
+
patch_size=vit_patch_size,
|
| 75 |
+
qkv_bias=True,
|
| 76 |
+
use_rel_pos=True,
|
| 77 |
+
global_attn_indexes=encoder_global_attn_indexes,
|
| 78 |
+
window_size=14,
|
| 79 |
+
out_chans=prompt_embed_dim,
|
| 80 |
+
),
|
| 81 |
+
prompt_encoder=PromptEncoder(
|
| 82 |
+
embed_dim=prompt_embed_dim,
|
| 83 |
+
image_embedding_size=(image_embedding_size, image_embedding_size),
|
| 84 |
+
input_image_size=(image_size, image_size),
|
| 85 |
+
mask_in_chans=16,
|
| 86 |
+
),
|
| 87 |
+
mask_decoder=MaskDecoder(
|
| 88 |
+
num_multimask_outputs=3,
|
| 89 |
+
transformer=TwoWayTransformer(
|
| 90 |
+
depth=2,
|
| 91 |
+
embedding_dim=prompt_embed_dim,
|
| 92 |
+
mlp_dim=2048,
|
| 93 |
+
num_heads=8,
|
| 94 |
+
),
|
| 95 |
+
transformer_dim=prompt_embed_dim,
|
| 96 |
+
iou_head_depth=3,
|
| 97 |
+
iou_head_hidden_dim=256,
|
| 98 |
+
),
|
| 99 |
+
pixel_mean=[123.675, 116.28, 103.53],
|
| 100 |
+
pixel_std=[58.395, 57.12, 57.375],
|
| 101 |
+
)
|
| 102 |
+
sam.eval()
|
| 103 |
+
if checkpoint is not None:
|
| 104 |
+
with open(checkpoint, "rb") as f:
|
| 105 |
+
state_dict = torch.load(f)
|
| 106 |
+
sam.load_state_dict(state_dict)
|
| 107 |
+
return sam
|
segment_anything/modeling/__init__.py
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
from .sam import Sam
|
| 8 |
+
from .image_encoder import ImageEncoderViT
|
| 9 |
+
from .mask_decoder import MaskDecoder
|
| 10 |
+
from .prompt_encoder import PromptEncoder
|
| 11 |
+
from .transformer import TwoWayTransformer
|
segment_anything/modeling/common.py
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
import torch.nn as nn
|
| 9 |
+
|
| 10 |
+
from typing import Type
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class MLPBlock(nn.Module):
|
| 14 |
+
def __init__(
|
| 15 |
+
self,
|
| 16 |
+
embedding_dim: int,
|
| 17 |
+
mlp_dim: int,
|
| 18 |
+
act: Type[nn.Module] = nn.GELU,
|
| 19 |
+
) -> None:
|
| 20 |
+
super().__init__()
|
| 21 |
+
self.lin1 = nn.Linear(embedding_dim, mlp_dim)
|
| 22 |
+
self.lin2 = nn.Linear(mlp_dim, embedding_dim)
|
| 23 |
+
self.act = act()
|
| 24 |
+
|
| 25 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 26 |
+
return self.lin2(self.act(self.lin1(x)))
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
# From https://github.com/facebookresearch/detectron2/blob/main/detectron2/layers/batch_norm.py # noqa
|
| 30 |
+
# Itself from https://github.com/facebookresearch/ConvNeXt/blob/d1fa8f6fef0a165b27399986cc2bdacc92777e40/models/convnext.py#L119 # noqa
|
| 31 |
+
class LayerNorm2d(nn.Module):
|
| 32 |
+
def __init__(self, num_channels: int, eps: float = 1e-6) -> None:
|
| 33 |
+
super().__init__()
|
| 34 |
+
self.weight = nn.Parameter(torch.ones(num_channels))
|
| 35 |
+
self.bias = nn.Parameter(torch.zeros(num_channels))
|
| 36 |
+
self.eps = eps
|
| 37 |
+
|
| 38 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 39 |
+
u = x.mean(1, keepdim=True)
|
| 40 |
+
s = (x - u).pow(2).mean(1, keepdim=True)
|
| 41 |
+
x = (x - u) / torch.sqrt(s + self.eps)
|
| 42 |
+
x = self.weight[:, None, None] * x + self.bias[:, None, None]
|
| 43 |
+
return x
|
segment_anything/modeling/image_encoder.py
ADDED
|
@@ -0,0 +1,395 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
import torch.nn as nn
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
|
| 11 |
+
from typing import Optional, Tuple, Type
|
| 12 |
+
|
| 13 |
+
from .common import LayerNorm2d, MLPBlock
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
# This class and its supporting functions below lightly adapted from the ViTDet backbone available at: https://github.com/facebookresearch/detectron2/blob/main/detectron2/modeling/backbone/vit.py # noqa
|
| 17 |
+
class ImageEncoderViT(nn.Module):
|
| 18 |
+
def __init__(
|
| 19 |
+
self,
|
| 20 |
+
img_size: int = 1024,
|
| 21 |
+
patch_size: int = 16,
|
| 22 |
+
in_chans: int = 3,
|
| 23 |
+
embed_dim: int = 768,
|
| 24 |
+
depth: int = 12,
|
| 25 |
+
num_heads: int = 12,
|
| 26 |
+
mlp_ratio: float = 4.0,
|
| 27 |
+
out_chans: int = 256,
|
| 28 |
+
qkv_bias: bool = True,
|
| 29 |
+
norm_layer: Type[nn.Module] = nn.LayerNorm,
|
| 30 |
+
act_layer: Type[nn.Module] = nn.GELU,
|
| 31 |
+
use_abs_pos: bool = True,
|
| 32 |
+
use_rel_pos: bool = False,
|
| 33 |
+
rel_pos_zero_init: bool = True,
|
| 34 |
+
window_size: int = 0,
|
| 35 |
+
global_attn_indexes: Tuple[int, ...] = (),
|
| 36 |
+
) -> None:
|
| 37 |
+
"""
|
| 38 |
+
Args:
|
| 39 |
+
img_size (int): Input image size.
|
| 40 |
+
patch_size (int): Patch size.
|
| 41 |
+
in_chans (int): Number of input image channels.
|
| 42 |
+
embed_dim (int): Patch embedding dimension.
|
| 43 |
+
depth (int): Depth of ViT.
|
| 44 |
+
num_heads (int): Number of attention heads in each ViT block.
|
| 45 |
+
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
|
| 46 |
+
qkv_bias (bool): If True, add a learnable bias to query, key, value.
|
| 47 |
+
norm_layer (nn.Module): Normalization layer.
|
| 48 |
+
act_layer (nn.Module): Activation layer.
|
| 49 |
+
use_abs_pos (bool): If True, use absolute positional embeddings.
|
| 50 |
+
use_rel_pos (bool): If True, add relative positional embeddings to the attention map.
|
| 51 |
+
rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
|
| 52 |
+
window_size (int): Window size for window attention blocks.
|
| 53 |
+
global_attn_indexes (list): Indexes for blocks using global attention.
|
| 54 |
+
"""
|
| 55 |
+
super().__init__()
|
| 56 |
+
self.img_size = img_size
|
| 57 |
+
|
| 58 |
+
self.patch_embed = PatchEmbed(
|
| 59 |
+
kernel_size=(patch_size, patch_size),
|
| 60 |
+
stride=(patch_size, patch_size),
|
| 61 |
+
in_chans=in_chans,
|
| 62 |
+
embed_dim=embed_dim,
|
| 63 |
+
)
|
| 64 |
+
|
| 65 |
+
self.pos_embed: Optional[nn.Parameter] = None
|
| 66 |
+
if use_abs_pos:
|
| 67 |
+
# Initialize absolute positional embedding with pretrain image size.
|
| 68 |
+
self.pos_embed = nn.Parameter(
|
| 69 |
+
torch.zeros(1, img_size // patch_size, img_size // patch_size, embed_dim)
|
| 70 |
+
)
|
| 71 |
+
|
| 72 |
+
self.blocks = nn.ModuleList()
|
| 73 |
+
for i in range(depth):
|
| 74 |
+
block = Block(
|
| 75 |
+
dim=embed_dim,
|
| 76 |
+
num_heads=num_heads,
|
| 77 |
+
mlp_ratio=mlp_ratio,
|
| 78 |
+
qkv_bias=qkv_bias,
|
| 79 |
+
norm_layer=norm_layer,
|
| 80 |
+
act_layer=act_layer,
|
| 81 |
+
use_rel_pos=use_rel_pos,
|
| 82 |
+
rel_pos_zero_init=rel_pos_zero_init,
|
| 83 |
+
window_size=window_size if i not in global_attn_indexes else 0,
|
| 84 |
+
input_size=(img_size // patch_size, img_size // patch_size),
|
| 85 |
+
)
|
| 86 |
+
self.blocks.append(block)
|
| 87 |
+
|
| 88 |
+
self.neck = nn.Sequential(
|
| 89 |
+
nn.Conv2d(
|
| 90 |
+
embed_dim,
|
| 91 |
+
out_chans,
|
| 92 |
+
kernel_size=1,
|
| 93 |
+
bias=False,
|
| 94 |
+
),
|
| 95 |
+
LayerNorm2d(out_chans),
|
| 96 |
+
nn.Conv2d(
|
| 97 |
+
out_chans,
|
| 98 |
+
out_chans,
|
| 99 |
+
kernel_size=3,
|
| 100 |
+
padding=1,
|
| 101 |
+
bias=False,
|
| 102 |
+
),
|
| 103 |
+
LayerNorm2d(out_chans),
|
| 104 |
+
)
|
| 105 |
+
|
| 106 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 107 |
+
x = self.patch_embed(x)
|
| 108 |
+
if self.pos_embed is not None:
|
| 109 |
+
x = x + self.pos_embed
|
| 110 |
+
|
| 111 |
+
for blk in self.blocks:
|
| 112 |
+
x = blk(x)
|
| 113 |
+
|
| 114 |
+
x = self.neck(x.permute(0, 3, 1, 2))
|
| 115 |
+
|
| 116 |
+
return x
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
class Block(nn.Module):
|
| 120 |
+
"""Transformer blocks with support of window attention and residual propagation blocks"""
|
| 121 |
+
|
| 122 |
+
def __init__(
|
| 123 |
+
self,
|
| 124 |
+
dim: int,
|
| 125 |
+
num_heads: int,
|
| 126 |
+
mlp_ratio: float = 4.0,
|
| 127 |
+
qkv_bias: bool = True,
|
| 128 |
+
norm_layer: Type[nn.Module] = nn.LayerNorm,
|
| 129 |
+
act_layer: Type[nn.Module] = nn.GELU,
|
| 130 |
+
use_rel_pos: bool = False,
|
| 131 |
+
rel_pos_zero_init: bool = True,
|
| 132 |
+
window_size: int = 0,
|
| 133 |
+
input_size: Optional[Tuple[int, int]] = None,
|
| 134 |
+
) -> None:
|
| 135 |
+
"""
|
| 136 |
+
Args:
|
| 137 |
+
dim (int): Number of input channels.
|
| 138 |
+
num_heads (int): Number of attention heads in each ViT block.
|
| 139 |
+
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
|
| 140 |
+
qkv_bias (bool): If True, add a learnable bias to query, key, value.
|
| 141 |
+
norm_layer (nn.Module): Normalization layer.
|
| 142 |
+
act_layer (nn.Module): Activation layer.
|
| 143 |
+
use_rel_pos (bool): If True, add relative positional embeddings to the attention map.
|
| 144 |
+
rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
|
| 145 |
+
window_size (int): Window size for window attention blocks. If it equals 0, then
|
| 146 |
+
use global attention.
|
| 147 |
+
input_size (int or None): Input resolution for calculating the relative positional
|
| 148 |
+
parameter size.
|
| 149 |
+
"""
|
| 150 |
+
super().__init__()
|
| 151 |
+
self.norm1 = norm_layer(dim)
|
| 152 |
+
self.attn = Attention(
|
| 153 |
+
dim,
|
| 154 |
+
num_heads=num_heads,
|
| 155 |
+
qkv_bias=qkv_bias,
|
| 156 |
+
use_rel_pos=use_rel_pos,
|
| 157 |
+
rel_pos_zero_init=rel_pos_zero_init,
|
| 158 |
+
input_size=input_size if window_size == 0 else (window_size, window_size),
|
| 159 |
+
)
|
| 160 |
+
|
| 161 |
+
self.norm2 = norm_layer(dim)
|
| 162 |
+
self.mlp = MLPBlock(embedding_dim=dim, mlp_dim=int(dim * mlp_ratio), act=act_layer)
|
| 163 |
+
|
| 164 |
+
self.window_size = window_size
|
| 165 |
+
|
| 166 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 167 |
+
shortcut = x
|
| 168 |
+
x = self.norm1(x)
|
| 169 |
+
# Window partition
|
| 170 |
+
if self.window_size > 0:
|
| 171 |
+
H, W = x.shape[1], x.shape[2]
|
| 172 |
+
x, pad_hw = window_partition(x, self.window_size)
|
| 173 |
+
|
| 174 |
+
x = self.attn(x)
|
| 175 |
+
# Reverse window partition
|
| 176 |
+
if self.window_size > 0:
|
| 177 |
+
x = window_unpartition(x, self.window_size, pad_hw, (H, W))
|
| 178 |
+
|
| 179 |
+
x = shortcut + x
|
| 180 |
+
x = x + self.mlp(self.norm2(x))
|
| 181 |
+
|
| 182 |
+
return x
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
class Attention(nn.Module):
|
| 186 |
+
"""Multi-head Attention block with relative position embeddings."""
|
| 187 |
+
|
| 188 |
+
def __init__(
|
| 189 |
+
self,
|
| 190 |
+
dim: int,
|
| 191 |
+
num_heads: int = 8,
|
| 192 |
+
qkv_bias: bool = True,
|
| 193 |
+
use_rel_pos: bool = False,
|
| 194 |
+
rel_pos_zero_init: bool = True,
|
| 195 |
+
input_size: Optional[Tuple[int, int]] = None,
|
| 196 |
+
) -> None:
|
| 197 |
+
"""
|
| 198 |
+
Args:
|
| 199 |
+
dim (int): Number of input channels.
|
| 200 |
+
num_heads (int): Number of attention heads.
|
| 201 |
+
qkv_bias (bool: If True, add a learnable bias to query, key, value.
|
| 202 |
+
rel_pos (bool): If True, add relative positional embeddings to the attention map.
|
| 203 |
+
rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
|
| 204 |
+
input_size (int or None): Input resolution for calculating the relative positional
|
| 205 |
+
parameter size.
|
| 206 |
+
"""
|
| 207 |
+
super().__init__()
|
| 208 |
+
self.num_heads = num_heads
|
| 209 |
+
head_dim = dim // num_heads
|
| 210 |
+
self.scale = head_dim**-0.5
|
| 211 |
+
|
| 212 |
+
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
|
| 213 |
+
self.proj = nn.Linear(dim, dim)
|
| 214 |
+
|
| 215 |
+
self.use_rel_pos = use_rel_pos
|
| 216 |
+
if self.use_rel_pos:
|
| 217 |
+
assert (
|
| 218 |
+
input_size is not None
|
| 219 |
+
), "Input size must be provided if using relative positional encoding."
|
| 220 |
+
# initialize relative positional embeddings
|
| 221 |
+
self.rel_pos_h = nn.Parameter(torch.zeros(2 * input_size[0] - 1, head_dim))
|
| 222 |
+
self.rel_pos_w = nn.Parameter(torch.zeros(2 * input_size[1] - 1, head_dim))
|
| 223 |
+
|
| 224 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 225 |
+
B, H, W, _ = x.shape
|
| 226 |
+
# qkv with shape (3, B, nHead, H * W, C)
|
| 227 |
+
qkv = self.qkv(x).reshape(B, H * W, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
|
| 228 |
+
# q, k, v with shape (B * nHead, H * W, C)
|
| 229 |
+
q, k, v = qkv.reshape(3, B * self.num_heads, H * W, -1).unbind(0)
|
| 230 |
+
|
| 231 |
+
attn = (q * self.scale) @ k.transpose(-2, -1)
|
| 232 |
+
|
| 233 |
+
if self.use_rel_pos:
|
| 234 |
+
attn = add_decomposed_rel_pos(attn, q, self.rel_pos_h, self.rel_pos_w, (H, W), (H, W))
|
| 235 |
+
|
| 236 |
+
attn = attn.softmax(dim=-1)
|
| 237 |
+
x = (attn @ v).view(B, self.num_heads, H, W, -1).permute(0, 2, 3, 1, 4).reshape(B, H, W, -1)
|
| 238 |
+
x = self.proj(x)
|
| 239 |
+
|
| 240 |
+
return x
|
| 241 |
+
|
| 242 |
+
|
| 243 |
+
def window_partition(x: torch.Tensor, window_size: int) -> Tuple[torch.Tensor, Tuple[int, int]]:
|
| 244 |
+
"""
|
| 245 |
+
Partition into non-overlapping windows with padding if needed.
|
| 246 |
+
Args:
|
| 247 |
+
x (tensor): input tokens with [B, H, W, C].
|
| 248 |
+
window_size (int): window size.
|
| 249 |
+
|
| 250 |
+
Returns:
|
| 251 |
+
windows: windows after partition with [B * num_windows, window_size, window_size, C].
|
| 252 |
+
(Hp, Wp): padded height and width before partition
|
| 253 |
+
"""
|
| 254 |
+
B, H, W, C = x.shape
|
| 255 |
+
|
| 256 |
+
pad_h = (window_size - H % window_size) % window_size
|
| 257 |
+
pad_w = (window_size - W % window_size) % window_size
|
| 258 |
+
if pad_h > 0 or pad_w > 0:
|
| 259 |
+
x = F.pad(x, (0, 0, 0, pad_w, 0, pad_h))
|
| 260 |
+
Hp, Wp = H + pad_h, W + pad_w
|
| 261 |
+
|
| 262 |
+
x = x.view(B, Hp // window_size, window_size, Wp // window_size, window_size, C)
|
| 263 |
+
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
|
| 264 |
+
return windows, (Hp, Wp)
|
| 265 |
+
|
| 266 |
+
|
| 267 |
+
def window_unpartition(
|
| 268 |
+
windows: torch.Tensor, window_size: int, pad_hw: Tuple[int, int], hw: Tuple[int, int]
|
| 269 |
+
) -> torch.Tensor:
|
| 270 |
+
"""
|
| 271 |
+
Window unpartition into original sequences and removing padding.
|
| 272 |
+
Args:
|
| 273 |
+
x (tensor): input tokens with [B * num_windows, window_size, window_size, C].
|
| 274 |
+
window_size (int): window size.
|
| 275 |
+
pad_hw (Tuple): padded height and width (Hp, Wp).
|
| 276 |
+
hw (Tuple): original height and width (H, W) before padding.
|
| 277 |
+
|
| 278 |
+
Returns:
|
| 279 |
+
x: unpartitioned sequences with [B, H, W, C].
|
| 280 |
+
"""
|
| 281 |
+
Hp, Wp = pad_hw
|
| 282 |
+
H, W = hw
|
| 283 |
+
B = windows.shape[0] // (Hp * Wp // window_size // window_size)
|
| 284 |
+
x = windows.view(B, Hp // window_size, Wp // window_size, window_size, window_size, -1)
|
| 285 |
+
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, Hp, Wp, -1)
|
| 286 |
+
|
| 287 |
+
if Hp > H or Wp > W:
|
| 288 |
+
x = x[:, :H, :W, :].contiguous()
|
| 289 |
+
return x
|
| 290 |
+
|
| 291 |
+
|
| 292 |
+
def get_rel_pos(q_size: int, k_size: int, rel_pos: torch.Tensor) -> torch.Tensor:
|
| 293 |
+
"""
|
| 294 |
+
Get relative positional embeddings according to the relative positions of
|
| 295 |
+
query and key sizes.
|
| 296 |
+
Args:
|
| 297 |
+
q_size (int): size of query q.
|
| 298 |
+
k_size (int): size of key k.
|
| 299 |
+
rel_pos (Tensor): relative position embeddings (L, C).
|
| 300 |
+
|
| 301 |
+
Returns:
|
| 302 |
+
Extracted positional embeddings according to relative positions.
|
| 303 |
+
"""
|
| 304 |
+
max_rel_dist = int(2 * max(q_size, k_size) - 1)
|
| 305 |
+
# Interpolate rel pos if needed.
|
| 306 |
+
if rel_pos.shape[0] != max_rel_dist:
|
| 307 |
+
# Interpolate rel pos.
|
| 308 |
+
rel_pos_resized = F.interpolate(
|
| 309 |
+
rel_pos.reshape(1, rel_pos.shape[0], -1).permute(0, 2, 1),
|
| 310 |
+
size=max_rel_dist,
|
| 311 |
+
mode="linear",
|
| 312 |
+
)
|
| 313 |
+
rel_pos_resized = rel_pos_resized.reshape(-1, max_rel_dist).permute(1, 0)
|
| 314 |
+
else:
|
| 315 |
+
rel_pos_resized = rel_pos
|
| 316 |
+
|
| 317 |
+
# Scale the coords with short length if shapes for q and k are different.
|
| 318 |
+
q_coords = torch.arange(q_size)[:, None] * max(k_size / q_size, 1.0)
|
| 319 |
+
k_coords = torch.arange(k_size)[None, :] * max(q_size / k_size, 1.0)
|
| 320 |
+
relative_coords = (q_coords - k_coords) + (k_size - 1) * max(q_size / k_size, 1.0)
|
| 321 |
+
|
| 322 |
+
return rel_pos_resized[relative_coords.long()]
|
| 323 |
+
|
| 324 |
+
|
| 325 |
+
def add_decomposed_rel_pos(
|
| 326 |
+
attn: torch.Tensor,
|
| 327 |
+
q: torch.Tensor,
|
| 328 |
+
rel_pos_h: torch.Tensor,
|
| 329 |
+
rel_pos_w: torch.Tensor,
|
| 330 |
+
q_size: Tuple[int, int],
|
| 331 |
+
k_size: Tuple[int, int],
|
| 332 |
+
) -> torch.Tensor:
|
| 333 |
+
"""
|
| 334 |
+
Calculate decomposed Relative Positional Embeddings from :paper:`mvitv2`.
|
| 335 |
+
https://github.com/facebookresearch/mvit/blob/19786631e330df9f3622e5402b4a419a263a2c80/mvit/models/attention.py # noqa B950
|
| 336 |
+
Args:
|
| 337 |
+
attn (Tensor): attention map.
|
| 338 |
+
q (Tensor): query q in the attention layer with shape (B, q_h * q_w, C).
|
| 339 |
+
rel_pos_h (Tensor): relative position embeddings (Lh, C) for height axis.
|
| 340 |
+
rel_pos_w (Tensor): relative position embeddings (Lw, C) for width axis.
|
| 341 |
+
q_size (Tuple): spatial sequence size of query q with (q_h, q_w).
|
| 342 |
+
k_size (Tuple): spatial sequence size of key k with (k_h, k_w).
|
| 343 |
+
|
| 344 |
+
Returns:
|
| 345 |
+
attn (Tensor): attention map with added relative positional embeddings.
|
| 346 |
+
"""
|
| 347 |
+
q_h, q_w = q_size
|
| 348 |
+
k_h, k_w = k_size
|
| 349 |
+
Rh = get_rel_pos(q_h, k_h, rel_pos_h)
|
| 350 |
+
Rw = get_rel_pos(q_w, k_w, rel_pos_w)
|
| 351 |
+
|
| 352 |
+
B, _, dim = q.shape
|
| 353 |
+
r_q = q.reshape(B, q_h, q_w, dim)
|
| 354 |
+
rel_h = torch.einsum("bhwc,hkc->bhwk", r_q, Rh)
|
| 355 |
+
rel_w = torch.einsum("bhwc,wkc->bhwk", r_q, Rw)
|
| 356 |
+
|
| 357 |
+
attn = (
|
| 358 |
+
attn.view(B, q_h, q_w, k_h, k_w) + rel_h[:, :, :, :, None] + rel_w[:, :, :, None, :]
|
| 359 |
+
).view(B, q_h * q_w, k_h * k_w)
|
| 360 |
+
|
| 361 |
+
return attn
|
| 362 |
+
|
| 363 |
+
|
| 364 |
+
class PatchEmbed(nn.Module):
|
| 365 |
+
"""
|
| 366 |
+
Image to Patch Embedding.
|
| 367 |
+
"""
|
| 368 |
+
|
| 369 |
+
def __init__(
|
| 370 |
+
self,
|
| 371 |
+
kernel_size: Tuple[int, int] = (16, 16),
|
| 372 |
+
stride: Tuple[int, int] = (16, 16),
|
| 373 |
+
padding: Tuple[int, int] = (0, 0),
|
| 374 |
+
in_chans: int = 3,
|
| 375 |
+
embed_dim: int = 768,
|
| 376 |
+
) -> None:
|
| 377 |
+
"""
|
| 378 |
+
Args:
|
| 379 |
+
kernel_size (Tuple): kernel size of the projection layer.
|
| 380 |
+
stride (Tuple): stride of the projection layer.
|
| 381 |
+
padding (Tuple): padding size of the projection layer.
|
| 382 |
+
in_chans (int): Number of input image channels.
|
| 383 |
+
embed_dim (int): embed_dim (int): Patch embedding dimension.
|
| 384 |
+
"""
|
| 385 |
+
super().__init__()
|
| 386 |
+
|
| 387 |
+
self.proj = nn.Conv2d(
|
| 388 |
+
in_chans, embed_dim, kernel_size=kernel_size, stride=stride, padding=padding
|
| 389 |
+
)
|
| 390 |
+
|
| 391 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 392 |
+
x = self.proj(x)
|
| 393 |
+
# B C H W -> B H W C
|
| 394 |
+
x = x.permute(0, 2, 3, 1)
|
| 395 |
+
return x
|
segment_anything/modeling/mask_decoder.py
ADDED
|
@@ -0,0 +1,177 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
from torch import nn
|
| 9 |
+
from torch.nn import functional as F
|
| 10 |
+
|
| 11 |
+
from typing import List, Tuple, Type
|
| 12 |
+
|
| 13 |
+
from .common import LayerNorm2d
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class MaskDecoder(nn.Module):
|
| 17 |
+
def __init__(
|
| 18 |
+
self,
|
| 19 |
+
*,
|
| 20 |
+
transformer_dim: int,
|
| 21 |
+
transformer: nn.Module,
|
| 22 |
+
num_multimask_outputs: int = 3,
|
| 23 |
+
activation: Type[nn.Module] = nn.GELU,
|
| 24 |
+
iou_head_depth: int = 3,
|
| 25 |
+
iou_head_hidden_dim: int = 256,
|
| 26 |
+
) -> None:
|
| 27 |
+
"""
|
| 28 |
+
Predicts masks given an image and prompt embeddings, using a
|
| 29 |
+
tranformer architecture.
|
| 30 |
+
|
| 31 |
+
Arguments:
|
| 32 |
+
transformer_dim (int): the channel dimension of the transformer
|
| 33 |
+
transformer (nn.Module): the transformer used to predict masks
|
| 34 |
+
num_multimask_outputs (int): the number of masks to predict
|
| 35 |
+
when disambiguating masks
|
| 36 |
+
activation (nn.Module): the type of activation to use when
|
| 37 |
+
upscaling masks
|
| 38 |
+
iou_head_depth (int): the depth of the MLP used to predict
|
| 39 |
+
mask quality
|
| 40 |
+
iou_head_hidden_dim (int): the hidden dimension of the MLP
|
| 41 |
+
used to predict mask quality
|
| 42 |
+
"""
|
| 43 |
+
super().__init__()
|
| 44 |
+
self.transformer_dim = transformer_dim
|
| 45 |
+
self.transformer = transformer
|
| 46 |
+
|
| 47 |
+
self.num_multimask_outputs = num_multimask_outputs
|
| 48 |
+
|
| 49 |
+
self.iou_token = nn.Embedding(1, transformer_dim)
|
| 50 |
+
self.num_mask_tokens = num_multimask_outputs + 1
|
| 51 |
+
self.mask_tokens = nn.Embedding(self.num_mask_tokens, transformer_dim)
|
| 52 |
+
|
| 53 |
+
self.output_upscaling = nn.Sequential(
|
| 54 |
+
nn.ConvTranspose2d(transformer_dim, transformer_dim // 4, kernel_size=2, stride=2),
|
| 55 |
+
LayerNorm2d(transformer_dim // 4),
|
| 56 |
+
activation(),
|
| 57 |
+
nn.ConvTranspose2d(transformer_dim // 4, transformer_dim // 8, kernel_size=2, stride=2),
|
| 58 |
+
activation(),
|
| 59 |
+
)
|
| 60 |
+
self.output_hypernetworks_mlps = nn.ModuleList(
|
| 61 |
+
[
|
| 62 |
+
MLP(transformer_dim, transformer_dim, transformer_dim // 8, 3)
|
| 63 |
+
for i in range(self.num_mask_tokens)
|
| 64 |
+
]
|
| 65 |
+
)
|
| 66 |
+
|
| 67 |
+
self.iou_prediction_head = MLP(
|
| 68 |
+
transformer_dim, iou_head_hidden_dim, self.num_mask_tokens, iou_head_depth
|
| 69 |
+
)
|
| 70 |
+
|
| 71 |
+
def forward(
|
| 72 |
+
self,
|
| 73 |
+
image_embeddings: torch.Tensor,
|
| 74 |
+
image_pe: torch.Tensor,
|
| 75 |
+
sparse_prompt_embeddings: torch.Tensor,
|
| 76 |
+
dense_prompt_embeddings: torch.Tensor,
|
| 77 |
+
multimask_output: bool,
|
| 78 |
+
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
|
| 79 |
+
"""
|
| 80 |
+
Predict masks given image and prompt embeddings.
|
| 81 |
+
|
| 82 |
+
Arguments:
|
| 83 |
+
image_embeddings (torch.Tensor): the embeddings from the image encoder
|
| 84 |
+
image_pe (torch.Tensor): positional encoding with the shape of image_embeddings
|
| 85 |
+
sparse_prompt_embeddings (torch.Tensor): the embeddings of the points and boxes
|
| 86 |
+
dense_prompt_embeddings (torch.Tensor): the embeddings of the mask inputs
|
| 87 |
+
multimask_output (bool): Whether to return multiple masks or a single
|
| 88 |
+
mask.
|
| 89 |
+
|
| 90 |
+
Returns:
|
| 91 |
+
torch.Tensor: batched predicted masks
|
| 92 |
+
torch.Tensor: batched predictions of mask quality
|
| 93 |
+
"""
|
| 94 |
+
masks, iou_pred, mask_tokens_out = self.predict_masks(
|
| 95 |
+
image_embeddings=image_embeddings,
|
| 96 |
+
image_pe=image_pe,
|
| 97 |
+
sparse_prompt_embeddings=sparse_prompt_embeddings,
|
| 98 |
+
dense_prompt_embeddings=dense_prompt_embeddings,
|
| 99 |
+
)
|
| 100 |
+
|
| 101 |
+
# Select the correct mask or masks for outptu
|
| 102 |
+
if multimask_output:
|
| 103 |
+
mask_slice = slice(1, None)
|
| 104 |
+
else:
|
| 105 |
+
mask_slice = slice(0, 1)
|
| 106 |
+
masks = masks[:, mask_slice, :, :]
|
| 107 |
+
mask_tokens_out = mask_tokens_out[:, mask_slice, :]
|
| 108 |
+
iou_pred = iou_pred[:, mask_slice]
|
| 109 |
+
|
| 110 |
+
# Prepare output
|
| 111 |
+
return masks, iou_pred, mask_tokens_out
|
| 112 |
+
|
| 113 |
+
def predict_masks(
|
| 114 |
+
self,
|
| 115 |
+
image_embeddings: torch.Tensor,
|
| 116 |
+
image_pe: torch.Tensor,
|
| 117 |
+
sparse_prompt_embeddings: torch.Tensor,
|
| 118 |
+
dense_prompt_embeddings: torch.Tensor,
|
| 119 |
+
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
|
| 120 |
+
"""Predicts masks. See 'forward' for more details."""
|
| 121 |
+
# Concatenate output tokens
|
| 122 |
+
output_tokens = torch.cat([self.iou_token.weight, self.mask_tokens.weight], dim=0)
|
| 123 |
+
output_tokens = output_tokens.unsqueeze(0).expand(sparse_prompt_embeddings.size(0), -1, -1)
|
| 124 |
+
tokens = torch.cat((output_tokens, sparse_prompt_embeddings), dim=1)
|
| 125 |
+
|
| 126 |
+
# Expand per-image data in batch direction to be per-mask
|
| 127 |
+
src = torch.repeat_interleave(image_embeddings, tokens.shape[0], dim=0)
|
| 128 |
+
src = src + dense_prompt_embeddings
|
| 129 |
+
pos_src = torch.repeat_interleave(image_pe, tokens.shape[0], dim=0)
|
| 130 |
+
b, c, h, w = src.shape
|
| 131 |
+
|
| 132 |
+
# Run the transformer
|
| 133 |
+
hs, src = self.transformer(src, pos_src, tokens)
|
| 134 |
+
iou_token_out = hs[:, 0, :]
|
| 135 |
+
mask_tokens_out = hs[:, 1 : (1 + self.num_mask_tokens), :]
|
| 136 |
+
|
| 137 |
+
# Upscale mask embeddings and predict masks using the mask tokens
|
| 138 |
+
src = src.transpose(1, 2).view(b, c, h, w)
|
| 139 |
+
upscaled_embedding = self.output_upscaling(src)
|
| 140 |
+
hyper_in_list: List[torch.Tensor] = []
|
| 141 |
+
for i in range(self.num_mask_tokens):
|
| 142 |
+
hyper_in_list.append(self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :]))
|
| 143 |
+
hyper_in = torch.stack(hyper_in_list, dim=1)
|
| 144 |
+
b, c, h, w = upscaled_embedding.shape
|
| 145 |
+
masks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(b, -1, h, w)
|
| 146 |
+
|
| 147 |
+
# Generate mask quality predictions
|
| 148 |
+
iou_pred = self.iou_prediction_head(iou_token_out)
|
| 149 |
+
|
| 150 |
+
return masks, iou_pred, mask_tokens_out
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
# Lightly adapted from
|
| 154 |
+
# https://github.com/facebookresearch/MaskFormer/blob/main/mask_former/modeling/transformer/transformer_predictor.py # noqa
|
| 155 |
+
class MLP(nn.Module):
|
| 156 |
+
def __init__(
|
| 157 |
+
self,
|
| 158 |
+
input_dim: int,
|
| 159 |
+
hidden_dim: int,
|
| 160 |
+
output_dim: int,
|
| 161 |
+
num_layers: int,
|
| 162 |
+
sigmoid_output: bool = False,
|
| 163 |
+
) -> None:
|
| 164 |
+
super().__init__()
|
| 165 |
+
self.num_layers = num_layers
|
| 166 |
+
h = [hidden_dim] * (num_layers - 1)
|
| 167 |
+
self.layers = nn.ModuleList(
|
| 168 |
+
nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim])
|
| 169 |
+
)
|
| 170 |
+
self.sigmoid_output = sigmoid_output
|
| 171 |
+
|
| 172 |
+
def forward(self, x):
|
| 173 |
+
for i, layer in enumerate(self.layers):
|
| 174 |
+
x = F.relu(layer(x)) if i < self.num_layers - 1 else layer(x)
|
| 175 |
+
if self.sigmoid_output:
|
| 176 |
+
x = F.sigmoid(x)
|
| 177 |
+
return x
|
segment_anything/modeling/prompt_encoder.py
ADDED
|
@@ -0,0 +1,214 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import numpy as np
|
| 8 |
+
import torch
|
| 9 |
+
from torch import nn
|
| 10 |
+
|
| 11 |
+
from typing import Any, Optional, Tuple, Type
|
| 12 |
+
|
| 13 |
+
from .common import LayerNorm2d
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class PromptEncoder(nn.Module):
|
| 17 |
+
def __init__(
|
| 18 |
+
self,
|
| 19 |
+
embed_dim: int,
|
| 20 |
+
image_embedding_size: Tuple[int, int],
|
| 21 |
+
input_image_size: Tuple[int, int],
|
| 22 |
+
mask_in_chans: int,
|
| 23 |
+
activation: Type[nn.Module] = nn.GELU,
|
| 24 |
+
) -> None:
|
| 25 |
+
"""
|
| 26 |
+
Encodes prompts for input to SAM's mask decoder.
|
| 27 |
+
|
| 28 |
+
Arguments:
|
| 29 |
+
embed_dim (int): The prompts' embedding dimension
|
| 30 |
+
image_embedding_size (tuple(int, int)): The spatial size of the
|
| 31 |
+
image embedding, as (H, W).
|
| 32 |
+
input_image_size (int): The padded size of the image as input
|
| 33 |
+
to the image encoder, as (H, W).
|
| 34 |
+
mask_in_chans (int): The number of hidden channels used for
|
| 35 |
+
encoding input masks.
|
| 36 |
+
activation (nn.Module): The activation to use when encoding
|
| 37 |
+
input masks.
|
| 38 |
+
"""
|
| 39 |
+
super().__init__()
|
| 40 |
+
self.embed_dim = embed_dim
|
| 41 |
+
self.input_image_size = input_image_size
|
| 42 |
+
self.image_embedding_size = image_embedding_size
|
| 43 |
+
self.pe_layer = PositionEmbeddingRandom(embed_dim // 2)
|
| 44 |
+
|
| 45 |
+
self.num_point_embeddings: int = 4 # pos/neg point + 2 box corners
|
| 46 |
+
point_embeddings = [nn.Embedding(1, embed_dim) for i in range(self.num_point_embeddings)]
|
| 47 |
+
self.point_embeddings = nn.ModuleList(point_embeddings)
|
| 48 |
+
self.not_a_point_embed = nn.Embedding(1, embed_dim)
|
| 49 |
+
|
| 50 |
+
self.mask_input_size = (4 * image_embedding_size[0], 4 * image_embedding_size[1])
|
| 51 |
+
self.mask_downscaling = nn.Sequential(
|
| 52 |
+
nn.Conv2d(1, mask_in_chans // 4, kernel_size=2, stride=2),
|
| 53 |
+
LayerNorm2d(mask_in_chans // 4),
|
| 54 |
+
activation(),
|
| 55 |
+
nn.Conv2d(mask_in_chans // 4, mask_in_chans, kernel_size=2, stride=2),
|
| 56 |
+
LayerNorm2d(mask_in_chans),
|
| 57 |
+
activation(),
|
| 58 |
+
nn.Conv2d(mask_in_chans, embed_dim, kernel_size=1),
|
| 59 |
+
)
|
| 60 |
+
self.no_mask_embed = nn.Embedding(1, embed_dim)
|
| 61 |
+
|
| 62 |
+
def get_dense_pe(self) -> torch.Tensor:
|
| 63 |
+
"""
|
| 64 |
+
Returns the positional encoding used to encode point prompts,
|
| 65 |
+
applied to a dense set of points the shape of the image encoding.
|
| 66 |
+
|
| 67 |
+
Returns:
|
| 68 |
+
torch.Tensor: Positional encoding with shape
|
| 69 |
+
1x(embed_dim)x(embedding_h)x(embedding_w)
|
| 70 |
+
"""
|
| 71 |
+
return self.pe_layer(self.image_embedding_size).unsqueeze(0)
|
| 72 |
+
|
| 73 |
+
def _embed_points(
|
| 74 |
+
self,
|
| 75 |
+
points: torch.Tensor,
|
| 76 |
+
labels: torch.Tensor,
|
| 77 |
+
pad: bool,
|
| 78 |
+
) -> torch.Tensor:
|
| 79 |
+
"""Embeds point prompts."""
|
| 80 |
+
points = points + 0.5 # Shift to center of pixel
|
| 81 |
+
if pad:
|
| 82 |
+
padding_point = torch.zeros((points.shape[0], 1, 2), device=points.device)
|
| 83 |
+
padding_label = -torch.ones((labels.shape[0], 1), device=labels.device)
|
| 84 |
+
points = torch.cat([points, padding_point], dim=1)
|
| 85 |
+
labels = torch.cat([labels, padding_label], dim=1)
|
| 86 |
+
point_embedding = self.pe_layer.forward_with_coords(points, self.input_image_size)
|
| 87 |
+
point_embedding[labels == -1] = 0.0
|
| 88 |
+
point_embedding[labels == -1] += self.not_a_point_embed.weight
|
| 89 |
+
point_embedding[labels == 0] += self.point_embeddings[0].weight
|
| 90 |
+
point_embedding[labels == 1] += self.point_embeddings[1].weight
|
| 91 |
+
return point_embedding
|
| 92 |
+
|
| 93 |
+
def _embed_boxes(self, boxes: torch.Tensor) -> torch.Tensor:
|
| 94 |
+
"""Embeds box prompts."""
|
| 95 |
+
boxes = boxes + 0.5 # Shift to center of pixel
|
| 96 |
+
coords = boxes.reshape(-1, 2, 2)
|
| 97 |
+
corner_embedding = self.pe_layer.forward_with_coords(coords, self.input_image_size)
|
| 98 |
+
corner_embedding[:, 0, :] += self.point_embeddings[2].weight
|
| 99 |
+
corner_embedding[:, 1, :] += self.point_embeddings[3].weight
|
| 100 |
+
return corner_embedding
|
| 101 |
+
|
| 102 |
+
def _embed_masks(self, masks: torch.Tensor) -> torch.Tensor:
|
| 103 |
+
"""Embeds mask inputs."""
|
| 104 |
+
mask_embedding = self.mask_downscaling(masks)
|
| 105 |
+
return mask_embedding
|
| 106 |
+
|
| 107 |
+
def _get_batch_size(
|
| 108 |
+
self,
|
| 109 |
+
points: Optional[Tuple[torch.Tensor, torch.Tensor]],
|
| 110 |
+
boxes: Optional[torch.Tensor],
|
| 111 |
+
masks: Optional[torch.Tensor],
|
| 112 |
+
) -> int:
|
| 113 |
+
"""
|
| 114 |
+
Gets the batch size of the output given the batch size of the input prompts.
|
| 115 |
+
"""
|
| 116 |
+
if points is not None:
|
| 117 |
+
return points[0].shape[0]
|
| 118 |
+
elif boxes is not None:
|
| 119 |
+
return boxes.shape[0]
|
| 120 |
+
elif masks is not None:
|
| 121 |
+
return masks.shape[0]
|
| 122 |
+
else:
|
| 123 |
+
return 1
|
| 124 |
+
|
| 125 |
+
def _get_device(self) -> torch.device:
|
| 126 |
+
return self.point_embeddings[0].weight.device
|
| 127 |
+
|
| 128 |
+
def forward(
|
| 129 |
+
self,
|
| 130 |
+
points: Optional[Tuple[torch.Tensor, torch.Tensor]],
|
| 131 |
+
boxes: Optional[torch.Tensor],
|
| 132 |
+
masks: Optional[torch.Tensor],
|
| 133 |
+
) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 134 |
+
"""
|
| 135 |
+
Embeds different types of prompts, returning both sparse and dense
|
| 136 |
+
embeddings.
|
| 137 |
+
|
| 138 |
+
Arguments:
|
| 139 |
+
points (tuple(torch.Tensor, torch.Tensor) or none): point coordinates
|
| 140 |
+
and labels to embed.
|
| 141 |
+
boxes (torch.Tensor or none): boxes to embed
|
| 142 |
+
masks (torch.Tensor or none): masks to embed
|
| 143 |
+
|
| 144 |
+
Returns:
|
| 145 |
+
torch.Tensor: sparse embeddings for the points and boxes, with shape
|
| 146 |
+
BxNx(embed_dim), where N is determined by the number of input points
|
| 147 |
+
and boxes.
|
| 148 |
+
torch.Tensor: dense embeddings for the masks, in the shape
|
| 149 |
+
Bx(embed_dim)x(embed_H)x(embed_W)
|
| 150 |
+
"""
|
| 151 |
+
bs = self._get_batch_size(points, boxes, masks)
|
| 152 |
+
sparse_embeddings = torch.empty((bs, 0, self.embed_dim), device=self._get_device())
|
| 153 |
+
if points is not None:
|
| 154 |
+
coords, labels = points
|
| 155 |
+
point_embeddings = self._embed_points(coords, labels, pad=(boxes is None))
|
| 156 |
+
sparse_embeddings = torch.cat([sparse_embeddings, point_embeddings], dim=1)
|
| 157 |
+
if boxes is not None:
|
| 158 |
+
box_embeddings = self._embed_boxes(boxes)
|
| 159 |
+
sparse_embeddings = torch.cat([sparse_embeddings, box_embeddings], dim=1)
|
| 160 |
+
|
| 161 |
+
if masks is not None:
|
| 162 |
+
dense_embeddings = self._embed_masks(masks)
|
| 163 |
+
else:
|
| 164 |
+
dense_embeddings = self.no_mask_embed.weight.reshape(1, -1, 1, 1).expand(
|
| 165 |
+
bs, -1, self.image_embedding_size[0], self.image_embedding_size[1]
|
| 166 |
+
)
|
| 167 |
+
|
| 168 |
+
return sparse_embeddings, dense_embeddings
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
class PositionEmbeddingRandom(nn.Module):
|
| 172 |
+
"""
|
| 173 |
+
Positional encoding using random spatial frequencies.
|
| 174 |
+
"""
|
| 175 |
+
|
| 176 |
+
def __init__(self, num_pos_feats: int = 64, scale: Optional[float] = None) -> None:
|
| 177 |
+
super().__init__()
|
| 178 |
+
if scale is None or scale <= 0.0:
|
| 179 |
+
scale = 1.0
|
| 180 |
+
self.register_buffer(
|
| 181 |
+
"positional_encoding_gaussian_matrix",
|
| 182 |
+
scale * torch.randn((2, num_pos_feats)),
|
| 183 |
+
)
|
| 184 |
+
|
| 185 |
+
def _pe_encoding(self, coords: torch.Tensor) -> torch.Tensor:
|
| 186 |
+
"""Positionally encode points that are normalized to [0,1]."""
|
| 187 |
+
# assuming coords are in [0, 1]^2 square and have d_1 x ... x d_n x 2 shape
|
| 188 |
+
coords = 2 * coords - 1
|
| 189 |
+
coords = coords @ self.positional_encoding_gaussian_matrix
|
| 190 |
+
coords = 2 * np.pi * coords
|
| 191 |
+
# outputs d_1 x ... x d_n x C shape
|
| 192 |
+
return torch.cat([torch.sin(coords), torch.cos(coords)], dim=-1)
|
| 193 |
+
|
| 194 |
+
def forward(self, size: Tuple[int, int]) -> torch.Tensor:
|
| 195 |
+
"""Generate positional encoding for a grid of the specified size."""
|
| 196 |
+
h, w = size
|
| 197 |
+
device: Any = self.positional_encoding_gaussian_matrix.device
|
| 198 |
+
grid = torch.ones((h, w), device=device, dtype=torch.float32)
|
| 199 |
+
y_embed = grid.cumsum(dim=0) - 0.5
|
| 200 |
+
x_embed = grid.cumsum(dim=1) - 0.5
|
| 201 |
+
y_embed = y_embed / h
|
| 202 |
+
x_embed = x_embed / w
|
| 203 |
+
|
| 204 |
+
pe = self._pe_encoding(torch.stack([x_embed, y_embed], dim=-1))
|
| 205 |
+
return pe.permute(2, 0, 1) # C x H x W
|
| 206 |
+
|
| 207 |
+
def forward_with_coords(
|
| 208 |
+
self, coords_input: torch.Tensor, image_size: Tuple[int, int]
|
| 209 |
+
) -> torch.Tensor:
|
| 210 |
+
"""Positionally encode points that are not normalized to [0,1]."""
|
| 211 |
+
coords = coords_input.clone()
|
| 212 |
+
coords[:, :, 0] = coords[:, :, 0] / image_size[1]
|
| 213 |
+
coords[:, :, 1] = coords[:, :, 1] / image_size[0]
|
| 214 |
+
return self._pe_encoding(coords.to(torch.float)) # B x N x C
|
segment_anything/modeling/sam.py
ADDED
|
@@ -0,0 +1,175 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
from torch import nn
|
| 9 |
+
from torch.nn import functional as F
|
| 10 |
+
|
| 11 |
+
from typing import Any, Dict, List, Tuple
|
| 12 |
+
|
| 13 |
+
from .image_encoder import ImageEncoderViT
|
| 14 |
+
from .mask_decoder import MaskDecoder
|
| 15 |
+
from .prompt_encoder import PromptEncoder
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class Sam(nn.Module):
|
| 19 |
+
mask_threshold: float = 0.0
|
| 20 |
+
image_format: str = "RGB"
|
| 21 |
+
|
| 22 |
+
def __init__(
|
| 23 |
+
self,
|
| 24 |
+
image_encoder: ImageEncoderViT,
|
| 25 |
+
prompt_encoder: PromptEncoder,
|
| 26 |
+
mask_decoder: MaskDecoder,
|
| 27 |
+
pixel_mean: List[float] = [123.675, 116.28, 103.53],
|
| 28 |
+
pixel_std: List[float] = [58.395, 57.12, 57.375],
|
| 29 |
+
) -> None:
|
| 30 |
+
"""
|
| 31 |
+
SAM predicts object masks from an image and input prompts.
|
| 32 |
+
|
| 33 |
+
Arguments:
|
| 34 |
+
image_encoder (ImageEncoderViT): The backbone used to encode the
|
| 35 |
+
image into image embeddings that allow for efficient mask prediction.
|
| 36 |
+
prompt_encoder (PromptEncoder): Encodes various types of input prompts.
|
| 37 |
+
mask_decoder (MaskDecoder): Predicts masks from the image embeddings
|
| 38 |
+
and encoded prompts.
|
| 39 |
+
pixel_mean (list(float)): Mean values for normalizing pixels in the input image.
|
| 40 |
+
pixel_std (list(float)): Std values for normalizing pixels in the input image.
|
| 41 |
+
"""
|
| 42 |
+
super().__init__()
|
| 43 |
+
self.image_encoder = image_encoder
|
| 44 |
+
self.prompt_encoder = prompt_encoder
|
| 45 |
+
self.mask_decoder = mask_decoder
|
| 46 |
+
self.register_buffer("pixel_mean", torch.Tensor(pixel_mean).view(-1, 1, 1), False)
|
| 47 |
+
self.register_buffer("pixel_std", torch.Tensor(pixel_std).view(-1, 1, 1), False)
|
| 48 |
+
|
| 49 |
+
@property
|
| 50 |
+
def device(self) -> Any:
|
| 51 |
+
return self.pixel_mean.device
|
| 52 |
+
|
| 53 |
+
@torch.no_grad()
|
| 54 |
+
def forward(
|
| 55 |
+
self,
|
| 56 |
+
batched_input: List[Dict[str, Any]],
|
| 57 |
+
multimask_output: bool,
|
| 58 |
+
) -> List[Dict[str, torch.Tensor]]:
|
| 59 |
+
"""
|
| 60 |
+
Predicts masks end-to-end from provided images and prompts.
|
| 61 |
+
If prompts are not known in advance, using SamPredictor is
|
| 62 |
+
recommended over calling the model directly.
|
| 63 |
+
|
| 64 |
+
Arguments:
|
| 65 |
+
batched_input (list(dict)): A list over input images, each a
|
| 66 |
+
dictionary with the following keys. A prompt key can be
|
| 67 |
+
excluded if it is not present.
|
| 68 |
+
'image': The image as a torch tensor in 3xHxW format,
|
| 69 |
+
already transformed for input to the model.
|
| 70 |
+
'original_size': (tuple(int, int)) The original size of
|
| 71 |
+
the image before transformation, as (H, W).
|
| 72 |
+
'point_coords': (torch.Tensor) Batched point prompts for
|
| 73 |
+
this image, with shape BxNx2. Already transformed to the
|
| 74 |
+
input frame of the model.
|
| 75 |
+
'point_labels': (torch.Tensor) Batched labels for point prompts,
|
| 76 |
+
with shape BxN.
|
| 77 |
+
'boxes': (torch.Tensor) Batched box inputs, with shape Bx4.
|
| 78 |
+
Already transformed to the input frame of the model.
|
| 79 |
+
'mask_inputs': (torch.Tensor) Batched mask inputs to the model,
|
| 80 |
+
in the form Bx1xHxW.
|
| 81 |
+
multimask_output (bool): Whether the model should predict multiple
|
| 82 |
+
disambiguating masks, or return a single mask.
|
| 83 |
+
|
| 84 |
+
Returns:
|
| 85 |
+
(list(dict)): A list over input images, where each element is
|
| 86 |
+
as dictionary with the following keys.
|
| 87 |
+
'masks': (torch.Tensor) Batched binary mask predictions,
|
| 88 |
+
with shape BxCxHxW, where B is the number of input promts,
|
| 89 |
+
C is determiend by multimask_output, and (H, W) is the
|
| 90 |
+
original size of the image.
|
| 91 |
+
'iou_predictions': (torch.Tensor) The model's predictions
|
| 92 |
+
of mask quality, in shape BxC.
|
| 93 |
+
'low_res_logits': (torch.Tensor) Low resolution logits with
|
| 94 |
+
shape BxCxHxW, where H=W=256. Can be passed as mask input
|
| 95 |
+
to subsequent iterations of prediction.
|
| 96 |
+
"""
|
| 97 |
+
input_images = torch.stack([self.preprocess(x["image"]) for x in batched_input], dim=0)
|
| 98 |
+
image_embeddings = self.image_encoder(input_images)
|
| 99 |
+
|
| 100 |
+
outputs = []
|
| 101 |
+
for image_record, curr_embedding in zip(batched_input, image_embeddings):
|
| 102 |
+
if "point_coords" in image_record:
|
| 103 |
+
points = (image_record["point_coords"], image_record["point_labels"])
|
| 104 |
+
else:
|
| 105 |
+
points = None
|
| 106 |
+
sparse_embeddings, dense_embeddings = self.prompt_encoder(
|
| 107 |
+
points=points,
|
| 108 |
+
boxes=image_record.get("boxes", None),
|
| 109 |
+
masks=image_record.get("mask_inputs", None),
|
| 110 |
+
)
|
| 111 |
+
low_res_masks, iou_predictions, feats = self.mask_decoder(
|
| 112 |
+
image_embeddings=curr_embedding.unsqueeze(0),
|
| 113 |
+
image_pe=self.prompt_encoder.get_dense_pe(),
|
| 114 |
+
sparse_prompt_embeddings=sparse_embeddings,
|
| 115 |
+
dense_prompt_embeddings=dense_embeddings,
|
| 116 |
+
multimask_output=multimask_output,
|
| 117 |
+
)
|
| 118 |
+
masks = self.postprocess_masks(
|
| 119 |
+
low_res_masks,
|
| 120 |
+
input_size=image_record["image"].shape[-2:],
|
| 121 |
+
original_size=image_record["original_size"],
|
| 122 |
+
)
|
| 123 |
+
masks = masks > self.mask_threshold
|
| 124 |
+
outputs.append(
|
| 125 |
+
{
|
| 126 |
+
"masks": masks,
|
| 127 |
+
"iou_predictions": iou_predictions,
|
| 128 |
+
"low_res_logits": low_res_masks,
|
| 129 |
+
"feats": feats,
|
| 130 |
+
}
|
| 131 |
+
)
|
| 132 |
+
return outputs
|
| 133 |
+
|
| 134 |
+
def postprocess_masks(
|
| 135 |
+
self,
|
| 136 |
+
masks: torch.Tensor,
|
| 137 |
+
input_size: Tuple[int, ...],
|
| 138 |
+
original_size: Tuple[int, ...],
|
| 139 |
+
) -> torch.Tensor:
|
| 140 |
+
"""
|
| 141 |
+
Remove padding and upscale masks to the original image size.
|
| 142 |
+
|
| 143 |
+
Arguments:
|
| 144 |
+
masks (torch.Tensor): Batched masks from the mask_decoder,
|
| 145 |
+
in BxCxHxW format.
|
| 146 |
+
input_size (tuple(int, int)): The size of the image input to the
|
| 147 |
+
model, in (H, W) format. Used to remove padding.
|
| 148 |
+
original_size (tuple(int, int)): The original size of the image
|
| 149 |
+
before resizing for input to the model, in (H, W) format.
|
| 150 |
+
|
| 151 |
+
Returns:
|
| 152 |
+
(torch.Tensor): Batched masks in BxCxHxW format, where (H, W)
|
| 153 |
+
is given by original_size.
|
| 154 |
+
"""
|
| 155 |
+
masks = F.interpolate(
|
| 156 |
+
masks,
|
| 157 |
+
(self.image_encoder.img_size, self.image_encoder.img_size),
|
| 158 |
+
mode="bilinear",
|
| 159 |
+
align_corners=False,
|
| 160 |
+
)
|
| 161 |
+
masks = masks[..., : input_size[0], : input_size[1]]
|
| 162 |
+
masks = F.interpolate(masks, original_size, mode="bilinear", align_corners=False)
|
| 163 |
+
return masks
|
| 164 |
+
|
| 165 |
+
def preprocess(self, x: torch.Tensor) -> torch.Tensor:
|
| 166 |
+
"""Normalize pixel values and pad to a square input."""
|
| 167 |
+
# Normalize colors
|
| 168 |
+
x = (x - self.pixel_mean) / self.pixel_std
|
| 169 |
+
|
| 170 |
+
# Pad
|
| 171 |
+
h, w = x.shape[-2:]
|
| 172 |
+
padh = self.image_encoder.img_size - h
|
| 173 |
+
padw = self.image_encoder.img_size - w
|
| 174 |
+
x = F.pad(x, (0, padw, 0, padh))
|
| 175 |
+
return x
|
segment_anything/modeling/transformer.py
ADDED
|
@@ -0,0 +1,240 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
from torch import Tensor, nn
|
| 9 |
+
|
| 10 |
+
import math
|
| 11 |
+
from typing import Tuple, Type
|
| 12 |
+
|
| 13 |
+
from .common import MLPBlock
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class TwoWayTransformer(nn.Module):
|
| 17 |
+
def __init__(
|
| 18 |
+
self,
|
| 19 |
+
depth: int,
|
| 20 |
+
embedding_dim: int,
|
| 21 |
+
num_heads: int,
|
| 22 |
+
mlp_dim: int,
|
| 23 |
+
activation: Type[nn.Module] = nn.ReLU,
|
| 24 |
+
attention_downsample_rate: int = 2,
|
| 25 |
+
) -> None:
|
| 26 |
+
"""
|
| 27 |
+
A transformer decoder that attends to an input image using
|
| 28 |
+
queries whose positional embedding is supplied.
|
| 29 |
+
|
| 30 |
+
Args:
|
| 31 |
+
depth (int): number of layers in the transformer
|
| 32 |
+
embedding_dim (int): the channel dimension for the input embeddings
|
| 33 |
+
num_heads (int): the number of heads for multihead attention. Must
|
| 34 |
+
divide embedding_dim
|
| 35 |
+
mlp_dim (int): the channel dimension internal to the MLP block
|
| 36 |
+
activation (nn.Module): the activation to use in the MLP block
|
| 37 |
+
"""
|
| 38 |
+
super().__init__()
|
| 39 |
+
self.depth = depth
|
| 40 |
+
self.embedding_dim = embedding_dim
|
| 41 |
+
self.num_heads = num_heads
|
| 42 |
+
self.mlp_dim = mlp_dim
|
| 43 |
+
self.layers = nn.ModuleList()
|
| 44 |
+
|
| 45 |
+
for i in range(depth):
|
| 46 |
+
self.layers.append(
|
| 47 |
+
TwoWayAttentionBlock(
|
| 48 |
+
embedding_dim=embedding_dim,
|
| 49 |
+
num_heads=num_heads,
|
| 50 |
+
mlp_dim=mlp_dim,
|
| 51 |
+
activation=activation,
|
| 52 |
+
attention_downsample_rate=attention_downsample_rate,
|
| 53 |
+
skip_first_layer_pe=(i == 0),
|
| 54 |
+
)
|
| 55 |
+
)
|
| 56 |
+
|
| 57 |
+
self.final_attn_token_to_image = Attention(
|
| 58 |
+
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
|
| 59 |
+
)
|
| 60 |
+
self.norm_final_attn = nn.LayerNorm(embedding_dim)
|
| 61 |
+
|
| 62 |
+
def forward(
|
| 63 |
+
self,
|
| 64 |
+
image_embedding: Tensor,
|
| 65 |
+
image_pe: Tensor,
|
| 66 |
+
point_embedding: Tensor,
|
| 67 |
+
) -> Tuple[Tensor, Tensor]:
|
| 68 |
+
"""
|
| 69 |
+
Args:
|
| 70 |
+
image_embedding (torch.Tensor): image to attend to. Should be shape
|
| 71 |
+
B x embedding_dim x h x w for any h and w.
|
| 72 |
+
image_pe (torch.Tensor): the positional encoding to add to the image. Must
|
| 73 |
+
have the same shape as image_embedding.
|
| 74 |
+
point_embedding (torch.Tensor): the embedding to add to the query points.
|
| 75 |
+
Must have shape B x N_points x embedding_dim for any N_points.
|
| 76 |
+
|
| 77 |
+
Returns:
|
| 78 |
+
torch.Tensor: the processed point_embedding
|
| 79 |
+
torch.Tensor: the processed image_embedding
|
| 80 |
+
"""
|
| 81 |
+
# BxCxHxW -> BxHWxC == B x N_image_tokens x C
|
| 82 |
+
bs, c, h, w = image_embedding.shape
|
| 83 |
+
image_embedding = image_embedding.flatten(2).permute(0, 2, 1)
|
| 84 |
+
image_pe = image_pe.flatten(2).permute(0, 2, 1)
|
| 85 |
+
|
| 86 |
+
# Prepare queries
|
| 87 |
+
queries = point_embedding
|
| 88 |
+
keys = image_embedding
|
| 89 |
+
|
| 90 |
+
# Apply transformer blocks and final layernorm
|
| 91 |
+
for layer in self.layers:
|
| 92 |
+
queries, keys = layer(
|
| 93 |
+
queries=queries,
|
| 94 |
+
keys=keys,
|
| 95 |
+
query_pe=point_embedding,
|
| 96 |
+
key_pe=image_pe,
|
| 97 |
+
)
|
| 98 |
+
|
| 99 |
+
# Apply the final attenion layer from the points to the image
|
| 100 |
+
q = queries + point_embedding
|
| 101 |
+
k = keys + image_pe
|
| 102 |
+
attn_out = self.final_attn_token_to_image(q=q, k=k, v=keys)
|
| 103 |
+
queries = queries + attn_out
|
| 104 |
+
queries = self.norm_final_attn(queries)
|
| 105 |
+
|
| 106 |
+
return queries, keys
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
class TwoWayAttentionBlock(nn.Module):
|
| 110 |
+
def __init__(
|
| 111 |
+
self,
|
| 112 |
+
embedding_dim: int,
|
| 113 |
+
num_heads: int,
|
| 114 |
+
mlp_dim: int = 2048,
|
| 115 |
+
activation: Type[nn.Module] = nn.ReLU,
|
| 116 |
+
attention_downsample_rate: int = 2,
|
| 117 |
+
skip_first_layer_pe: bool = False,
|
| 118 |
+
) -> None:
|
| 119 |
+
"""
|
| 120 |
+
A transformer block with four layers: (1) self-attention of sparse
|
| 121 |
+
inputs, (2) cross attention of sparse inputs to dense inputs, (3) mlp
|
| 122 |
+
block on sparse inputs, and (4) cross attention of dense inputs to sparse
|
| 123 |
+
inputs.
|
| 124 |
+
|
| 125 |
+
Arguments:
|
| 126 |
+
embedding_dim (int): the channel dimension of the embeddings
|
| 127 |
+
num_heads (int): the number of heads in the attention layers
|
| 128 |
+
mlp_dim (int): the hidden dimension of the mlp block
|
| 129 |
+
activation (nn.Module): the activation of the mlp block
|
| 130 |
+
skip_first_layer_pe (bool): skip the PE on the first layer
|
| 131 |
+
"""
|
| 132 |
+
super().__init__()
|
| 133 |
+
self.self_attn = Attention(embedding_dim, num_heads)
|
| 134 |
+
self.norm1 = nn.LayerNorm(embedding_dim)
|
| 135 |
+
|
| 136 |
+
self.cross_attn_token_to_image = Attention(
|
| 137 |
+
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
|
| 138 |
+
)
|
| 139 |
+
self.norm2 = nn.LayerNorm(embedding_dim)
|
| 140 |
+
|
| 141 |
+
self.mlp = MLPBlock(embedding_dim, mlp_dim, activation)
|
| 142 |
+
self.norm3 = nn.LayerNorm(embedding_dim)
|
| 143 |
+
|
| 144 |
+
self.norm4 = nn.LayerNorm(embedding_dim)
|
| 145 |
+
self.cross_attn_image_to_token = Attention(
|
| 146 |
+
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
|
| 147 |
+
)
|
| 148 |
+
|
| 149 |
+
self.skip_first_layer_pe = skip_first_layer_pe
|
| 150 |
+
|
| 151 |
+
def forward(
|
| 152 |
+
self, queries: Tensor, keys: Tensor, query_pe: Tensor, key_pe: Tensor
|
| 153 |
+
) -> Tuple[Tensor, Tensor]:
|
| 154 |
+
# Self attention block
|
| 155 |
+
if self.skip_first_layer_pe:
|
| 156 |
+
queries = self.self_attn(q=queries, k=queries, v=queries)
|
| 157 |
+
else:
|
| 158 |
+
q = queries + query_pe
|
| 159 |
+
attn_out = self.self_attn(q=q, k=q, v=queries)
|
| 160 |
+
queries = queries + attn_out
|
| 161 |
+
queries = self.norm1(queries)
|
| 162 |
+
|
| 163 |
+
# Cross attention block, tokens attending to image embedding
|
| 164 |
+
q = queries + query_pe
|
| 165 |
+
k = keys + key_pe
|
| 166 |
+
attn_out = self.cross_attn_token_to_image(q=q, k=k, v=keys)
|
| 167 |
+
queries = queries + attn_out
|
| 168 |
+
queries = self.norm2(queries)
|
| 169 |
+
|
| 170 |
+
# MLP block
|
| 171 |
+
mlp_out = self.mlp(queries)
|
| 172 |
+
queries = queries + mlp_out
|
| 173 |
+
queries = self.norm3(queries)
|
| 174 |
+
|
| 175 |
+
# Cross attention block, image embedding attending to tokens
|
| 176 |
+
q = queries + query_pe
|
| 177 |
+
k = keys + key_pe
|
| 178 |
+
attn_out = self.cross_attn_image_to_token(q=k, k=q, v=queries)
|
| 179 |
+
keys = keys + attn_out
|
| 180 |
+
keys = self.norm4(keys)
|
| 181 |
+
|
| 182 |
+
return queries, keys
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
class Attention(nn.Module):
|
| 186 |
+
"""
|
| 187 |
+
An attention layer that allows for downscaling the size of the embedding
|
| 188 |
+
after projection to queries, keys, and values.
|
| 189 |
+
"""
|
| 190 |
+
|
| 191 |
+
def __init__(
|
| 192 |
+
self,
|
| 193 |
+
embedding_dim: int,
|
| 194 |
+
num_heads: int,
|
| 195 |
+
downsample_rate: int = 1,
|
| 196 |
+
) -> None:
|
| 197 |
+
super().__init__()
|
| 198 |
+
self.embedding_dim = embedding_dim
|
| 199 |
+
self.internal_dim = embedding_dim // downsample_rate
|
| 200 |
+
self.num_heads = num_heads
|
| 201 |
+
assert self.internal_dim % num_heads == 0, "num_heads must divide embedding_dim."
|
| 202 |
+
|
| 203 |
+
self.q_proj = nn.Linear(embedding_dim, self.internal_dim)
|
| 204 |
+
self.k_proj = nn.Linear(embedding_dim, self.internal_dim)
|
| 205 |
+
self.v_proj = nn.Linear(embedding_dim, self.internal_dim)
|
| 206 |
+
self.out_proj = nn.Linear(self.internal_dim, embedding_dim)
|
| 207 |
+
|
| 208 |
+
def _separate_heads(self, x: Tensor, num_heads: int) -> Tensor:
|
| 209 |
+
b, n, c = x.shape
|
| 210 |
+
x = x.reshape(b, n, num_heads, c // num_heads)
|
| 211 |
+
return x.transpose(1, 2) # B x N_heads x N_tokens x C_per_head
|
| 212 |
+
|
| 213 |
+
def _recombine_heads(self, x: Tensor) -> Tensor:
|
| 214 |
+
b, n_heads, n_tokens, c_per_head = x.shape
|
| 215 |
+
x = x.transpose(1, 2)
|
| 216 |
+
return x.reshape(b, n_tokens, n_heads * c_per_head) # B x N_tokens x C
|
| 217 |
+
|
| 218 |
+
def forward(self, q: Tensor, k: Tensor, v: Tensor) -> Tensor:
|
| 219 |
+
# Input projections
|
| 220 |
+
q = self.q_proj(q)
|
| 221 |
+
k = self.k_proj(k)
|
| 222 |
+
v = self.v_proj(v)
|
| 223 |
+
|
| 224 |
+
# Separate into heads
|
| 225 |
+
q = self._separate_heads(q, self.num_heads)
|
| 226 |
+
k = self._separate_heads(k, self.num_heads)
|
| 227 |
+
v = self._separate_heads(v, self.num_heads)
|
| 228 |
+
|
| 229 |
+
# Attention
|
| 230 |
+
_, _, _, c_per_head = q.shape
|
| 231 |
+
attn = q @ k.permute(0, 1, 3, 2) # B x N_heads x N_tokens x N_tokens
|
| 232 |
+
attn = attn / math.sqrt(c_per_head)
|
| 233 |
+
attn = torch.softmax(attn, dim=-1)
|
| 234 |
+
|
| 235 |
+
# Get output
|
| 236 |
+
out = attn @ v
|
| 237 |
+
out = self._recombine_heads(out)
|
| 238 |
+
out = self.out_proj(out)
|
| 239 |
+
|
| 240 |
+
return out
|
segment_anything/predictor.py
ADDED
|
@@ -0,0 +1,269 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import numpy as np
|
| 8 |
+
import torch
|
| 9 |
+
|
| 10 |
+
from segment_anything.modeling import Sam
|
| 11 |
+
|
| 12 |
+
from typing import Optional, Tuple
|
| 13 |
+
|
| 14 |
+
from .utils.transforms import ResizeLongestSide
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class SamPredictor:
|
| 18 |
+
def __init__(
|
| 19 |
+
self,
|
| 20 |
+
sam_model: Sam,
|
| 21 |
+
) -> None:
|
| 22 |
+
"""
|
| 23 |
+
Uses SAM to calculate the image embedding for an image, and then
|
| 24 |
+
allow repeated, efficient mask prediction given prompts.
|
| 25 |
+
|
| 26 |
+
Arguments:
|
| 27 |
+
sam_model (Sam): The model to use for mask prediction.
|
| 28 |
+
"""
|
| 29 |
+
super().__init__()
|
| 30 |
+
self.model = sam_model
|
| 31 |
+
self.transform = ResizeLongestSide(sam_model.image_encoder.img_size)
|
| 32 |
+
self.reset_image()
|
| 33 |
+
|
| 34 |
+
def set_image(
|
| 35 |
+
self,
|
| 36 |
+
image: np.ndarray,
|
| 37 |
+
image_format: str = "RGB",
|
| 38 |
+
) -> None:
|
| 39 |
+
"""
|
| 40 |
+
Calculates the image embeddings for the provided image, allowing
|
| 41 |
+
masks to be predicted with the 'predict' method.
|
| 42 |
+
|
| 43 |
+
Arguments:
|
| 44 |
+
image (np.ndarray): The image for calculating masks. Expects an
|
| 45 |
+
image in HWC uint8 format, with pixel values in [0, 255].
|
| 46 |
+
image_format (str): The color format of the image, in ['RGB', 'BGR'].
|
| 47 |
+
"""
|
| 48 |
+
assert image_format in [
|
| 49 |
+
"RGB",
|
| 50 |
+
"BGR",
|
| 51 |
+
], f"image_format must be in ['RGB', 'BGR'], is {image_format}."
|
| 52 |
+
if image_format != self.model.image_format:
|
| 53 |
+
image = image[..., ::-1]
|
| 54 |
+
|
| 55 |
+
# Transform the image to the form expected by the model
|
| 56 |
+
input_image = self.transform.apply_image(image)
|
| 57 |
+
input_image_torch = torch.as_tensor(input_image, device=self.device)
|
| 58 |
+
input_image_torch = input_image_torch.permute(2, 0, 1).contiguous()[None, :, :, :]
|
| 59 |
+
|
| 60 |
+
self.set_torch_image(input_image_torch, image.shape[:2])
|
| 61 |
+
|
| 62 |
+
@torch.no_grad()
|
| 63 |
+
def set_torch_image(
|
| 64 |
+
self,
|
| 65 |
+
transformed_image: torch.Tensor,
|
| 66 |
+
original_image_size: Tuple[int, ...],
|
| 67 |
+
) -> None:
|
| 68 |
+
"""
|
| 69 |
+
Calculates the image embeddings for the provided image, allowing
|
| 70 |
+
masks to be predicted with the 'predict' method. Expects the input
|
| 71 |
+
image to be already transformed to the format expected by the model.
|
| 72 |
+
|
| 73 |
+
Arguments:
|
| 74 |
+
transformed_image (torch.Tensor): The input image, with shape
|
| 75 |
+
1x3xHxW, which has been transformed with ResizeLongestSide.
|
| 76 |
+
original_image_size (tuple(int, int)): The size of the image
|
| 77 |
+
before transformation, in (H, W) format.
|
| 78 |
+
"""
|
| 79 |
+
assert (
|
| 80 |
+
len(transformed_image.shape) == 4
|
| 81 |
+
and transformed_image.shape[1] == 3
|
| 82 |
+
and max(*transformed_image.shape[2:]) == self.model.image_encoder.img_size
|
| 83 |
+
), f"set_torch_image input must be BCHW with long side {self.model.image_encoder.img_size}."
|
| 84 |
+
self.reset_image()
|
| 85 |
+
|
| 86 |
+
self.original_size = original_image_size
|
| 87 |
+
self.input_size = tuple(transformed_image.shape[-2:])
|
| 88 |
+
input_image = self.model.preprocess(transformed_image)
|
| 89 |
+
self.features = self.model.image_encoder(input_image)
|
| 90 |
+
self.is_image_set = True
|
| 91 |
+
|
| 92 |
+
def predict(
|
| 93 |
+
self,
|
| 94 |
+
point_coords: Optional[np.ndarray] = None,
|
| 95 |
+
point_labels: Optional[np.ndarray] = None,
|
| 96 |
+
box: Optional[np.ndarray] = None,
|
| 97 |
+
mask_input: Optional[np.ndarray] = None,
|
| 98 |
+
multimask_output: bool = True,
|
| 99 |
+
return_logits: bool = False,
|
| 100 |
+
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
|
| 101 |
+
"""
|
| 102 |
+
Predict masks for the given input prompts, using the currently set image.
|
| 103 |
+
|
| 104 |
+
Arguments:
|
| 105 |
+
point_coords (np.ndarray or None): A Nx2 array of point prompts to the
|
| 106 |
+
model. Each point is in (X,Y) in pixels.
|
| 107 |
+
point_labels (np.ndarray or None): A length N array of labels for the
|
| 108 |
+
point prompts. 1 indicates a foreground point and 0 indicates a
|
| 109 |
+
background point.
|
| 110 |
+
box (np.ndarray or None): A length 4 array given a box prompt to the
|
| 111 |
+
model, in XYXY format.
|
| 112 |
+
mask_input (np.ndarray): A low resolution mask input to the model, typically
|
| 113 |
+
coming from a previous prediction iteration. Has form 1xHxW, where
|
| 114 |
+
for SAM, H=W=256.
|
| 115 |
+
multimask_output (bool): If true, the model will return three masks.
|
| 116 |
+
For ambiguous input prompts (such as a single click), this will often
|
| 117 |
+
produce better masks than a single prediction. If only a single
|
| 118 |
+
mask is needed, the model's predicted quality score can be used
|
| 119 |
+
to select the best mask. For non-ambiguous prompts, such as multiple
|
| 120 |
+
input prompts, multimask_output=False can give better results.
|
| 121 |
+
return_logits (bool): If true, returns un-thresholded masks logits
|
| 122 |
+
instead of a binary mask.
|
| 123 |
+
|
| 124 |
+
Returns:
|
| 125 |
+
(np.ndarray): The output masks in CxHxW format, where C is the
|
| 126 |
+
number of masks, and (H, W) is the original image size.
|
| 127 |
+
(np.ndarray): An array of length C containing the model's
|
| 128 |
+
predictions for the quality of each mask.
|
| 129 |
+
(np.ndarray): An array of shape CxHxW, where C is the number
|
| 130 |
+
of masks and H=W=256. These low resolution logits can be passed to
|
| 131 |
+
a subsequent iteration as mask input.
|
| 132 |
+
"""
|
| 133 |
+
if not self.is_image_set:
|
| 134 |
+
raise RuntimeError("An image must be set with .set_image(...) before mask prediction.")
|
| 135 |
+
|
| 136 |
+
# Transform input prompts
|
| 137 |
+
coords_torch, labels_torch, box_torch, mask_input_torch = None, None, None, None
|
| 138 |
+
if point_coords is not None:
|
| 139 |
+
assert (
|
| 140 |
+
point_labels is not None
|
| 141 |
+
), "point_labels must be supplied if point_coords is supplied."
|
| 142 |
+
point_coords = self.transform.apply_coords(point_coords, self.original_size)
|
| 143 |
+
coords_torch = torch.as_tensor(point_coords, dtype=torch.float, device=self.device)
|
| 144 |
+
labels_torch = torch.as_tensor(point_labels, dtype=torch.int, device=self.device)
|
| 145 |
+
coords_torch, labels_torch = coords_torch[None, :, :], labels_torch[None, :]
|
| 146 |
+
if box is not None:
|
| 147 |
+
box = self.transform.apply_boxes(box, self.original_size)
|
| 148 |
+
box_torch = torch.as_tensor(box, dtype=torch.float, device=self.device)
|
| 149 |
+
box_torch = box_torch[None, :]
|
| 150 |
+
if mask_input is not None:
|
| 151 |
+
mask_input_torch = torch.as_tensor(mask_input, dtype=torch.float, device=self.device)
|
| 152 |
+
mask_input_torch = mask_input_torch[None, :, :, :]
|
| 153 |
+
|
| 154 |
+
masks, iou_predictions, low_res_masks, mask_tokens = self.predict_torch(
|
| 155 |
+
coords_torch,
|
| 156 |
+
labels_torch,
|
| 157 |
+
box_torch,
|
| 158 |
+
mask_input_torch,
|
| 159 |
+
multimask_output,
|
| 160 |
+
return_logits=return_logits,
|
| 161 |
+
)
|
| 162 |
+
|
| 163 |
+
masks = masks[0].detach().cpu().numpy()
|
| 164 |
+
iou_predictions = iou_predictions[0].detach().cpu().numpy()
|
| 165 |
+
low_res_masks = low_res_masks[0].detach().cpu().numpy()
|
| 166 |
+
return masks, iou_predictions, low_res_masks, mask_tokens
|
| 167 |
+
|
| 168 |
+
@torch.no_grad()
|
| 169 |
+
def predict_torch(
|
| 170 |
+
self,
|
| 171 |
+
point_coords: Optional[torch.Tensor],
|
| 172 |
+
point_labels: Optional[torch.Tensor],
|
| 173 |
+
boxes: Optional[torch.Tensor] = None,
|
| 174 |
+
mask_input: Optional[torch.Tensor] = None,
|
| 175 |
+
multimask_output: bool = True,
|
| 176 |
+
return_logits: bool = False,
|
| 177 |
+
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
|
| 178 |
+
"""
|
| 179 |
+
Predict masks for the given input prompts, using the currently set image.
|
| 180 |
+
Input prompts are batched torch tensors and are expected to already be
|
| 181 |
+
transformed to the input frame using ResizeLongestSide.
|
| 182 |
+
|
| 183 |
+
Arguments:
|
| 184 |
+
point_coords (torch.Tensor or None): A BxNx2 array of point prompts to the
|
| 185 |
+
model. Each point is in (X,Y) in pixels.
|
| 186 |
+
point_labels (torch.Tensor or None): A BxN array of labels for the
|
| 187 |
+
point prompts. 1 indicates a foreground point and 0 indicates a
|
| 188 |
+
background point.
|
| 189 |
+
box (np.ndarray or None): A Bx4 array given a box prompt to the
|
| 190 |
+
model, in XYXY format.
|
| 191 |
+
mask_input (np.ndarray): A low resolution mask input to the model, typically
|
| 192 |
+
coming from a previous prediction iteration. Has form Bx1xHxW, where
|
| 193 |
+
for SAM, H=W=256. Masks returned by a previous iteration of the
|
| 194 |
+
predict method do not need further transformation.
|
| 195 |
+
multimask_output (bool): If true, the model will return three masks.
|
| 196 |
+
For ambiguous input prompts (such as a single click), this will often
|
| 197 |
+
produce better masks than a single prediction. If only a single
|
| 198 |
+
mask is needed, the model's predicted quality score can be used
|
| 199 |
+
to select the best mask. For non-ambiguous prompts, such as multiple
|
| 200 |
+
input prompts, multimask_output=False can give better results.
|
| 201 |
+
return_logits (bool): If true, returns un-thresholded masks logits
|
| 202 |
+
instead of a binary mask.
|
| 203 |
+
|
| 204 |
+
Returns:
|
| 205 |
+
(torch.Tensor): The output masks in BxCxHxW format, where C is the
|
| 206 |
+
number of masks, and (H, W) is the original image size.
|
| 207 |
+
(torch.Tensor): An array of shape BxC containing the model's
|
| 208 |
+
predictions for the quality of each mask.
|
| 209 |
+
(torch.Tensor): An array of shape BxCxHxW, where C is the number
|
| 210 |
+
of masks and H=W=256. These low res logits can be passed to
|
| 211 |
+
a subsequent iteration as mask input.
|
| 212 |
+
"""
|
| 213 |
+
if not self.is_image_set:
|
| 214 |
+
raise RuntimeError("An image must be set with .set_image(...) before mask prediction.")
|
| 215 |
+
|
| 216 |
+
if point_coords is not None:
|
| 217 |
+
points = (point_coords, point_labels)
|
| 218 |
+
else:
|
| 219 |
+
points = None
|
| 220 |
+
|
| 221 |
+
# Embed prompts
|
| 222 |
+
sparse_embeddings, dense_embeddings = self.model.prompt_encoder(
|
| 223 |
+
points=points,
|
| 224 |
+
boxes=boxes,
|
| 225 |
+
masks=mask_input,
|
| 226 |
+
)
|
| 227 |
+
|
| 228 |
+
# Predict masks
|
| 229 |
+
low_res_masks, iou_predictions, mask_tokens = self.model.mask_decoder(
|
| 230 |
+
image_embeddings=self.features,
|
| 231 |
+
image_pe=self.model.prompt_encoder.get_dense_pe(),
|
| 232 |
+
sparse_prompt_embeddings=sparse_embeddings,
|
| 233 |
+
dense_prompt_embeddings=dense_embeddings,
|
| 234 |
+
multimask_output=multimask_output,
|
| 235 |
+
)
|
| 236 |
+
|
| 237 |
+
# Upscale the masks to the original image resolution
|
| 238 |
+
masks = self.model.postprocess_masks(low_res_masks, self.input_size, self.original_size)
|
| 239 |
+
|
| 240 |
+
if not return_logits:
|
| 241 |
+
masks = masks > self.model.mask_threshold
|
| 242 |
+
|
| 243 |
+
return masks, iou_predictions, low_res_masks, mask_tokens
|
| 244 |
+
|
| 245 |
+
def get_image_embedding(self) -> torch.Tensor:
|
| 246 |
+
"""
|
| 247 |
+
Returns the image embeddings for the currently set image, with
|
| 248 |
+
shape 1xCxHxW, where C is the embedding dimension and (H,W) are
|
| 249 |
+
the embedding spatial dimension of SAM (typically C=256, H=W=64).
|
| 250 |
+
"""
|
| 251 |
+
if not self.is_image_set:
|
| 252 |
+
raise RuntimeError(
|
| 253 |
+
"An image must be set with .set_image(...) to generate an embedding."
|
| 254 |
+
)
|
| 255 |
+
assert self.features is not None, "Features must exist if an image has been set."
|
| 256 |
+
return self.features
|
| 257 |
+
|
| 258 |
+
@property
|
| 259 |
+
def device(self) -> torch.device:
|
| 260 |
+
return self.model.device
|
| 261 |
+
|
| 262 |
+
def reset_image(self) -> None:
|
| 263 |
+
"""Resets the currently set image."""
|
| 264 |
+
self.is_image_set = False
|
| 265 |
+
self.features = None
|
| 266 |
+
self.orig_h = None
|
| 267 |
+
self.orig_w = None
|
| 268 |
+
self.input_h = None
|
| 269 |
+
self.input_w = None
|
segment_anything/utils/__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
segment_anything/utils/amg.py
ADDED
|
@@ -0,0 +1,346 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import numpy as np
|
| 8 |
+
import torch
|
| 9 |
+
|
| 10 |
+
import math
|
| 11 |
+
from copy import deepcopy
|
| 12 |
+
from itertools import product
|
| 13 |
+
from typing import Any, Dict, Generator, ItemsView, List, Tuple
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class MaskData:
|
| 17 |
+
"""
|
| 18 |
+
A structure for storing masks and their related data in batched format.
|
| 19 |
+
Implements basic filtering and concatenation.
|
| 20 |
+
"""
|
| 21 |
+
|
| 22 |
+
def __init__(self, **kwargs) -> None:
|
| 23 |
+
for v in kwargs.values():
|
| 24 |
+
assert isinstance(
|
| 25 |
+
v, (list, np.ndarray, torch.Tensor)
|
| 26 |
+
), "MaskData only supports list, numpy arrays, and torch tensors."
|
| 27 |
+
self._stats = dict(**kwargs)
|
| 28 |
+
|
| 29 |
+
def __setitem__(self, key: str, item: Any) -> None:
|
| 30 |
+
assert isinstance(
|
| 31 |
+
item, (list, np.ndarray, torch.Tensor)
|
| 32 |
+
), "MaskData only supports list, numpy arrays, and torch tensors."
|
| 33 |
+
self._stats[key] = item
|
| 34 |
+
|
| 35 |
+
def __delitem__(self, key: str) -> None:
|
| 36 |
+
del self._stats[key]
|
| 37 |
+
|
| 38 |
+
def __getitem__(self, key: str) -> Any:
|
| 39 |
+
return self._stats[key]
|
| 40 |
+
|
| 41 |
+
def items(self) -> ItemsView[str, Any]:
|
| 42 |
+
return self._stats.items()
|
| 43 |
+
|
| 44 |
+
def filter(self, keep: torch.Tensor) -> None:
|
| 45 |
+
for k, v in self._stats.items():
|
| 46 |
+
if v is None:
|
| 47 |
+
self._stats[k] = None
|
| 48 |
+
elif isinstance(v, torch.Tensor):
|
| 49 |
+
self._stats[k] = v[torch.as_tensor(keep, device=v.device)]
|
| 50 |
+
elif isinstance(v, np.ndarray):
|
| 51 |
+
self._stats[k] = v[keep.detach().cpu().numpy()]
|
| 52 |
+
elif isinstance(v, list) and keep.dtype == torch.bool:
|
| 53 |
+
self._stats[k] = [a for i, a in enumerate(v) if keep[i]]
|
| 54 |
+
elif isinstance(v, list):
|
| 55 |
+
self._stats[k] = [v[i] for i in keep]
|
| 56 |
+
else:
|
| 57 |
+
raise TypeError(f"MaskData key {k} has an unsupported type {type(v)}.")
|
| 58 |
+
|
| 59 |
+
def cat(self, new_stats: "MaskData") -> None:
|
| 60 |
+
for k, v in new_stats.items():
|
| 61 |
+
if k not in self._stats or self._stats[k] is None:
|
| 62 |
+
self._stats[k] = deepcopy(v)
|
| 63 |
+
elif isinstance(v, torch.Tensor):
|
| 64 |
+
self._stats[k] = torch.cat([self._stats[k], v], dim=0)
|
| 65 |
+
elif isinstance(v, np.ndarray):
|
| 66 |
+
self._stats[k] = np.concatenate([self._stats[k], v], axis=0)
|
| 67 |
+
elif isinstance(v, list):
|
| 68 |
+
self._stats[k] = self._stats[k] + deepcopy(v)
|
| 69 |
+
else:
|
| 70 |
+
raise TypeError(f"MaskData key {k} has an unsupported type {type(v)}.")
|
| 71 |
+
|
| 72 |
+
def to_numpy(self) -> None:
|
| 73 |
+
for k, v in self._stats.items():
|
| 74 |
+
if isinstance(v, torch.Tensor):
|
| 75 |
+
self._stats[k] = v.detach().cpu().numpy()
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def is_box_near_crop_edge(
|
| 79 |
+
boxes: torch.Tensor, crop_box: List[int], orig_box: List[int], atol: float = 20.0
|
| 80 |
+
) -> torch.Tensor:
|
| 81 |
+
"""Filter masks at the edge of a crop, but not at the edge of the original image."""
|
| 82 |
+
crop_box_torch = torch.as_tensor(crop_box, dtype=torch.float, device=boxes.device)
|
| 83 |
+
orig_box_torch = torch.as_tensor(orig_box, dtype=torch.float, device=boxes.device)
|
| 84 |
+
boxes = uncrop_boxes_xyxy(boxes, crop_box).float()
|
| 85 |
+
near_crop_edge = torch.isclose(boxes, crop_box_torch[None, :], atol=atol, rtol=0)
|
| 86 |
+
near_image_edge = torch.isclose(boxes, orig_box_torch[None, :], atol=atol, rtol=0)
|
| 87 |
+
near_crop_edge = torch.logical_and(near_crop_edge, ~near_image_edge)
|
| 88 |
+
return torch.any(near_crop_edge, dim=1)
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def box_xyxy_to_xywh(box_xyxy: torch.Tensor) -> torch.Tensor:
|
| 92 |
+
box_xywh = deepcopy(box_xyxy)
|
| 93 |
+
box_xywh[2] = box_xywh[2] - box_xywh[0]
|
| 94 |
+
box_xywh[3] = box_xywh[3] - box_xywh[1]
|
| 95 |
+
return box_xywh
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
def batch_iterator(batch_size: int, *args) -> Generator[List[Any], None, None]:
|
| 99 |
+
assert len(args) > 0 and all(
|
| 100 |
+
len(a) == len(args[0]) for a in args
|
| 101 |
+
), "Batched iteration must have inputs of all the same size."
|
| 102 |
+
n_batches = len(args[0]) // batch_size + int(len(args[0]) % batch_size != 0)
|
| 103 |
+
for b in range(n_batches):
|
| 104 |
+
yield [arg[b * batch_size : (b + 1) * batch_size] for arg in args]
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
def mask_to_rle_pytorch(tensor: torch.Tensor) -> List[Dict[str, Any]]:
|
| 108 |
+
"""
|
| 109 |
+
Encodes masks to an uncompressed RLE, in the format expected by
|
| 110 |
+
pycoco tools.
|
| 111 |
+
"""
|
| 112 |
+
# Put in fortran order and flatten h,w
|
| 113 |
+
b, h, w = tensor.shape
|
| 114 |
+
tensor = tensor.permute(0, 2, 1).flatten(1)
|
| 115 |
+
|
| 116 |
+
# Compute change indices
|
| 117 |
+
diff = tensor[:, 1:] ^ tensor[:, :-1]
|
| 118 |
+
change_indices = diff.nonzero()
|
| 119 |
+
|
| 120 |
+
# Encode run length
|
| 121 |
+
out = []
|
| 122 |
+
for i in range(b):
|
| 123 |
+
cur_idxs = change_indices[change_indices[:, 0] == i, 1]
|
| 124 |
+
cur_idxs = torch.cat(
|
| 125 |
+
[
|
| 126 |
+
torch.tensor([0], dtype=cur_idxs.dtype, device=cur_idxs.device),
|
| 127 |
+
cur_idxs + 1,
|
| 128 |
+
torch.tensor([h * w], dtype=cur_idxs.dtype, device=cur_idxs.device),
|
| 129 |
+
]
|
| 130 |
+
)
|
| 131 |
+
btw_idxs = cur_idxs[1:] - cur_idxs[:-1]
|
| 132 |
+
counts = [] if tensor[i, 0] == 0 else [0]
|
| 133 |
+
counts.extend(btw_idxs.detach().cpu().tolist())
|
| 134 |
+
out.append({"size": [h, w], "counts": counts})
|
| 135 |
+
return out
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
def rle_to_mask(rle: Dict[str, Any]) -> np.ndarray:
|
| 139 |
+
"""Compute a binary mask from an uncompressed RLE."""
|
| 140 |
+
h, w = rle["size"]
|
| 141 |
+
mask = np.empty(h * w, dtype=bool)
|
| 142 |
+
idx = 0
|
| 143 |
+
parity = False
|
| 144 |
+
for count in rle["counts"]:
|
| 145 |
+
mask[idx : idx + count] = parity
|
| 146 |
+
idx += count
|
| 147 |
+
parity ^= True
|
| 148 |
+
mask = mask.reshape(w, h)
|
| 149 |
+
return mask.transpose() # Put in C order
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
def area_from_rle(rle: Dict[str, Any]) -> int:
|
| 153 |
+
return sum(rle["counts"][1::2])
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
def calculate_stability_score(
|
| 157 |
+
masks: torch.Tensor, mask_threshold: float, threshold_offset: float
|
| 158 |
+
) -> torch.Tensor:
|
| 159 |
+
"""
|
| 160 |
+
Computes the stability score for a batch of masks. The stability
|
| 161 |
+
score is the IoU between the binary masks obtained by thresholding
|
| 162 |
+
the predicted mask logits at high and low values.
|
| 163 |
+
"""
|
| 164 |
+
# One mask is always contained inside the other.
|
| 165 |
+
# Save memory by preventing unnecesary cast to torch.int64
|
| 166 |
+
intersections = (
|
| 167 |
+
(masks > (mask_threshold + threshold_offset))
|
| 168 |
+
.sum(-1, dtype=torch.int16)
|
| 169 |
+
.sum(-1, dtype=torch.int32)
|
| 170 |
+
)
|
| 171 |
+
unions = (
|
| 172 |
+
(masks > (mask_threshold - threshold_offset))
|
| 173 |
+
.sum(-1, dtype=torch.int16)
|
| 174 |
+
.sum(-1, dtype=torch.int32)
|
| 175 |
+
)
|
| 176 |
+
return intersections / unions
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
def build_point_grid(n_per_side: int) -> np.ndarray:
|
| 180 |
+
"""Generates a 2D grid of points evenly spaced in [0,1]x[0,1]."""
|
| 181 |
+
offset = 1 / (2 * n_per_side)
|
| 182 |
+
points_one_side = np.linspace(offset, 1 - offset, n_per_side)
|
| 183 |
+
points_x = np.tile(points_one_side[None, :], (n_per_side, 1))
|
| 184 |
+
points_y = np.tile(points_one_side[:, None], (1, n_per_side))
|
| 185 |
+
points = np.stack([points_x, points_y], axis=-1).reshape(-1, 2)
|
| 186 |
+
return points
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
def build_all_layer_point_grids(
|
| 190 |
+
n_per_side: int, n_layers: int, scale_per_layer: int
|
| 191 |
+
) -> List[np.ndarray]:
|
| 192 |
+
"""Generates point grids for all crop layers."""
|
| 193 |
+
points_by_layer = []
|
| 194 |
+
for i in range(n_layers + 1):
|
| 195 |
+
n_points = int(n_per_side / (scale_per_layer**i))
|
| 196 |
+
points_by_layer.append(build_point_grid(n_points))
|
| 197 |
+
return points_by_layer
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
def generate_crop_boxes(
|
| 201 |
+
im_size: Tuple[int, ...], n_layers: int, overlap_ratio: float
|
| 202 |
+
) -> Tuple[List[List[int]], List[int]]:
|
| 203 |
+
"""
|
| 204 |
+
Generates a list of crop boxes of different sizes. Each layer
|
| 205 |
+
has (2**i)**2 boxes for the ith layer.
|
| 206 |
+
"""
|
| 207 |
+
crop_boxes, layer_idxs = [], []
|
| 208 |
+
im_h, im_w = im_size
|
| 209 |
+
short_side = min(im_h, im_w)
|
| 210 |
+
|
| 211 |
+
# Original image
|
| 212 |
+
crop_boxes.append([0, 0, im_w, im_h])
|
| 213 |
+
layer_idxs.append(0)
|
| 214 |
+
|
| 215 |
+
def crop_len(orig_len, n_crops, overlap):
|
| 216 |
+
return int(math.ceil((overlap * (n_crops - 1) + orig_len) / n_crops))
|
| 217 |
+
|
| 218 |
+
for i_layer in range(n_layers):
|
| 219 |
+
n_crops_per_side = 2 ** (i_layer + 1)
|
| 220 |
+
overlap = int(overlap_ratio * short_side * (2 / n_crops_per_side))
|
| 221 |
+
|
| 222 |
+
crop_w = crop_len(im_w, n_crops_per_side, overlap)
|
| 223 |
+
crop_h = crop_len(im_h, n_crops_per_side, overlap)
|
| 224 |
+
|
| 225 |
+
crop_box_x0 = [int((crop_w - overlap) * i) for i in range(n_crops_per_side)]
|
| 226 |
+
crop_box_y0 = [int((crop_h - overlap) * i) for i in range(n_crops_per_side)]
|
| 227 |
+
|
| 228 |
+
# Crops in XYWH format
|
| 229 |
+
for x0, y0 in product(crop_box_x0, crop_box_y0):
|
| 230 |
+
box = [x0, y0, min(x0 + crop_w, im_w), min(y0 + crop_h, im_h)]
|
| 231 |
+
crop_boxes.append(box)
|
| 232 |
+
layer_idxs.append(i_layer + 1)
|
| 233 |
+
|
| 234 |
+
return crop_boxes, layer_idxs
|
| 235 |
+
|
| 236 |
+
|
| 237 |
+
def uncrop_boxes_xyxy(boxes: torch.Tensor, crop_box: List[int]) -> torch.Tensor:
|
| 238 |
+
x0, y0, _, _ = crop_box
|
| 239 |
+
offset = torch.tensor([[x0, y0, x0, y0]], device=boxes.device)
|
| 240 |
+
# Check if boxes has a channel dimension
|
| 241 |
+
if len(boxes.shape) == 3:
|
| 242 |
+
offset = offset.unsqueeze(1)
|
| 243 |
+
return boxes + offset
|
| 244 |
+
|
| 245 |
+
|
| 246 |
+
def uncrop_points(points: torch.Tensor, crop_box: List[int]) -> torch.Tensor:
|
| 247 |
+
x0, y0, _, _ = crop_box
|
| 248 |
+
offset = torch.tensor([[x0, y0]], device=points.device)
|
| 249 |
+
# Check if points has a channel dimension
|
| 250 |
+
if len(points.shape) == 3:
|
| 251 |
+
offset = offset.unsqueeze(1)
|
| 252 |
+
return points + offset
|
| 253 |
+
|
| 254 |
+
|
| 255 |
+
def uncrop_masks(
|
| 256 |
+
masks: torch.Tensor, crop_box: List[int], orig_h: int, orig_w: int
|
| 257 |
+
) -> torch.Tensor:
|
| 258 |
+
x0, y0, x1, y1 = crop_box
|
| 259 |
+
if x0 == 0 and y0 == 0 and x1 == orig_w and y1 == orig_h:
|
| 260 |
+
return masks
|
| 261 |
+
# Coordinate transform masks
|
| 262 |
+
pad_x, pad_y = orig_w - (x1 - x0), orig_h - (y1 - y0)
|
| 263 |
+
pad = (x0, pad_x - x0, y0, pad_y - y0)
|
| 264 |
+
return torch.nn.functional.pad(masks, pad, value=0)
|
| 265 |
+
|
| 266 |
+
|
| 267 |
+
def remove_small_regions(
|
| 268 |
+
mask: np.ndarray, area_thresh: float, mode: str
|
| 269 |
+
) -> Tuple[np.ndarray, bool]:
|
| 270 |
+
"""
|
| 271 |
+
Removes small disconnected regions and holes in a mask. Returns the
|
| 272 |
+
mask and an indicator of if the mask has been modified.
|
| 273 |
+
"""
|
| 274 |
+
import cv2 # type: ignore
|
| 275 |
+
|
| 276 |
+
assert mode in ["holes", "islands"]
|
| 277 |
+
correct_holes = mode == "holes"
|
| 278 |
+
working_mask = (correct_holes ^ mask).astype(np.uint8)
|
| 279 |
+
n_labels, regions, stats, _ = cv2.connectedComponentsWithStats(working_mask, 8)
|
| 280 |
+
sizes = stats[:, -1][1:] # Row 0 is background label
|
| 281 |
+
small_regions = [i + 1 for i, s in enumerate(sizes) if s < area_thresh]
|
| 282 |
+
if len(small_regions) == 0:
|
| 283 |
+
return mask, False
|
| 284 |
+
fill_labels = [0] + small_regions
|
| 285 |
+
if not correct_holes:
|
| 286 |
+
fill_labels = [i for i in range(n_labels) if i not in fill_labels]
|
| 287 |
+
# If every region is below threshold, keep largest
|
| 288 |
+
if len(fill_labels) == 0:
|
| 289 |
+
fill_labels = [int(np.argmax(sizes)) + 1]
|
| 290 |
+
mask = np.isin(regions, fill_labels)
|
| 291 |
+
return mask, True
|
| 292 |
+
|
| 293 |
+
|
| 294 |
+
def coco_encode_rle(uncompressed_rle: Dict[str, Any]) -> Dict[str, Any]:
|
| 295 |
+
from pycocotools import mask as mask_utils # type: ignore
|
| 296 |
+
|
| 297 |
+
h, w = uncompressed_rle["size"]
|
| 298 |
+
rle = mask_utils.frPyObjects(uncompressed_rle, h, w)
|
| 299 |
+
rle["counts"] = rle["counts"].decode("utf-8") # Necessary to serialize with json
|
| 300 |
+
return rle
|
| 301 |
+
|
| 302 |
+
|
| 303 |
+
def batched_mask_to_box(masks: torch.Tensor) -> torch.Tensor:
|
| 304 |
+
"""
|
| 305 |
+
Calculates boxes in XYXY format around masks. Return [0,0,0,0] for
|
| 306 |
+
an empty mask. For input shape C1xC2x...xHxW, the output shape is C1xC2x...x4.
|
| 307 |
+
"""
|
| 308 |
+
# torch.max below raises an error on empty inputs, just skip in this case
|
| 309 |
+
if torch.numel(masks) == 0:
|
| 310 |
+
return torch.zeros(*masks.shape[:-2], 4, device=masks.device)
|
| 311 |
+
|
| 312 |
+
# Normalize shape to CxHxW
|
| 313 |
+
shape = masks.shape
|
| 314 |
+
h, w = shape[-2:]
|
| 315 |
+
if len(shape) > 2:
|
| 316 |
+
masks = masks.flatten(0, -3)
|
| 317 |
+
else:
|
| 318 |
+
masks = masks.unsqueeze(0)
|
| 319 |
+
|
| 320 |
+
# Get top and bottom edges
|
| 321 |
+
in_height, _ = torch.max(masks, dim=-1)
|
| 322 |
+
in_height_coords = in_height * torch.arange(h, device=in_height.device)[None, :]
|
| 323 |
+
bottom_edges, _ = torch.max(in_height_coords, dim=-1)
|
| 324 |
+
in_height_coords = in_height_coords + h * (~in_height)
|
| 325 |
+
top_edges, _ = torch.min(in_height_coords, dim=-1)
|
| 326 |
+
|
| 327 |
+
# Get left and right edges
|
| 328 |
+
in_width, _ = torch.max(masks, dim=-2)
|
| 329 |
+
in_width_coords = in_width * torch.arange(w, device=in_width.device)[None, :]
|
| 330 |
+
right_edges, _ = torch.max(in_width_coords, dim=-1)
|
| 331 |
+
in_width_coords = in_width_coords + w * (~in_width)
|
| 332 |
+
left_edges, _ = torch.min(in_width_coords, dim=-1)
|
| 333 |
+
|
| 334 |
+
# If the mask is empty the right edge will be to the left of the left edge.
|
| 335 |
+
# Replace these boxes with [0, 0, 0, 0]
|
| 336 |
+
empty_filter = (right_edges < left_edges) | (bottom_edges < top_edges)
|
| 337 |
+
out = torch.stack([left_edges, top_edges, right_edges, bottom_edges], dim=-1)
|
| 338 |
+
out = out * (~empty_filter).unsqueeze(-1)
|
| 339 |
+
|
| 340 |
+
# Return to original shape
|
| 341 |
+
if len(shape) > 2:
|
| 342 |
+
out = out.reshape(*shape[:-2], 4)
|
| 343 |
+
else:
|
| 344 |
+
out = out[0]
|
| 345 |
+
|
| 346 |
+
return out
|
segment_anything/utils/onnx.py
ADDED
|
@@ -0,0 +1,144 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
import torch.nn as nn
|
| 9 |
+
from torch.nn import functional as F
|
| 10 |
+
|
| 11 |
+
from typing import Tuple
|
| 12 |
+
|
| 13 |
+
from ..modeling import Sam
|
| 14 |
+
from .amg import calculate_stability_score
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class SamOnnxModel(nn.Module):
|
| 18 |
+
"""
|
| 19 |
+
This model should not be called directly, but is used in ONNX export.
|
| 20 |
+
It combines the prompt encoder, mask decoder, and mask postprocessing of Sam,
|
| 21 |
+
with some functions modified to enable model tracing. Also supports extra
|
| 22 |
+
options controlling what information. See the ONNX export script for details.
|
| 23 |
+
"""
|
| 24 |
+
|
| 25 |
+
def __init__(
|
| 26 |
+
self,
|
| 27 |
+
model: Sam,
|
| 28 |
+
return_single_mask: bool,
|
| 29 |
+
use_stability_score: bool = False,
|
| 30 |
+
return_extra_metrics: bool = False,
|
| 31 |
+
) -> None:
|
| 32 |
+
super().__init__()
|
| 33 |
+
self.mask_decoder = model.mask_decoder
|
| 34 |
+
self.model = model
|
| 35 |
+
self.img_size = model.image_encoder.img_size
|
| 36 |
+
self.return_single_mask = return_single_mask
|
| 37 |
+
self.use_stability_score = use_stability_score
|
| 38 |
+
self.stability_score_offset = 1.0
|
| 39 |
+
self.return_extra_metrics = return_extra_metrics
|
| 40 |
+
|
| 41 |
+
@staticmethod
|
| 42 |
+
def resize_longest_image_size(
|
| 43 |
+
input_image_size: torch.Tensor, longest_side: int
|
| 44 |
+
) -> torch.Tensor:
|
| 45 |
+
input_image_size = input_image_size.to(torch.float32)
|
| 46 |
+
scale = longest_side / torch.max(input_image_size)
|
| 47 |
+
transformed_size = scale * input_image_size
|
| 48 |
+
transformed_size = torch.floor(transformed_size + 0.5).to(torch.int64)
|
| 49 |
+
return transformed_size
|
| 50 |
+
|
| 51 |
+
def _embed_points(self, point_coords: torch.Tensor, point_labels: torch.Tensor) -> torch.Tensor:
|
| 52 |
+
point_coords = point_coords + 0.5
|
| 53 |
+
point_coords = point_coords / self.img_size
|
| 54 |
+
point_embedding = self.model.prompt_encoder.pe_layer._pe_encoding(point_coords)
|
| 55 |
+
point_labels = point_labels.unsqueeze(-1).expand_as(point_embedding)
|
| 56 |
+
|
| 57 |
+
point_embedding = point_embedding * (point_labels != -1)
|
| 58 |
+
point_embedding = point_embedding + self.model.prompt_encoder.not_a_point_embed.weight * (
|
| 59 |
+
point_labels == -1
|
| 60 |
+
)
|
| 61 |
+
|
| 62 |
+
for i in range(self.model.prompt_encoder.num_point_embeddings):
|
| 63 |
+
point_embedding = point_embedding + self.model.prompt_encoder.point_embeddings[
|
| 64 |
+
i
|
| 65 |
+
].weight * (point_labels == i)
|
| 66 |
+
|
| 67 |
+
return point_embedding
|
| 68 |
+
|
| 69 |
+
def _embed_masks(self, input_mask: torch.Tensor, has_mask_input: torch.Tensor) -> torch.Tensor:
|
| 70 |
+
mask_embedding = has_mask_input * self.model.prompt_encoder.mask_downscaling(input_mask)
|
| 71 |
+
mask_embedding = mask_embedding + (
|
| 72 |
+
1 - has_mask_input
|
| 73 |
+
) * self.model.prompt_encoder.no_mask_embed.weight.reshape(1, -1, 1, 1)
|
| 74 |
+
return mask_embedding
|
| 75 |
+
|
| 76 |
+
def mask_postprocessing(self, masks: torch.Tensor, orig_im_size: torch.Tensor) -> torch.Tensor:
|
| 77 |
+
masks = F.interpolate(
|
| 78 |
+
masks,
|
| 79 |
+
size=(self.img_size, self.img_size),
|
| 80 |
+
mode="bilinear",
|
| 81 |
+
align_corners=False,
|
| 82 |
+
)
|
| 83 |
+
|
| 84 |
+
prepadded_size = self.resize_longest_image_size(orig_im_size, self.img_size)
|
| 85 |
+
masks = masks[..., : int(prepadded_size[0]), : int(prepadded_size[1])]
|
| 86 |
+
|
| 87 |
+
orig_im_size = orig_im_size.to(torch.int64)
|
| 88 |
+
h, w = orig_im_size[0], orig_im_size[1]
|
| 89 |
+
masks = F.interpolate(masks, size=(h, w), mode="bilinear", align_corners=False)
|
| 90 |
+
return masks
|
| 91 |
+
|
| 92 |
+
def select_masks(
|
| 93 |
+
self, masks: torch.Tensor, iou_preds: torch.Tensor, num_points: int
|
| 94 |
+
) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 95 |
+
# Determine if we should return the multiclick mask or not from the number of points.
|
| 96 |
+
# The reweighting is used to avoid control flow.
|
| 97 |
+
score_reweight = torch.tensor(
|
| 98 |
+
[[1000] + [0] * (self.model.mask_decoder.num_mask_tokens - 1)]
|
| 99 |
+
).to(iou_preds.device)
|
| 100 |
+
score = iou_preds + (num_points - 2.5) * score_reweight
|
| 101 |
+
best_idx = torch.argmax(score, dim=1)
|
| 102 |
+
masks = masks[torch.arange(masks.shape[0]), best_idx, :, :].unsqueeze(1)
|
| 103 |
+
iou_preds = iou_preds[torch.arange(masks.shape[0]), best_idx].unsqueeze(1)
|
| 104 |
+
|
| 105 |
+
return masks, iou_preds
|
| 106 |
+
|
| 107 |
+
@torch.no_grad()
|
| 108 |
+
def forward(
|
| 109 |
+
self,
|
| 110 |
+
image_embeddings: torch.Tensor,
|
| 111 |
+
point_coords: torch.Tensor,
|
| 112 |
+
point_labels: torch.Tensor,
|
| 113 |
+
mask_input: torch.Tensor,
|
| 114 |
+
has_mask_input: torch.Tensor,
|
| 115 |
+
orig_im_size: torch.Tensor,
|
| 116 |
+
):
|
| 117 |
+
sparse_embedding = self._embed_points(point_coords, point_labels)
|
| 118 |
+
dense_embedding = self._embed_masks(mask_input, has_mask_input)
|
| 119 |
+
|
| 120 |
+
masks, scores = self.model.mask_decoder.predict_masks(
|
| 121 |
+
image_embeddings=image_embeddings,
|
| 122 |
+
image_pe=self.model.prompt_encoder.get_dense_pe(),
|
| 123 |
+
sparse_prompt_embeddings=sparse_embedding,
|
| 124 |
+
dense_prompt_embeddings=dense_embedding,
|
| 125 |
+
)
|
| 126 |
+
|
| 127 |
+
if self.use_stability_score:
|
| 128 |
+
scores = calculate_stability_score(
|
| 129 |
+
masks, self.model.mask_threshold, self.stability_score_offset
|
| 130 |
+
)
|
| 131 |
+
|
| 132 |
+
if self.return_single_mask:
|
| 133 |
+
masks, scores = self.select_masks(masks, scores, point_coords.shape[1])
|
| 134 |
+
|
| 135 |
+
upscaled_masks = self.mask_postprocessing(masks, orig_im_size)
|
| 136 |
+
|
| 137 |
+
if self.return_extra_metrics:
|
| 138 |
+
stability_scores = calculate_stability_score(
|
| 139 |
+
upscaled_masks, self.model.mask_threshold, self.stability_score_offset
|
| 140 |
+
)
|
| 141 |
+
areas = (upscaled_masks > self.model.mask_threshold).sum(-1).sum(-1)
|
| 142 |
+
return upscaled_masks, scores, stability_scores, areas, masks
|
| 143 |
+
|
| 144 |
+
return upscaled_masks, scores, masks
|
segment_anything/utils/transforms.py
ADDED
|
@@ -0,0 +1,102 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import numpy as np
|
| 8 |
+
import torch
|
| 9 |
+
from torch.nn import functional as F
|
| 10 |
+
from torchvision.transforms.functional import resize, to_pil_image # type: ignore
|
| 11 |
+
|
| 12 |
+
from copy import deepcopy
|
| 13 |
+
from typing import Tuple
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class ResizeLongestSide:
|
| 17 |
+
"""
|
| 18 |
+
Resizes images to longest side 'target_length', as well as provides
|
| 19 |
+
methods for resizing coordinates and boxes. Provides methods for
|
| 20 |
+
transforming both numpy array and batched torch tensors.
|
| 21 |
+
"""
|
| 22 |
+
|
| 23 |
+
def __init__(self, target_length: int) -> None:
|
| 24 |
+
self.target_length = target_length
|
| 25 |
+
|
| 26 |
+
def apply_image(self, image: np.ndarray) -> np.ndarray:
|
| 27 |
+
"""
|
| 28 |
+
Expects a numpy array with shape HxWxC in uint8 format.
|
| 29 |
+
"""
|
| 30 |
+
target_size = self.get_preprocess_shape(image.shape[0], image.shape[1], self.target_length)
|
| 31 |
+
return np.array(resize(to_pil_image(image), target_size))
|
| 32 |
+
|
| 33 |
+
def apply_coords(self, coords: np.ndarray, original_size: Tuple[int, ...]) -> np.ndarray:
|
| 34 |
+
"""
|
| 35 |
+
Expects a numpy array of length 2 in the final dimension. Requires the
|
| 36 |
+
original image size in (H, W) format.
|
| 37 |
+
"""
|
| 38 |
+
old_h, old_w = original_size
|
| 39 |
+
new_h, new_w = self.get_preprocess_shape(
|
| 40 |
+
original_size[0], original_size[1], self.target_length
|
| 41 |
+
)
|
| 42 |
+
coords = deepcopy(coords).astype(float)
|
| 43 |
+
coords[..., 0] = coords[..., 0] * (new_w / old_w)
|
| 44 |
+
coords[..., 1] = coords[..., 1] * (new_h / old_h)
|
| 45 |
+
return coords
|
| 46 |
+
|
| 47 |
+
def apply_boxes(self, boxes: np.ndarray, original_size: Tuple[int, ...]) -> np.ndarray:
|
| 48 |
+
"""
|
| 49 |
+
Expects a numpy array shape Bx4. Requires the original image size
|
| 50 |
+
in (H, W) format.
|
| 51 |
+
"""
|
| 52 |
+
boxes = self.apply_coords(boxes.reshape(-1, 2, 2), original_size)
|
| 53 |
+
return boxes.reshape(-1, 4)
|
| 54 |
+
|
| 55 |
+
def apply_image_torch(self, image: torch.Tensor) -> torch.Tensor:
|
| 56 |
+
"""
|
| 57 |
+
Expects batched images with shape BxCxHxW and float format. This
|
| 58 |
+
transformation may not exactly match apply_image. apply_image is
|
| 59 |
+
the transformation expected by the model.
|
| 60 |
+
"""
|
| 61 |
+
# Expects an image in BCHW format. May not exactly match apply_image.
|
| 62 |
+
target_size = self.get_preprocess_shape(image.shape[0], image.shape[1], self.target_length)
|
| 63 |
+
return F.interpolate(
|
| 64 |
+
image, target_size, mode="bilinear", align_corners=False, antialias=True
|
| 65 |
+
)
|
| 66 |
+
|
| 67 |
+
def apply_coords_torch(
|
| 68 |
+
self, coords: torch.Tensor, original_size: Tuple[int, ...]
|
| 69 |
+
) -> torch.Tensor:
|
| 70 |
+
"""
|
| 71 |
+
Expects a torch tensor with length 2 in the last dimension. Requires the
|
| 72 |
+
original image size in (H, W) format.
|
| 73 |
+
"""
|
| 74 |
+
old_h, old_w = original_size
|
| 75 |
+
new_h, new_w = self.get_preprocess_shape(
|
| 76 |
+
original_size[0], original_size[1], self.target_length
|
| 77 |
+
)
|
| 78 |
+
coords = deepcopy(coords).to(torch.float)
|
| 79 |
+
coords[..., 0] = coords[..., 0] * (new_w / old_w)
|
| 80 |
+
coords[..., 1] = coords[..., 1] * (new_h / old_h)
|
| 81 |
+
return coords
|
| 82 |
+
|
| 83 |
+
def apply_boxes_torch(
|
| 84 |
+
self, boxes: torch.Tensor, original_size: Tuple[int, ...]
|
| 85 |
+
) -> torch.Tensor:
|
| 86 |
+
"""
|
| 87 |
+
Expects a torch tensor with shape Bx4. Requires the original image
|
| 88 |
+
size in (H, W) format.
|
| 89 |
+
"""
|
| 90 |
+
boxes = self.apply_coords_torch(boxes.reshape(-1, 2, 2), original_size)
|
| 91 |
+
return boxes.reshape(-1, 4)
|
| 92 |
+
|
| 93 |
+
@staticmethod
|
| 94 |
+
def get_preprocess_shape(oldh: int, oldw: int, long_side_length: int) -> Tuple[int, int]:
|
| 95 |
+
"""
|
| 96 |
+
Compute the output size given input size and target long side length.
|
| 97 |
+
"""
|
| 98 |
+
scale = long_side_length * 1.0 / max(oldh, oldw)
|
| 99 |
+
newh, neww = oldh * scale, oldw * scale
|
| 100 |
+
neww = int(neww + 0.5)
|
| 101 |
+
newh = int(newh + 0.5)
|
| 102 |
+
return (newh, neww)
|
utils.py
ADDED
|
@@ -0,0 +1,152 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.optim as optim
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch.nn.functional as F
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class MLP(nn.Module):
|
| 9 |
+
def __init__(self, input_size, hidden_size, num_classes, dropout_prob=0.1):
|
| 10 |
+
super(MLP, self).__init__()
|
| 11 |
+
self.fc1 = nn.Linear(input_size, hidden_size)
|
| 12 |
+
self.relu = nn.ReLU()
|
| 13 |
+
self.dropout = nn.Dropout(dropout_prob)
|
| 14 |
+
self.fc2 = nn.Linear(hidden_size, num_classes)
|
| 15 |
+
|
| 16 |
+
def forward(self, x):
|
| 17 |
+
out = self.fc1(x)
|
| 18 |
+
out = self.relu(out)
|
| 19 |
+
out = self.dropout(out)
|
| 20 |
+
out = self.fc2(out)
|
| 21 |
+
return out
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def show_anns(anns, color_code='auto'):
|
| 25 |
+
if len(anns) == 0:
|
| 26 |
+
return
|
| 27 |
+
sorted_anns = sorted(anns, key=(lambda x: x['area']), reverse=True)
|
| 28 |
+
ax = plt.gca()
|
| 29 |
+
ax.set_autoscale_on(False)
|
| 30 |
+
polygons = []
|
| 31 |
+
color = []
|
| 32 |
+
for ann in sorted_anns:
|
| 33 |
+
m = ann['segmentation']
|
| 34 |
+
img = np.ones((m.shape[0], m.shape[1], 3))
|
| 35 |
+
color_mask = np.random.random((1, 3)).tolist()[0]
|
| 36 |
+
if color_code == 'auto':
|
| 37 |
+
for i in range(3):
|
| 38 |
+
img[:,:,i] = color_mask[i]
|
| 39 |
+
elif color_code == 'red':
|
| 40 |
+
for i in range(3):
|
| 41 |
+
img[:,:,0] = 1
|
| 42 |
+
img[:,:,1] = 0
|
| 43 |
+
img[:,:,2] = 0
|
| 44 |
+
else:
|
| 45 |
+
for i in range(3):
|
| 46 |
+
img[:,:,0] = 0
|
| 47 |
+
img[:,:,1] = 0
|
| 48 |
+
img[:,:,2] = 1
|
| 49 |
+
return np.dstack((img, m*0.35))
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def show_points(coords, labels, ax, marker_size=375):
|
| 53 |
+
pos_points = coords[labels==1]
|
| 54 |
+
neg_points = coords[labels==0]
|
| 55 |
+
ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*',
|
| 56 |
+
s=marker_size, edgecolor='white', linewidth=1.25)
|
| 57 |
+
ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*',
|
| 58 |
+
s=marker_size, edgecolor='white', linewidth=1.25)
|
| 59 |
+
|
| 60 |
+
def show_mask(m):
|
| 61 |
+
img = np.ones((m.shape[0], m.shape[1], 3))
|
| 62 |
+
color_mask = np.random.random((1, 3)).tolist()[0]
|
| 63 |
+
for i in range(3):
|
| 64 |
+
img[:,:,0] = 1
|
| 65 |
+
img[:,:,1] = 0
|
| 66 |
+
img[:,:,2] = 0
|
| 67 |
+
|
| 68 |
+
return np.dstack((img, m*0.35))
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def iou(mask1, mask2):
|
| 72 |
+
intersection = np.logical_and(mask1, mask2)
|
| 73 |
+
union = np.logical_or(mask1, mask2)
|
| 74 |
+
iou_score = np.sum(intersection) / np.sum(union)
|
| 75 |
+
return iou_score
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def sort_and_deduplicate(sam_masks, iou_threshold=0.8):
|
| 79 |
+
# Sort the sam_masks list based on the area value
|
| 80 |
+
sorted_masks = sorted(sam_masks, key=lambda x: x['area'], reverse=True)
|
| 81 |
+
|
| 82 |
+
# Deduplicate masks based on the given iou_threshold
|
| 83 |
+
filtered_masks = []
|
| 84 |
+
for mask in sorted_masks:
|
| 85 |
+
duplicate = False
|
| 86 |
+
for filtered_mask in filtered_masks:
|
| 87 |
+
if iou(mask['segmentation'], filtered_mask['segmentation']) > iou_threshold:
|
| 88 |
+
duplicate = True
|
| 89 |
+
break
|
| 90 |
+
|
| 91 |
+
if not duplicate:
|
| 92 |
+
filtered_masks.append(mask)
|
| 93 |
+
|
| 94 |
+
return filtered_masks
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
relation_classes = ['over',
|
| 98 |
+
'in front of',
|
| 99 |
+
'beside',
|
| 100 |
+
'on',
|
| 101 |
+
'in',
|
| 102 |
+
'attached to',
|
| 103 |
+
'hanging from',
|
| 104 |
+
'on back of',
|
| 105 |
+
'falling off',
|
| 106 |
+
'going down',
|
| 107 |
+
'painted on',
|
| 108 |
+
'walking on',
|
| 109 |
+
'running on',
|
| 110 |
+
'crossing',
|
| 111 |
+
'standing on',
|
| 112 |
+
'lying on',
|
| 113 |
+
'sitting on',
|
| 114 |
+
'flying over',
|
| 115 |
+
'jumping over',
|
| 116 |
+
'jumping from',
|
| 117 |
+
'wearing',
|
| 118 |
+
'holding',
|
| 119 |
+
'carrying',
|
| 120 |
+
'looking at',
|
| 121 |
+
'guiding',
|
| 122 |
+
'kissing',
|
| 123 |
+
'eating',
|
| 124 |
+
'drinking',
|
| 125 |
+
'feeding',
|
| 126 |
+
'biting',
|
| 127 |
+
'catching',
|
| 128 |
+
'picking',
|
| 129 |
+
'playing with',
|
| 130 |
+
'chasing',
|
| 131 |
+
'climbing',
|
| 132 |
+
'cleaning',
|
| 133 |
+
'playing',
|
| 134 |
+
'touching',
|
| 135 |
+
'pushing',
|
| 136 |
+
'pulling',
|
| 137 |
+
'opening',
|
| 138 |
+
'cooking',
|
| 139 |
+
'talking to',
|
| 140 |
+
'throwing',
|
| 141 |
+
'slicing',
|
| 142 |
+
'driving',
|
| 143 |
+
'riding',
|
| 144 |
+
'parked on',
|
| 145 |
+
'driving on',
|
| 146 |
+
'about to hit',
|
| 147 |
+
'kicking',
|
| 148 |
+
'swinging',
|
| 149 |
+
'entering',
|
| 150 |
+
'exiting',
|
| 151 |
+
'enclosing',
|
| 152 |
+
'leaning on',]
|