
File size: 1,692 Bytes
b039e3a f763ec3 e3f20ce f763ec3 b039e3a f763ec3 b039e3a f763ec3 b039e3a f763ec3 b039e3a f763ec3 b039e3a f763ec3 b039e3a f763ec3 b039e3a f763ec3 b039e3a f763ec3 b039e3a f763ec3 b039e3a f763ec3 b039e3a f763ec3 b039e3a f763ec3 b039e3a f763ec3 b039e3a f763ec3 b039e3a f763ec3 b039e3a f763ec3 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
---
datasets:
- uonlp/CulturaX
- l3cube-pune/MarathiNLP
- ai4bharat/samanantar
language:
- mr
tags:
- marathi
library_name: transformers
pipeline_tag: text-generation
license: llama2
---
# Misal-7B-base-v0.1
Built by - [smallstep.ai](https://smallstep.ai/)
## Making of Misal?
Detailed blog [here](https://smallstep.ai/making-misal).
## Pretraining :
During the pretraining phase of our large language model, the model was exposed to a vast corpus of text data comprising approximately 2 billion Marathi tokens. This corpus primarily consisted of newspaper data spanning the years 2016 to 2022, sourced primarily from the CulturaX dataset. In addition to this, we supplemented our training data with additional sources such as l3cube, ai4bharat, and other internet-based datasets.
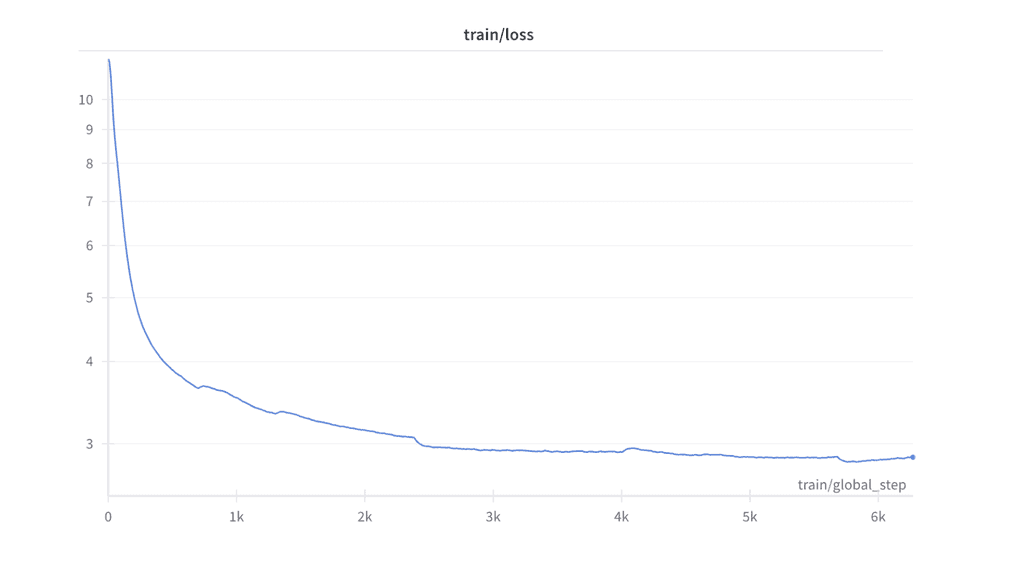
Our model was pretrained using a single A100 80GB GPU on the QBlocks platform. We chose bfloat16 as training precision due to stability issues with float16 precision.
We used Parameter efficient finetuning for pretraining, using Low Rank Adaptation (LoRA), to achieve a training loss of approximately 2.8 after training for almost 2 days.
```python
# LoRA config
peft:
r: 64
lora_alpha: 128
target_modules:
[
"q_proj", "v_proj",
"k_proj", "o_proj",
"gate_proj", "up_proj",
"down_proj",
]
lora_dropout: 0.05
bias: "none"
task_type: "CAUSAL_LM"
modules_to_save: ["embed_tokens", "lm_head"]
```
## License
The model inherits the license from meta-llama/Llama-2-7b.
### Team
Sagar Sarkale, Abhijeet Katte, Prasad Mane, Shravani Chavan |