
Guided Interpretable Facial Expression Recognition via Spatial Action Unit Cues (FG2024)
by Soufiane Belharbi1, Marco Pedersoli1, Alessandro Lameiras Koerich1, Simon Bacon2, Eric Granger1
1 LIVIA, Dept. of Systems Engineering, ÉTS, Montreal, Canada
2 Dept. of Health, Kinesiology & Applied Physiology, Concordia University, Montreal, Canada
![]()
![]()
Abstract
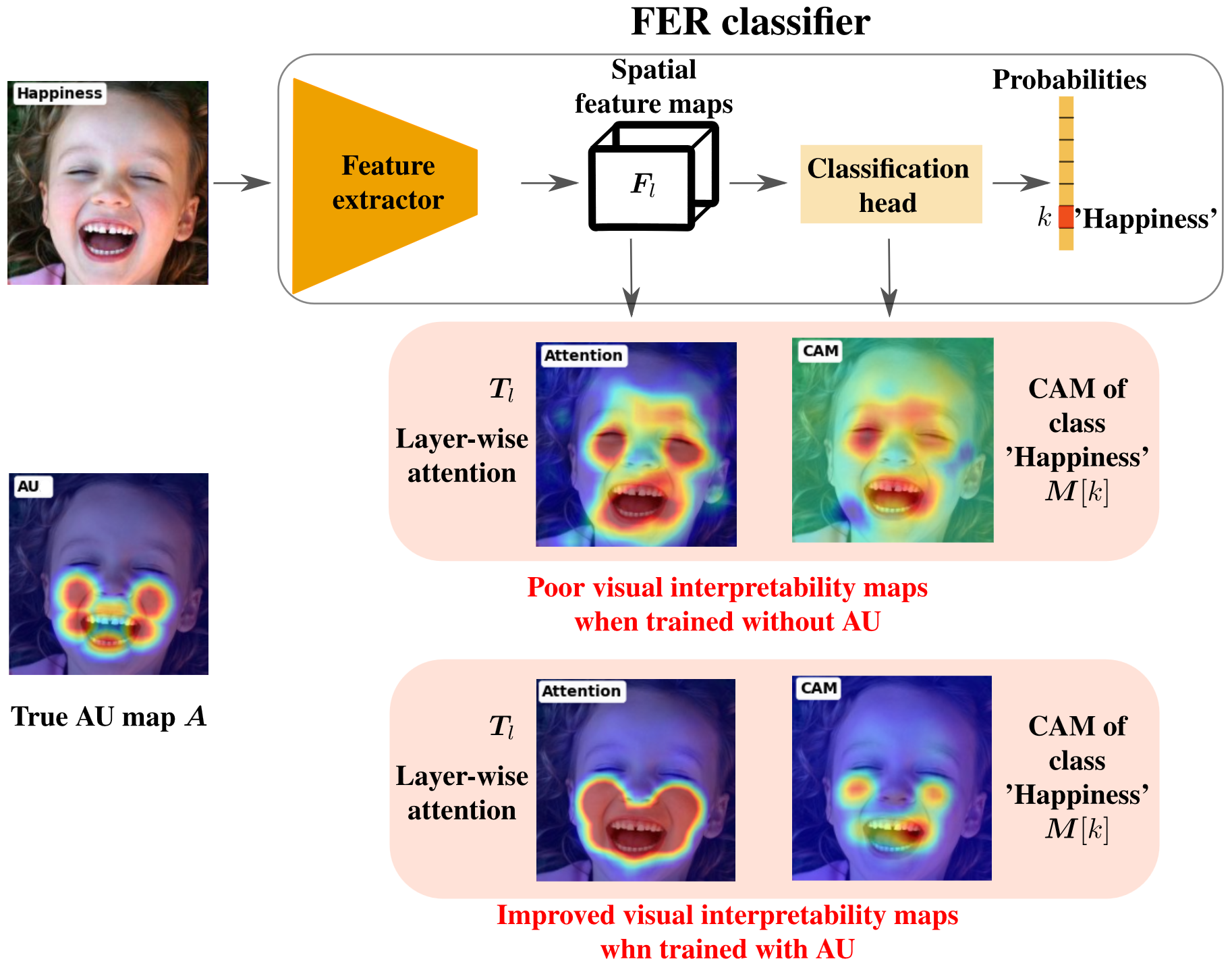
Although state-of-the-art classifiers for facial expression recognition (FER) can achieve a high level of accuracy, they lack interpretability, an important feature for end-users. Experts typically associate spatial action units (AU) from a codebook to facial regions for the visual interpretation of expressions. In this paper, the same expert steps are followed. A new learning strategy is proposed to explicitly incorporate AU cues into classifier training, allowing to train deep interpretable models. During training, this AU codebook is used, along with the input image expression label, and facial landmarks, to construct a AU heatmap that indicates the most discriminative image regions of interest w.r.t the facial expression. This valuable spatial cue is leveraged to train a deep interpretable classifier for FER. This is achieved by constraining the spatial layer features of a classifier to be correlated with AU heatmaps. Using a composite loss, the classifier is trained to correctly classify an image while yielding interpretable visual layer-wise attention correlated with AU maps, simulating the expert decision process. Our strategy only relies on image class expression for supervision, without additional manual annotations. Our new strategy is generic, and can be applied to any deep CNN- or transformer-based classifier without requiring any architectural change or significant additional training time. Our extensive evaluation on two public benchmarks RAFDB, and AFFECTNET datasets shows that our proposed strategy can improve layer-wise interpretability without degrading classification performance. In addition, we explore a common type of interpretable classifiers that rely on class activation mapping (CAM) methods, and show that our approach can also improve CAM interpretability.
Code: Pytorch 2.0.0
Citation:
@InProceedings{belharbi24-fer-aus,
title={Guided Interpretable Facial Expression Recognition via Spatial Action Unit Cues},
author={Belharbi, S. and Pedersoli, M. and Koerich, A. L. and Bacon, S. and Granger, E.},
booktitle={International Conference on Automatic Face and Gesture Recognition},
year={2024}
}
Pre-trained models:
This repository contains the pretrained weights for this paper. They are stored in the file shared-trained-models.tar.gz. The file is 5.7GB. It contains 44 models (2 datasets (RAF-DB, AffecNet) x 11 methods x 2 [with/without AUs]). It allows reproducing this table:
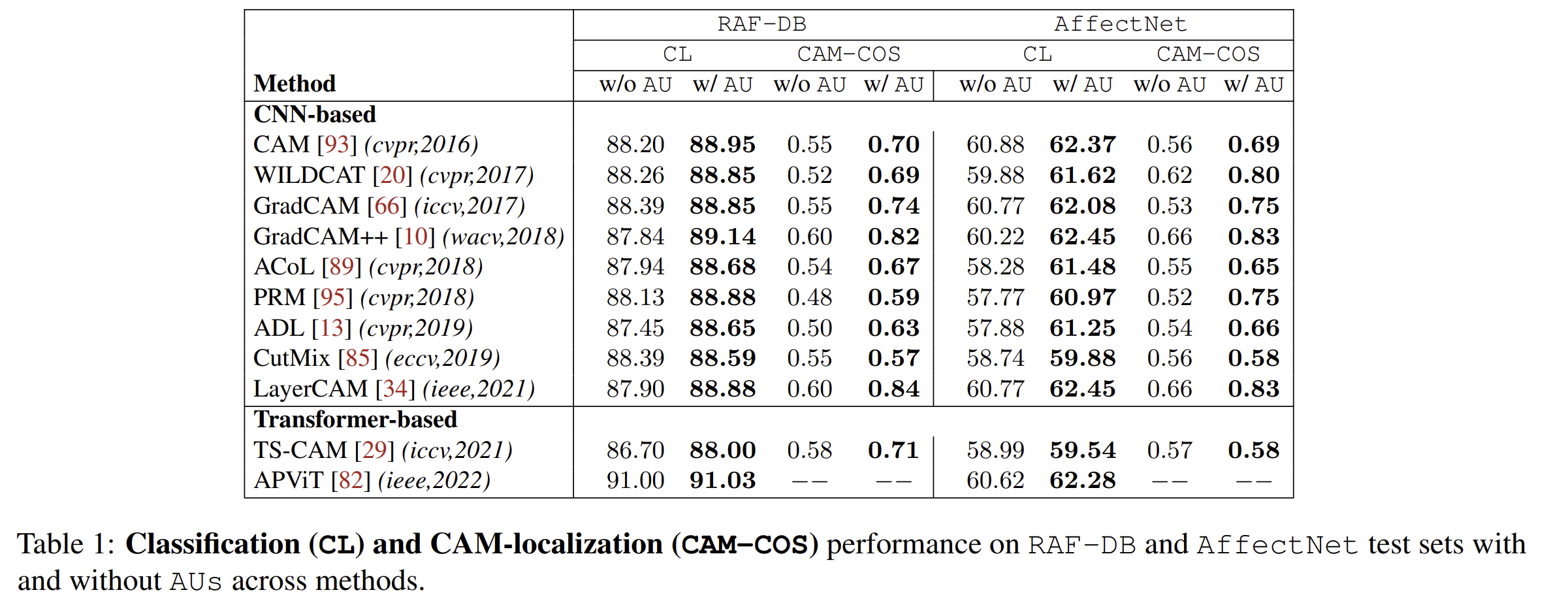
We also provide the folds and the extracted facial landmarks in this file: folds.tar.gz .
For evaluation, please see the code in the github repository: https://github.com/sbelharbi/interpretable-fer-aus.