Spaces:
Running

Tips to speed up 13k x 13k blue computations?

I am using evaluate's bleu implementation to run a 13k X 13k similarity computations. The code has been running for over 20 hrs and still going. Any tips for speed up? Is there a way to make the process parallel?
I also notice, that since the evaluate takes tokenizer in the function call, it means it is tokenizing the text every time - which can be avoided by tokenizing everything once. Is there a way to do this? Or does evaluate automatically implement such caching?

Hi
@shaily99
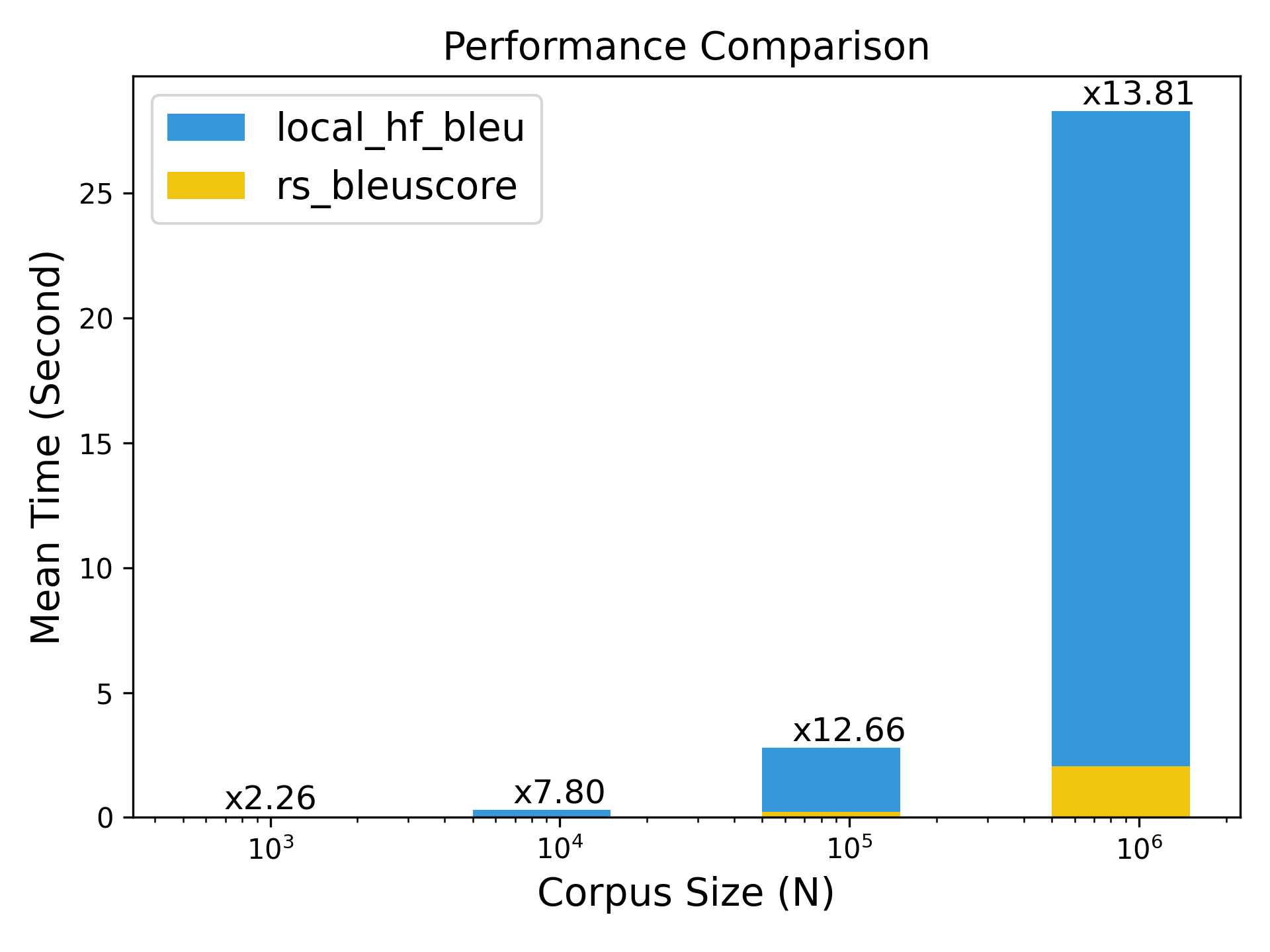
! I just build a bleu calculation package(bleuscore) which is aimed to speed up the bleu score calculation, you can find it in GitHub.
According to my simple benchmark(the comprehension benchmark is coming soon), which is faster than hf evaluate many times, maybe you can give it a try~
ps: I'm wondering is the 13kX13k dataset available publicly? I want to benchmark on a big real dataset now, but I don't find a proper dataset yet.
Thanks, I ll take a look.
Re the benchmark: It isn't out yet, hopefully soon.
Sorry for the late reply. I have pushed the benchmark results to GitHub and you can check them out in the bleuscore repo
TLDR: We got more than 10x speedup when the corpus size beyond 100K