
Sparse Retriever models
Collection
Independent implementation of various sparse retrievers.
•
2 items
•
Updated
•
1
a.k.a splade-cocondenser* and family) for the Industry setting.
This work stands on the shoulders of 2 robust researches: Naver's From Distillation to Hard Negative Sampling: Making Sparse Neural IR Models More Effective paper and Google's SparseEmbed. Props to both the teams for such a robust work.
This is a 2nd iteration in this series. Try V1 here: prithivida/Splade_PP_en_v1
Beginner ? expand this. Expert in Sparse & Dense representations ? feel free skip to next section 2,
1. Lexical search:
Lexical search with BOW based sparse vectors are strong baselines, but they famously suffer from vocabulary mismatch problem, as they can only do exact term matching. Here are the pros and cons:
2. Semantic Search:
Learned Neural / Dense retrievers (DPR, Sentence transformers*, BGE* models) with approximate nearest neighbors search has shown impressive results. Here are the pros and cons:
3. The big idea:
Getting pros of both searches made sense and that gave rise to interest in learning sparse representations for queries and documents with some interpretability. The sparse representations also double as implicit or explicit (latent, contextualized) expansion mechanisms for both query and documents. If you are new to query expansion learn more here from the master himself Daniel Tunkelang.
4. What a Sparse model learns ?
The model learns to project it's learned dense representations over a MLM head to give a vocabulary distribution. Which is just to say the model can do automatic token expansion. (Image courtesy of pinecone)

SPLADE models are a fine balance between retrieval effectiveness (quality) and retrieval efficiency (latency and $), with that in mind we did very minor retrieval efficiency tweaks to make it more suitable for a industry setting. (Pure MLE folks should not conflate efficiency to model inference efficiency. Our main focus is on retrieval efficiency. Hereinafter efficiency is a short hand for retrieval efficiency unless explicitly qualified otherwise. Not that inference efficiency is not important, we will address that subsequently.)
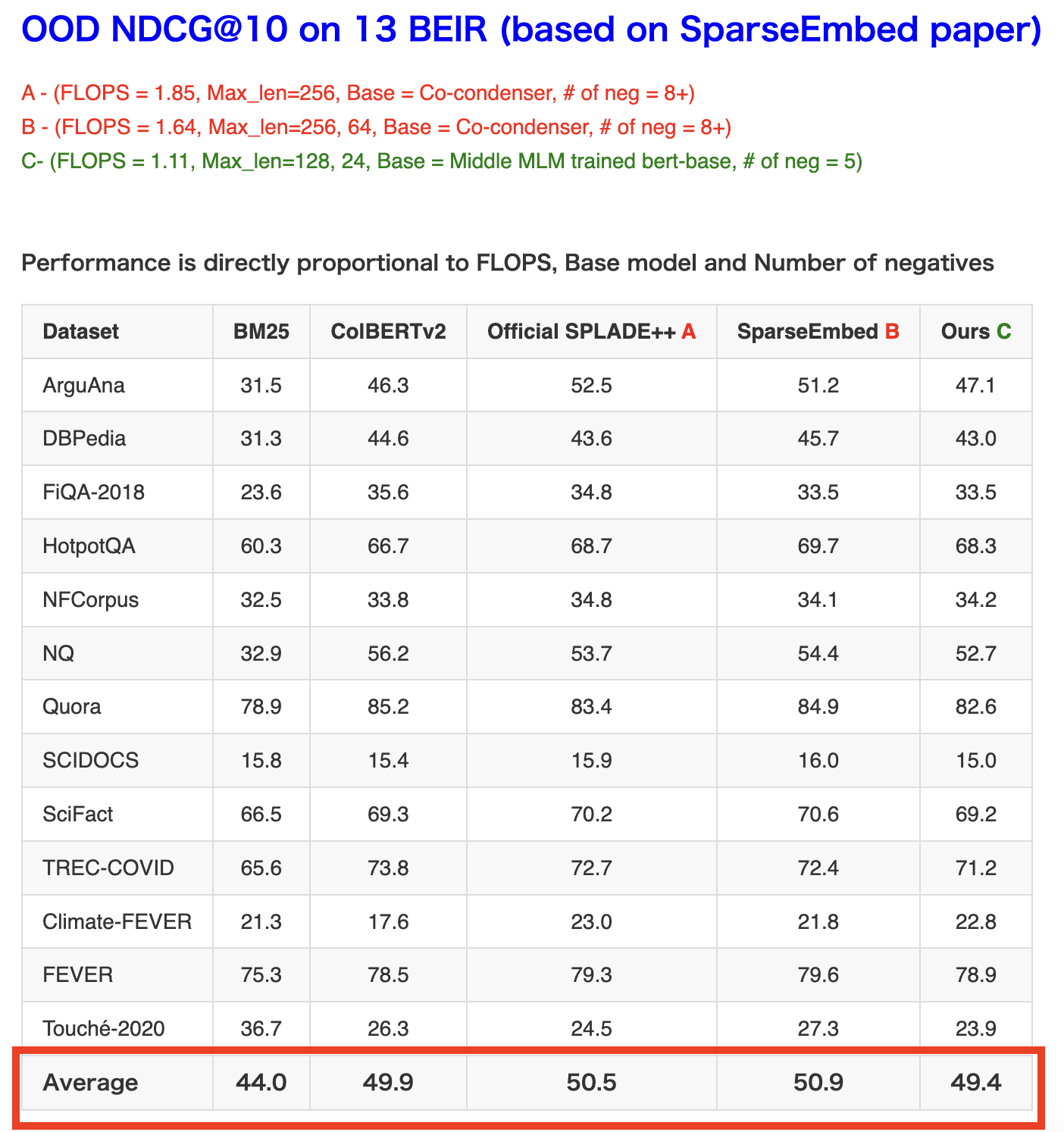
TL;DR of Our attempt & results

Note: The paper refers to the best performing models as SPLADE++, hence for consistency we are reusing the same.
While ONLY a empirical analysis on large sample make sense here is a spot checking - a qualitatively example to give you an idea. Our models achieve par competitive effectiveness with ~4% and ~48%, lesser tokens comparable SPLADE++ models including SoTA. (We will show Quantitative results in the next section.)
So, by design "how to beat SoTA MRR?" was never our goal, Instead "At what cost can we achieve an acceptable effectiveness i.e. MRR@10". Non-chalantly reducing lambda values (λQ,λD, see above table) will achieve a better MRR. But Lower lambda values = Higher FLOPS = More tokens = Poorer efficiency. This is NOT desirable for a Industry setting.
Ours
number of actual dimensions: 121
SPLADE BOW rep:
[('stress', 2.42), ('thermal', 2.31), ('glass', 2.27), ('pan', 1.78), ('heat', 1.66), ('glasses', 1.58), ('crack', 1.42), ('anxiety', 1.36), ('break', 1.31), ('window', 0.91), ('heating', 0.84), ('hot', 0.82), ('adjacent', 0.82), ('hotter', 0.82), ('if', 0.75), ('cause', 0.7), ('caused', 0.7), ('create', 0.7), ('factors', 0.69), ('created', 0.68), ('cracks', 0.67), ('breaks', 0.67), ('area', 0.66), ('##glass', 0.66), ('cracked', 0.63), ('areas', 0.6), ('cracking', 0.59), ('windows', 0.58), ('effect', 0.56), ('causes', 0.56), ('ruin', 0.54), ('severe', 0.54), ('too', 0.53), ('flame', 0.5), ('collapse', 0.49), ('stresses', 0.49), ('or', 0.48), ('physics', 0.47), ('temperature', 0.46), ('get', 0.46), ('heated', 0.45), ('problem', 0.45), ('energy', 0.44), ('hottest', 0.42), ('phenomenon', 0.42), ('sweating', 0.41), ('insulation', 0.39), ('level', 0.39), ('warm', 0.39), ('governed', 0.38), ('formation', 0.37), ('failure', 0.35), ('frank', 0.34), ('cooling', 0.32), ('fracture', 0.31), ('because', 0.31), ('crystal', 0.31), ('determined', 0.31), ('boiler', 0.31), ('mechanical', 0.3), ('shatter', 0.29), ('friction', 0.29), ('levels', 0.29), ('cold', 0.29), ('will', 0.29), ('ceramics', 0.29), ('factor', 0.28), ('crash', 0.28), ('reaction', 0.28), ('fatigue', 0.28), ('hazard', 0.27), ('##e', 0.26), ('anger', 0.26), ('bubble', 0.25), ('process', 0.24), ('cleaning', 0.23), ('surrounding', 0.22), ('theory', 0.22), ('sash', 0.22), ('distraction', 0.21), ('adjoining', 0.19), ('environmental', 0.19), ('ross', 0.18), ('formed', 0.17), ('broken', 0.16), ('affect', 0.16), ('##pan', 0.15), ('graphic', 0.14), ('damage', 0.14), ('bubbles', 0.13), ('windshield', 0.13), ('temporal', 0.13), ('roof', 0.12), ('strain', 0.12), ('clear', 0.09), ('ceramic', 0.08), ('stressed', 0.08), ('##uation', 0.08), ('cool', 0.08), ('expand', 0.07), ('storm', 0.07), ('shock', 0.07), ('psychological', 0.06), ('breaking', 0.06), ('##es', 0.06), ('melting', 0.05), ('burst', 0.05), ('sensing', 0.04), ('heats', 0.04), ('error', 0.03), ('weather', 0.03), ('drink', 0.03), ('fire', 0.03), ('vibration', 0.02), ('induced', 0.02), ('warmer', 0.02), ('leak', 0.02), ('fog', 0.02), ('safety', 0.01), ('surface', 0.01), ('##thermal', 0.0)]
naver/splade-cocondenser-ensembledistil (SoTA, ~4% more tokens + FLOPS = 1.85)
number of actual dimensions: 126
SPLADE BOW rep:
[('stress', 2.25), ('glass', 2.23), ('thermal', 2.18), ('glasses', 1.65), ('pan', 1.62), ('heat', 1.56), ('stressed', 1.42), ('crack', 1.31), ('break', 1.12), ('cracked', 1.1), ('hot', 0.93), ('created', 0.9), ('factors', 0.81), ('broken', 0.73), ('caused', 0.71), ('too', 0.71), ('damage', 0.69), ('if', 0.68), ('hotter', 0.65), ('governed', 0.61), ('heating', 0.59), ('temperature', 0.59), ('adjacent', 0.59), ('cause', 0.58), ('effect', 0.57), ('fracture', 0.56), ('bradford', 0.55), ('strain', 0.53), ('hammer', 0.51), ('brian', 0.48), ('error', 0.47), ('windows', 0.45), ('will', 0.45), ('reaction', 0.42), ('create', 0.42), ('windshield', 0.41), ('heated', 0.41), ('factor', 0.4), ('cracking', 0.39), ('failure', 0.38), ('mechanical', 0.38), ('when', 0.38), ('formed', 0.38), ('bolt', 0.38), ('mechanism', 0.37), ('warm', 0.37), ('areas', 0.36), ('area', 0.36), ('energy', 0.34), ('disorder', 0.33), ('barry', 0.33), ('shock', 0.32), ('determined', 0.32), ('gage', 0.32), ('sash', 0.31), ('theory', 0.31), ('level', 0.31), ('resistant', 0.31), ('brake', 0.3), ('window', 0.3), ('crash', 0.3), ('hazard', 0.29), ('##ink', 0.27), ('ceramic', 0.27), ('storm', 0.25), ('problem', 0.25), ('issue', 0.24), ('impact', 0.24), ('fridge', 0.24), ('injury', 0.23), ('ross', 0.22), ('causes', 0.22), ('affect', 0.21), ('pressure', 0.21), ('fatigue', 0.21), ('leak', 0.21), ('eye', 0.2), ('frank', 0.2), ('cool', 0.2), ('might', 0.19), ('gravity', 0.18), ('ray', 0.18), ('static', 0.18), ('collapse', 0.18), ('physics', 0.18), ('wave', 0.18), ('reflection', 0.17), ('parker', 0.17), ('strike', 0.17), ('hottest', 0.17), ('burst', 0.16), ('chance', 0.16), ('burn', 0.14), ('rubbing', 0.14), ('interference', 0.14), ('bailey', 0.13), ('vibration', 0.12), ('gilbert', 0.12), ('produced', 0.12), ('rock', 0.12), ('warmer', 0.11), ('get', 0.11), ('drink', 0.11), ('fireplace', 0.11), ('ruin', 0.1), ('brittle', 0.1), ('fragment', 0.1), ('stumble', 0.09), ('formation', 0.09), ('shatter', 0.08), ('great', 0.08), ('friction', 0.08), ('flash', 0.07), ('cracks', 0.07), ('levels', 0.07), ('smash', 0.04), ('fail', 0.04), ('fra', 0.04), ('##glass', 0.03), ('variables', 0.03), ('because', 0.02), ('knock', 0.02), ('sun', 0.02), ('crush', 0.01), ('##e', 0.01), ('anger', 0.01)]
naver/splade-v2-distil (~48% more tokens + FLOPS = 3.82)
number of actual dimensions: 234
SPLADE BOW rep:
[('glass', 2.55), ('stress', 2.39), ('thermal', 2.38), ('glasses', 1.95), ('stressed', 1.87), ('crack', 1.84), ('cool', 1.78), ('heat', 1.62), ('pan', 1.6), ('break', 1.53), ('adjacent', 1.44), ('hotter', 1.43), ('strain', 1.21), ('area', 1.16), ('adjoining', 1.14), ('heated', 1.11), ('window', 1.07), ('stresses', 1.04), ('hot', 1.03), ('created', 1.03), ('create', 1.03), ('cause', 1.02), ('factors', 1.02), ('cooler', 1.01), ('broken', 1.0), ('too', 0.99), ('fracture', 0.96), ('collapse', 0.96), ('cracking', 0.95), ('great', 0.93), ('happen', 0.93), ('windows', 0.89), ('broke', 0.87), ('##e', 0.87), ('pressure', 0.84), ('hottest', 0.84), ('breaking', 0.83), ('govern', 0.79), ('shatter', 0.76), ('level', 0.75), ('heating', 0.69), ('temperature', 0.69), ('cracked', 0.69), ('panel', 0.68), ('##glass', 0.68), ('ceramic', 0.67), ('sash', 0.66), ('warm', 0.66), ('areas', 0.64), ('creating', 0.63), ('will', 0.62), ('tension', 0.61), ('cracks', 0.61), ('optical', 0.6), ('mechanism', 0.58), ('kelly', 0.58), ('determined', 0.58), ('generate', 0.58), ('causes', 0.56), ('if', 0.56), ('factor', 0.56), ('the', 0.56), ('chemical', 0.55), ('governed', 0.55), ('crystal', 0.55), ('strike', 0.55), ('microsoft', 0.54), ('creates', 0.53), ('than', 0.53), ('relation', 0.53), ('glazed', 0.52), ('compression', 0.51), ('painting', 0.51), ('governing', 0.5), ('harden', 0.49), ('solar', 0.48), ('reflection', 0.48), ('ic', 0.46), ('split', 0.45), ('mirror', 0.44), ('damage', 0.43), ('ring', 0.42), ('formation', 0.42), ('wall', 0.41), ('burst', 0.4), ('radiant', 0.4), ('determine', 0.4), ('one', 0.4), ('plastic', 0.39), ('furnace', 0.39), ('difference', 0.39), ('melt', 0.39), ('get', 0.39), ('contract', 0.38), ('forces', 0.38), ('gets', 0.38), ('produce', 0.38), ('surrounding', 0.37), ('vibration', 0.37), ('tile', 0.37), ('fail', 0.36), ('warmer', 0.36), ('rock', 0.35), ('fault', 0.35), ('roof', 0.34), ('burned', 0.34), ('physics', 0.33), ('welding', 0.33), ('why', 0.33), ('a', 0.32), ('pop', 0.32), ('and', 0.31), ('fra', 0.3), ('stat', 0.3), ('withstand', 0.3), ('sunglasses', 0.3), ('material', 0.29), ('ice', 0.29), ('generated', 0.29), ('matter', 0.29), ('frame', 0.28), ('elements', 0.28), ('then', 0.28), ('.', 0.28), ('pont', 0.28), ('blow', 0.28), ('snap', 0.27), ('metal', 0.26), ('effect', 0.26), ('reaction', 0.26), ('related', 0.25), ('aluminium', 0.25), ('neighboring', 0.25), ('weight', 0.25), ('steel', 0.25), ('bulb', 0.25), ('tear', 0.25), ('coating', 0.25), ('plumbing', 0.25), ('co', 0.25), ('microwave', 0.24), ('formed', 0.24), ('pipe', 0.23), ('drink', 0.23), ('chemistry', 0.23), ('energy', 0.22), ('reflect', 0.22), ('dynamic', 0.22), ('leak', 0.22), ('is', 0.22), ('lens', 0.21), ('frost', 0.21), ('lenses', 0.21), ('produced', 0.21), ('induced', 0.2), ('arise', 0.2), ('plate', 0.2), ('equations', 0.19), ('affect', 0.19), ('tired', 0.19), ('mirrors', 0.18), ('thickness', 0.18), ('bending', 0.18), ('cabinet', 0.17), ('apart', 0.17), ('##thermal', 0.17), ('gas', 0.17), ('equation', 0.17), ('relationship', 0.17), ('composition', 0.17), ('engineering', 0.17), ('block', 0.16), ('breaks', 0.16), ('when', 0.16), ('definition', 0.16), ('collapsed', 0.16), ('generation', 0.16), (',', 0.16), ('philips', 0.16), ('later', 0.15), ('wood', 0.15), ('neighbouring', 0.15), ('structural', 0.14), ('regulate', 0.14), ('neighbors', 0.13), ('lighting', 0.13), ('happens', 0.13), ('more', 0.13), ('property', 0.13), ('cooling', 0.12), ('shattering', 0.12), ('melting', 0.12), ('how', 0.11), ('cloud', 0.11), ('barriers', 0.11), ('lam', 0.11), ('conditions', 0.11), ('rule', 0.1), ('insulation', 0.1), ('bathroom', 0.09), ('convection', 0.09), ('cavity', 0.09), ('source', 0.08), ('properties', 0.08), ('bend', 0.08), ('bottles', 0.08), ('ceramics', 0.07), ('temper', 0.07), ('tense', 0.07), ('keller', 0.07), ('breakdown', 0.07), ('concrete', 0.07), ('simon', 0.07), ('solids', 0.06), ('windshield', 0.05), ('eye', 0.05), ('sunlight', 0.05), ('brittle', 0.03), ('caused', 0.03), ('suns', 0.03), ('floor', 0.02), ('components', 0.02), ('photo', 0.02), ('change', 0.02), ('sun', 0.01), ('crystals', 0.01), ('problem', 0.01), ('##proof', 0.01), ('parameters', 0.01), ('gases', 0.0), ('prism', 0.0), ('doing', 0.0), ('lattice', 0.0), ('ground', 0.0)]
Our models are token sparse and yet effective. It translates to faster retrieval (User experience) and smaller index size ($). Mean retrieval time on the standard MS-MARCO small dev set and Scaled total FLOPS loss are the respective metrics are below. This is why Google's SparseEmbed is interesting as they also achieve SPLADE quality retrieval effectiveness with much lower FLOPs. Compared to ColBERT, SPLADE and SparseEmbed match query and document terms with a linear complexity as ColBERT’s late interaction i.e. all query-document term pairs takes a quadratic complexity. The Challenge with SparseEmbed is it uses a hyperparameter called Top-k to restrict number of tokens used to learn contextual dense representations. Say 64 and 256 tokens for query and passage encoding. But it is unclear how well these hyperparameters are transferable to other domains or languages (where the notion of tokens changes a lot like our mother tongue Tamil which is Agglutinative in nature).

Note: Why Anserini not PISA? Anserini is a production ready lucene based library. Common industry search deployments use Solr or elastic which are lucene based, hence the performance can be comparable. PISA latency is irrelevant for industry as it is a a research only system. The full anserini evaluation log will be updated soon with encoding, indexing and querying details are here.
Our model is different in few more aspects
bert-base-uncased.To enable a light weight inference solution without heavy No Torch dependency we will also release a library - SPLADERunner Ofcourse if it doesnt matter you could always use these models with Huggingface transformers library.
| VectorDB | Colab Link |
|---|---|
| Pinecone | |
| Qdrant | TBD |
pip install spladerunner
#One-time init
from spladerunner import Expander
# Default model is the document expander.
exapander = Expander()
#Sample Document expansion
sparse_rep = expander.expand(
["The Manhattan Project and its atomic bomb helped bring an end to World War II. Its legacy of peaceful uses of atomic energy continues to have an impact on history and science."])
NOTEBOOK user? Login first
!huggingface-cli login
Integrating in your code ? How to use HF tokens in code Make these changes
tokenizer = AutoTokenizer.from_pretrained('prithivida/Splade_PP_en_v1', token=<Your token>)
model = AutoModelForMaskedLM.from_pretrained('prithivida/Splade_PP_en_v1', token=<Your token>)
Full code
import torch
from transformers import AutoModelForMaskedLM, AutoTokenizer
device = "cuda:0" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained('prithivida/Splade_PP_en_v1')
reverse_voc = {v: k for k, v in tokenizer.vocab.items()}
model = AutoModelForMaskedLM.from_pretrained('prithivida/Splade_PP_en_v1')
model.to(device)
sentence = """The Manhattan Project and its atomic bomb helped bring an end to World War II. Its legacy of peaceful uses of atomic energy continues to have an impact on history and science."""
inputs = tokenizer(sentence, return_tensors='pt')
inputs = {key: val.to(device) for key, val in inputs.items()}
input_ids = inputs['input_ids']
attention_mask = inputs['attention_mask']
outputs = model(**inputs)
logits, attention_mask = outputs.logits, attention_mask
relu_log = torch.log(1 + torch.relu(logits))
weighted_log = relu_log * attention_mask.unsqueeze(-1)
max_val, _ = torch.max(weighted_log, dim=1)
vector = max_val.squeeze()
cols = vector.nonzero().squeeze().cpu().tolist()
print("number of actual dimensions: ", len(cols))
weights = vector[cols].cpu().tolist()
d = {k: v for k, v in zip(cols, weights)}
sorted_d = {k: v for k, v in sorted(d.items(), key=lambda item: item[1], reverse=True)}
bow_rep = []
for k, v in sorted_d.items():
bow_rep.append((reverse_voc[k], round(v,2)))
print("SPLADE BOW rep:\n", bow_rep)
T.B.D
All limitations and biases of the BERT model applies to finetuning effort.
Please cite if you use our models or libraries. Citation info below.
Damodaran, P. (2024). Splade_PP_en_v2: Independent Implementation of SPLADE++ Model (`a.k.a splade-cocondenser* and family`) for the Industry setting. (Version 2.0.0) [Computer software].