
TrOCR (small sized model)
We present a new version of the small TrOCR model, fine-tuned on a self-generated Spanish dataset. The TrOCR architecture was initially introduced in the paper TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models by Li et al. and is available in the associated repository.
This model has been specialized for printed fonts and does not support handwritten recognition.
Hiring
We are hiring at all levels (including FTE researchers and interns)! If you are interested in working with us on Computer Vision, NLP and Document AI please send your resume to jobs@qantev.com or apply to the many open positions at Qantev Job Board.
Model presentation
The TrOCR model architecture is based on the Transformer framework, comprising an image Transformer as the encoder and a text Transformer as the decoder.
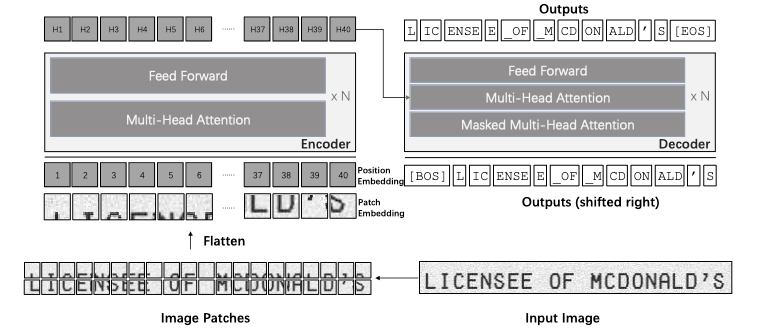
The encoder takes input images, decomposes them into patches, and processes them to obtain visual features. These features are then used by the decoder to generate wordpiece sequences in an autoregressive way, guided by the visual information and previous predictions.
This design allows TrOCR to leverage pre-trained models for image understanding and language modeling, resulting in state-of-the-art performances.
Dataset
As there was no publicly available dataset for training and testing Spanish OCR, we opted to create our own. This involved scraping 131,000 random Wikipedia pages and extracting 2,000,000 samples, ranging from single-word instances to 10-word sentences.
Subsequently, we artificially generated images from these samples, applied various data augmentation techniques, and achieved results such as the following:

Note: We observed that generating images on-the-fly during training was faster than reading them from a pre-existing folder.
Metrics
Regrettably, there is currently no established benchmark dataset specifically designed for evaluating Optical Character Recognition (OCR) performance in Spanish. To provide an indication of the efficacy of our OCR, we present benchmarks on the XFUND dataset in Spanish for the small, base, and large models. Additionally, we include a comparative analysis with EasyOCR.
| CER | WER | |
|---|---|---|
| EasyOCR | 0.1916 | 0.3353 |
| qantev/trocr-small-spanish | 0.1059 | 0.2545 |
| qantev/trocr-base-spanish | 0.0732 | 0.2028 |
| qantev/trocr-large-spanish | 0.0632 | 0.1817 |
(Nota bene: Please note that the XFUND dataset contains mislabeled data, which could potentially impact the results in this benchmark.)
Intended uses & limitations
While this model is freely available for use, it's essential to note that it hasn't been trained on handwritten texts and therefore may not accurately recognize handwritten content. Additionally, its proficiency is limited when it comes to accurately reading two lines of text or vertical text.
This model has to be used with conjunction with a text detection model.
How to use
Here is how to use this model in PyTorch:
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
from PIL import Image
import requests
url = 'https://huggingface.co/qantev/trocr-small-spanish/resolve/main/example_1.png'
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
processor = TrOCRProcessor.from_pretrained('qantev/trocr-small-spanish')
model = VisionEncoderDecoderModel.from_pretrained('qantev/trocr-small-spanish')
pixel_values = processor(images=image, return_tensors="pt").pixel_values
generated_ids = model.generate(pixel_values)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
Citation
@misc{lauar2024spanishtrocrleveragingtransfer,
title={Spanish TrOCR: Leveraging Transfer Learning for Language Adaptation},
author={Filipe Lauar and Valentin Laurent},
year={2024},
eprint={2407.06950},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2407.06950},
}
Contact us
research [at] qantev [dot] com
- Downloads last month
- 611