
File size: 7,839 Bytes
ee6423c 43b2fb0 e048266 43b2fb0 ee6423c 16569a5 ee6423c 16569a5 ee6423c 9c514e6 ee6423c 3177b15 2abbda1 e51cebe 2abbda1 ee6423c 8d6210b ee6423c 43b2fb0 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 |
---
language:
- en
- th
license: llama3
tags:
- instruct
- chat
pipeline_tag: text-generation
model-index:
- name: llama-3-typhoon-v1.5-8b-instruct
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 60.41
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=scb10x/llama-3-typhoon-v1.5-8b-instruct
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 80.79
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=scb10x/llama-3-typhoon-v1.5-8b-instruct
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 64.46
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=scb10x/llama-3-typhoon-v1.5-8b-instruct
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 53.25
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=scb10x/llama-3-typhoon-v1.5-8b-instruct
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 77.66
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=scb10x/llama-3-typhoon-v1.5-8b-instruct
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 57.16
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=scb10x/llama-3-typhoon-v1.5-8b-instruct
name: Open LLM Leaderboard
---
**Llama-3-Typhoon-v1.5-8B: Thai Large Language Model (Instruct)**
**Llama-3-Typhoon-v1.5-8B-instruct** is a *instruct* Thai 🇹🇭 large language model with 8 billion parameters, and it is based on Llama3-8B.
For release post, please see our [blog](https://blog.opentyphoon.ai/typhoon-1-5-release-a9364cb8e8d7).
*To acknowledge Meta's effort in creating the foundation model and to comply with the license, we explicitly include "llama-3" in the model name.
## **Model Description**
- **Model type**: A 8B instruct decoder-only model based on Llama architecture.
- **Requirement**: transformers 4.38.0 or newer.
- **Primary Language(s)**: Thai 🇹🇭 and English 🇬🇧
- **License**: [Llama 3 Community License](https://llama.meta.com/llama3/license/)
## **Performance**
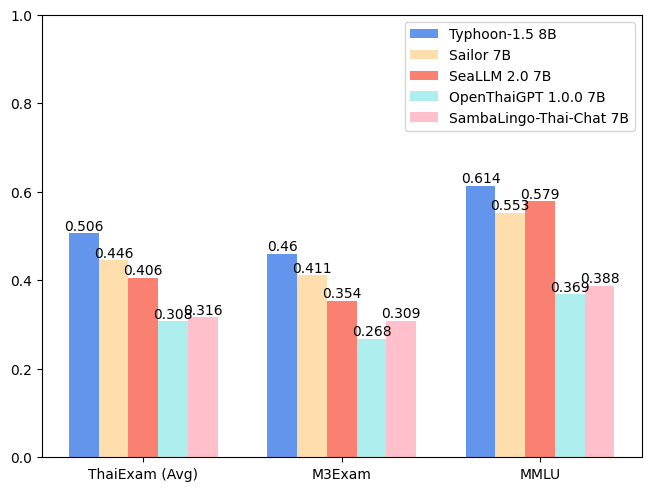
| Model | ONET | IC | TGAT | TPAT-1 | A-Level | Average (ThaiExam) | M3Exam | MMLU |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Typhoon-1.0 (Mistral) | 0.379 | 0.393 | 0.700 | 0.414 | 0.324 | 0.442 | 0.391 | 0.547 |
| Typhoon-1.5 8B (Llama3) | ***0.446*** | ***0.431*** | ***0.722*** | ***0.526*** | ***0.407*** | ***0.506*** | ***0.460*** | ***0.614*** |
| Sailor 7B | 0.372 | 0.379 | 0.678 | 0.405 | 0.396 | 0.446 | 0.411 | 0.553 |
| SeaLLM 2.0 7B | 0.327 | 0.311 | 0.656 | 0.414 | 0.321 | 0.406 | 0.354 | 0.579 |
| OpenThaiGPT 1.0.0 7B | 0.238 | 0.249 | 0.444 | 0.319 | 0.289 | 0.308 | 0.268 | 0.369 |
| SambaLingo-Thai-Chat 7B | 0.251 | 0.241 | 0.522 | 0.302 | 0.262 | 0.316 | 0.309 | 0.388 |
## Usage Example
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "scb10x/llama-3-typhoon-v1.5-8b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a helpful assistant who're always speak Thai."},
{"role": "user", "content": "ขอสูตรไก่ย่าง"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = model.generate(
input_ids,
max_new_tokens=512,
eos_token_id=terminators,
do_sample=True,
temperature=0.4,
top_p=0.9,
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
```
## Chat Template
We use llama3 chat-template.
```python
{% set loop_messages = messages %}{% for message in loop_messages %}{% set content = '<|start_header_id|>' + message['role'] + '<|end_header_id|>\n\n'+ message['content'] | trim + '<|eot_id|>' %}{% if loop.index0 == 0 %}{% set content = bos_token + content %}{% endif %}{{ content }}{% endfor %}{% if add_generation_prompt %}{{ '<|start_header_id|>assistant<|end_header_id|>\n\n' }}{% endif %}
```
## **Intended Uses & Limitations**
This model is an instructional model. However, it’s still undergoing development. It incorporates some level of guardrails, but it still may produce answers that are inaccurate, biased, or otherwise objectionable in response to user prompts. We recommend that developers assess these risks in the context of their use case.
## **Follow us**
**https://twitter.com/opentyphoon**
## **Support**
**https://discord.gg/CqyBscMFpg**
## **SCB10X AI Team**
- Kunat Pipatanakul, Potsawee Manakul, Sittipong Sripaisarnmongkol, Pathomporn Chokchainant, Kasima Tharnpipitchai
- If you find Typhoon-8B useful for your work, please cite it using:
```
@article{pipatanakul2023typhoon,
title={Typhoon: Thai Large Language Models},
author={Kunat Pipatanakul and Phatrasek Jirabovonvisut and Potsawee Manakul and Sittipong Sripaisarnmongkol and Ruangsak Patomwong and Pathomporn Chokchainant and Kasima Tharnpipitchai},
year={2023},
journal={arXiv preprint arXiv:2312.13951},
url={https://arxiv.org/abs/2312.13951}
}
```
## **Contact Us**
- General & Collaboration: **[kasima@scb10x.com](mailto:kasima@scb10x.com)**, **[pathomporn@scb10x.com](mailto:pathomporn@scb10x.com)**
- Technical: **[kunat@scb10x.com](mailto:kunat@scb10x.com)**
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_scb10x__llama-3-typhoon-v1.5-8b-instruct)
| Metric |Value|
|---------------------------------|----:|
|Avg. |65.62|
|AI2 Reasoning Challenge (25-Shot)|60.41|
|HellaSwag (10-Shot) |80.79|
|MMLU (5-Shot) |64.46|
|TruthfulQA (0-shot) |53.25|
|Winogrande (5-shot) |77.66|
|GSM8k (5-shot) |57.16|
|