
File size: 8,104 Bytes
2790a7b cce2620 2790a7b 6563183 2790a7b cce2620 2790a7b cce2620 f15bebe cce2620 2790a7b 4f492b4 cce2620 2790a7b 6e74774 1ea488c cce2620 2790a7b cce2620 2790a7b cce2620 2790a7b cce2620 2790a7b b672910 cce2620 2790a7b cce2620 2790a7b b672910 2790a7b cce2620 2790a7b cce2620 2790a7b c140a95 cce2620 6563183 cce2620 2790a7b cce2620 2c7cea9 6563183 cce2620 577b530 cce2620 a379e21 6563183 a379e21 cce2620 a379e21 cce2620 12c2fe6 cce2620 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 |
# Copyright 2020 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import evaluate
import datasets
from .tokenizer_13a import Tokenizer13a
_CITATION = """\
@inproceedings{liu-etal-2022-rethinking,
title = "Rethinking and Refining the Distinct Metric",
author = "Liu, Siyang and
Sabour, Sahand and
Zheng, Yinhe and
Ke, Pei and
Zhu, Xiaoyan and
Huang, Minlie",
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)",
year = "2022",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-short.86",
doi = "10.18653/v1/2022.acl-short.86",
}
@inproceedings{li-etal-2016-diversity,
title = "A Diversity-Promoting Objective Function for Neural Conversation Models",
author = "Li, Jiwei and
Galley, Michel and
Brockett, Chris and
Gao, Jianfeng and
Dolan, Bill",
booktitle = "Proceedings of the 2016 Conference of the North {A}merican Chapter of the Association for Computational Linguistics: Human Language Technologies",
year = "2016",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/N16-1014",
doi = "10.18653/v1/N16-1014",
}
"""
# 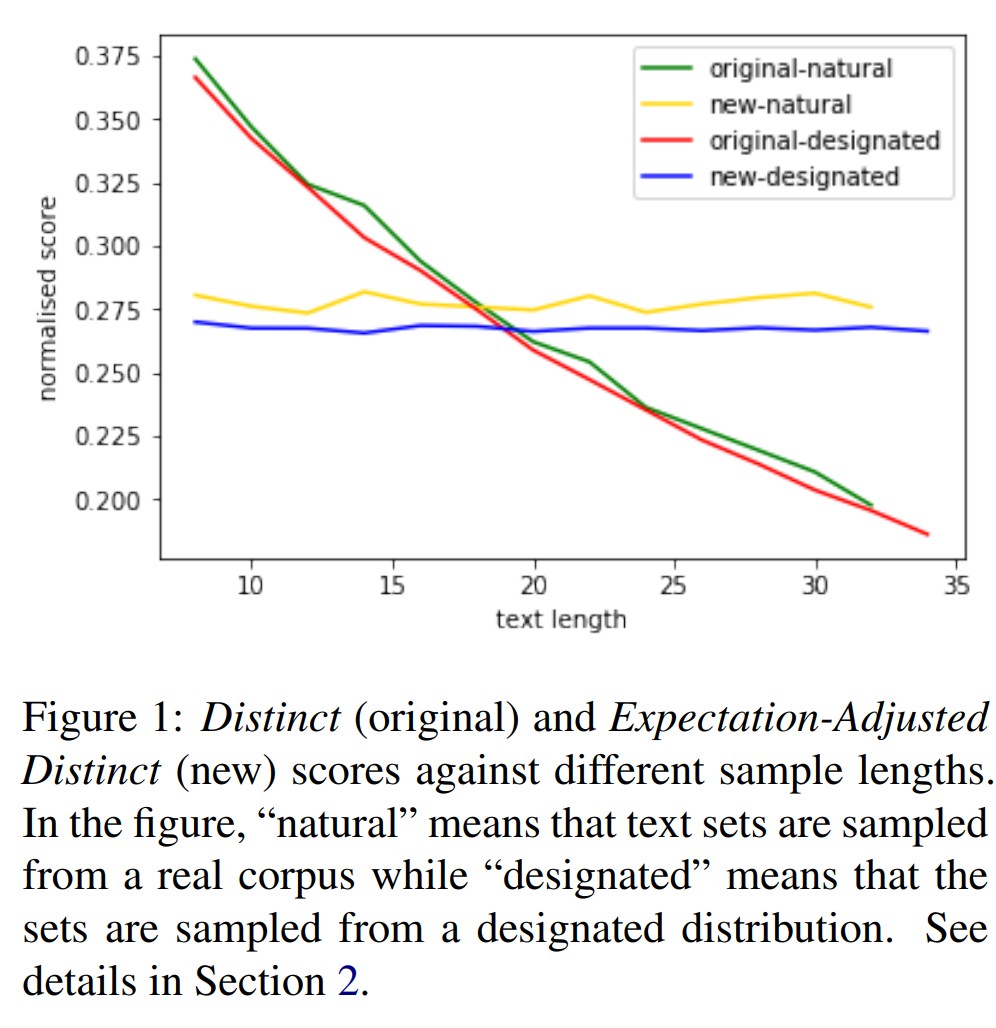
_DESCRIPTION = """\
Distinct metric is to calculate corpus-level diversity of language. We provide two versions of distinct score. Expectation-Adjusted-Distinct (EAD) is the default one, which removes
the biases of the original distinct score on lengthier sentences (see Figure below). Distinct is the original version.
"""
_KWARGS_DESCRIPTION = """
Calculates how good are predictions given some references, using certain scores
Args:
predictions: list of sentecnes. Each prediction should be a string.
Returns:
Expectation-Adjusted-Distinct
Distinct-1
Distinct-2
Distinct-3
Examples:
Examples should be written in doctest format, and should illustrate how
to use the function.
>>> my_new_module = evaluate.load("lsy641/distinct")
>>> results = my_new_module.compute(references=["Hi.", "I'm sorry to hear that", "I don't know"], vocab_size=50257)
>>> print(results)
>>> dataset = ["This is my friend jack", "I'm sorry to hear that", "But you know I am the one who always support you", "Welcome to our family"]
>>> results = my_new_module.compute(references=["Hi.", "I'm sorry to hear that", "I don't know"], dataForVocabCal = dataset)
>>> print(results)
>>> results = my_new_module.compute(references=["Hi.", "I'm sorry to hear that", "I don't know"], mode="Distinct")
>>> print(results)
"""
# TODO: Define external resources urls if needed
BAD_WORDS_URL = "http://url/to/external/resource/bad_words.txt"
@evaluate.utils.file_utils.add_start_docstrings(_DESCRIPTION, _KWARGS_DESCRIPTION)
class distinct(evaluate.Measurement):
def _info(self):
return evaluate.MeasurementInfo(
# This is the description that will appear on the modules page.
module_type="measurement",
description=_DESCRIPTION,
citation=_CITATION,
inputs_description=_KWARGS_DESCRIPTION,
# This defines the format of each prediction and reference
features=datasets.Features({
'predictions': datasets.Value('string')
}),
# Homepage of the module for documentation
homepage="https://huggingface.co/spaces/lsy641/distinct",
# Additional links to the codebase or references
codebase_urls=["https://github.com/lsy641/Expectation-Adjusted-Distinct/tree/main"],
reference_urls=["https://aclanthology.org/2022.acl-short.86/"]
)
def _download_and_prepare(self, dl_manager):
"""Optional: download external resources useful to compute the scores"""
def _compute(self, predictions, dataForVocabCal=None, vocab_size=None, tokenizer=Tokenizer13a(), mode="Expectation-Adjusted-Distinct"):
from nltk.util import ngrams
"""Returns the scores"""
if mode == "Expectation-Adjusted-Distinct" and vocab_size is None and dataForVocabCal is None:
raise ValueError("Either vocab_size or dataForVocabCal needs to be specified when using mode 'Expectation-Adjusted-Distinct'. See https://github.com/lsy641/Expectation-Adjusted-Distinct/blob/main/EAD.ipynb for vocab_size specification. \n Or use mode='Distinct' to get original version of distinct score.")
elif mode == "Expectation-Adjusted-Distinct" and vocab_size is not None and dataForVocabCal is not None:
raise Warning("We've detected that both vocab_size and dataForVocabCal are specified. We will use dataForVocabCal.")
elif mode == "Distinct":
pass
if mode == "Expectation-Adjusted-Distinct" and dataForVocabCal is not None:
if isinstance(dataForVocabCal, list) and len(dataForVocabCal) > 0 and isinstance(dataForVocabCal[0], str):
vocab = set()
for sentence in dataForVocabCal:
# if tokenizer == "white_space":
# vocab = vocab | set(sentence.split(" "))
# else:
vocab = vocab | set(tokenizer.tokenize(sentence))
vocab_size = len(vocab)
else:
raise TypeError("Argument dataForVocabCal should be a list of strings")
distinct_tokens = set()
distinct_tokens_2grams = set()
distinct_tokens_3grams = set()
total_tokens = []
total_tokens_2grams = []
total_tokens_3grams = []
for prediction in predictions:
try:
tokens = list(tokenizer.tokenize(prediction))
tokens_2grams = list(ngrams(list(tokenizer.tokenize(prediction)), 2, pad_left=True, left_pad_symbol='<s>'))
tokens_3grams = list(ngrams(list(tokenizer.tokenize(prediction)), 3, pad_left=True, left_pad_symbol='<s>'))
except Exception as e:
raise e
distinct_tokens = distinct_tokens | set(tokens)
distinct_tokens_2grams = distinct_tokens_2grams | set(tokens_2grams)
distinct_tokens_3grams = distinct_tokens_3grams | set(tokens_3grams)
total_tokens.extend(tokens)
total_tokens_2grams.extend(list(tokens_2grams))
total_tokens_3grams.extend(list(tokens_3grams))
Distinct_1 = len(distinct_tokens)/len(total_tokens)
Distinct_2 = len(distinct_tokens_2grams)/len(total_tokens_2grams)
Distinct_3 = len(distinct_tokens_3grams)/len(total_tokens_3grams)
if mode == "Expectation-Adjusted-Distinct":
Expectation_Adjusted_Distinct = len(distinct_tokens)/(vocab_size*(1-((vocab_size-1)/vocab_size)**len(total_tokens)))
return {
"Expectation-Adjusted-Distinct": Expectation_Adjusted_Distinct,
"Distinct-1": Distinct_1,
"Distinct-2": Distinct_2,
"Distinct-3": Distinct_3
}
if mode == "Distinct":
return {
"Distinct-1": Distinct_1,
"Distinct-2": Distinct_2,
"Distinct-3": Distinct_3
} |