
You need to agree to share your contact information to access this model
This repository is publicly accessible, but you have to accept the conditions to access its files and content.
Guided-TTS-2 is intended for research purposes only. By clicking on "Request access", the user agrees to the following terms and conditions.
Terms of Access:
The "Researcher" has requested permission to use Guided-TTS ("the Model"). In exchange for such permission, Researcher hereby agrees to the following terms and conditions:
- Researcher shall use the Model only for non-commercial research and educational purposes.
- The authors make no representations or warranties regarding the Model, including but not limited to warranties of non-infringement or fitness for a particular purpose.
- Researcher accepts full responsibility for his or her use of the Model and shall defend and indemnify the authors including their collaborators and trustees, against any and all claims arising from Researcher's use of the Model, including but not limited to Researcher's use of any samples he or she may create from the Model.
- The authors reserve the right to terminate Researcher's access to the Model at any time.
- If Researcher is employed by a for-profit, commercial entity, Researcher's employer shall also be bound by these terms and conditions, and Researcher hereby represents that he or she is fully authorized to enter into this agreement on behalf of such employer.
- Researcher agrees to present samples generated from the Model as such and to not use generated samples for any kinds of misuse including, but not limited to voice phishing, deep fake or trolling.
Please also fill out the following fields for the authors to be able to contact you.
Log in or Sign Up to review the conditions and access this model content.
Guided-TTS 2: A Diffusion Model for High-quality Adaptive Text-to-Speech with Untranscribed Data
Overview
Authors
Sungwon Kim Heeseung Kim Sungroh Yoon
Abstract
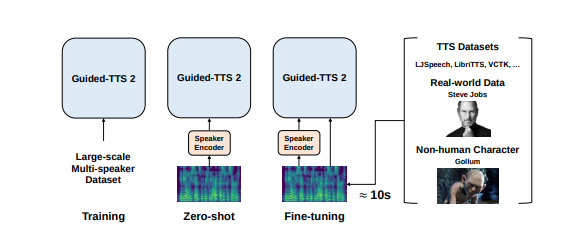
We propose Guided-TTS 2, a diffusion-based generative model for high-quality adaptive TTS using untranscribed data. Guided-TTS 2 combines a speaker-conditional diffusion model with a speaker-dependent phoneme classifier for adaptive text-to-speech. We train the speaker-conditional diffusion model on large-scale untranscribed datasets for a classifier-free guidance method and further fine-tune the diffusion model on the reference speech of the target speaker for adaptation, which only takes 40 seconds. We demonstrate that Guided-TTS 2 shows comparable performance to high-quality single-speaker TTS baselines in terms of speech quality and speaker similarity with only a ten-second untranscribed data. We further show that Guided-TTS 2 outperforms adaptive TTS baselines on multi-speaker datasets even with a zero-shot adaptation setting. Guided-TTS 2 can adapt to a wide range of voices only using untranscribed speech, which enables adaptive TTS with the voice of non-human characters such as Gollum in “The Lord of the Rings”.
Samples
- (add audio samples here) ...
Societal Impact
Guided-TTS 2 has an advantage in significantly reducing data required for high-quality adaptive TTS. In addition, Guided-TTS 2 can adapt to not only human voice but also non-human characters such as Gollum, which shows the possibility of extension to TTS for non-human characters in industries such as games and movies. On the other hand, 10-second untranscribed speech for the target speaker is easy to obtain through recording or YouTube clips for celebrities, and the contribution of Guided-TTS 2 that reduces the data required for high-quality adaptive TTS makes a lot of room for misuse. Guided-TTS 2 is likely to be misused as voice phishing for individuals or to have a fatal effect on the security system through voice. Given this potential misuse, we’ve decided not to release our code. Although we do not release the code, due to the adaptation ability of the diffusion-based model, we expect that the adaptive TTS technology is highly likely to be misused like Deepfake. We leave the research on anti-spoofing that distinguishes generated speech from real audio as future work, considering the potential for misuse of Guided-TTS 2.