
Submitted by
 wchengad
wchengad
wchengadGet trending papers in your email inbox once a day!
Get trending papers in your email inbox!
Subscribe
wchengad
 Seongyun
Seongyun
 lovodkin93
lovodkin93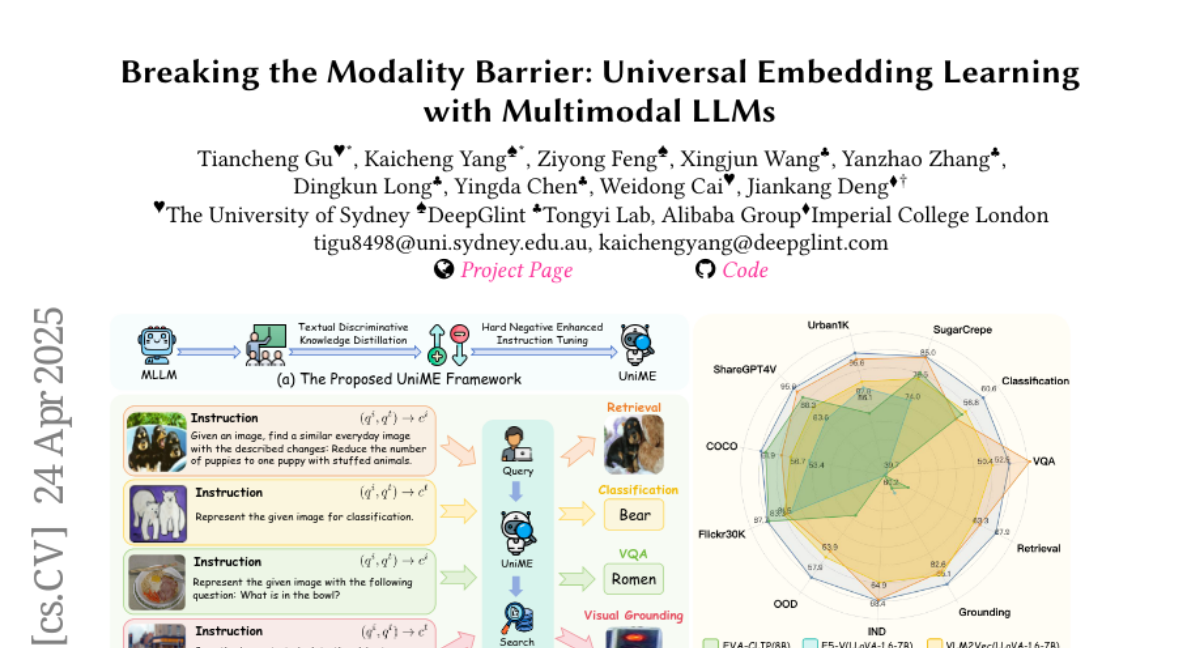
 Kaichengalex
Kaichengalex
 phillipinseoul
phillipinseoul
 LutaoJiang
LutaoJiang
 XiaohuanZhou
XiaohuanZhou
 akhaliq
akhaliq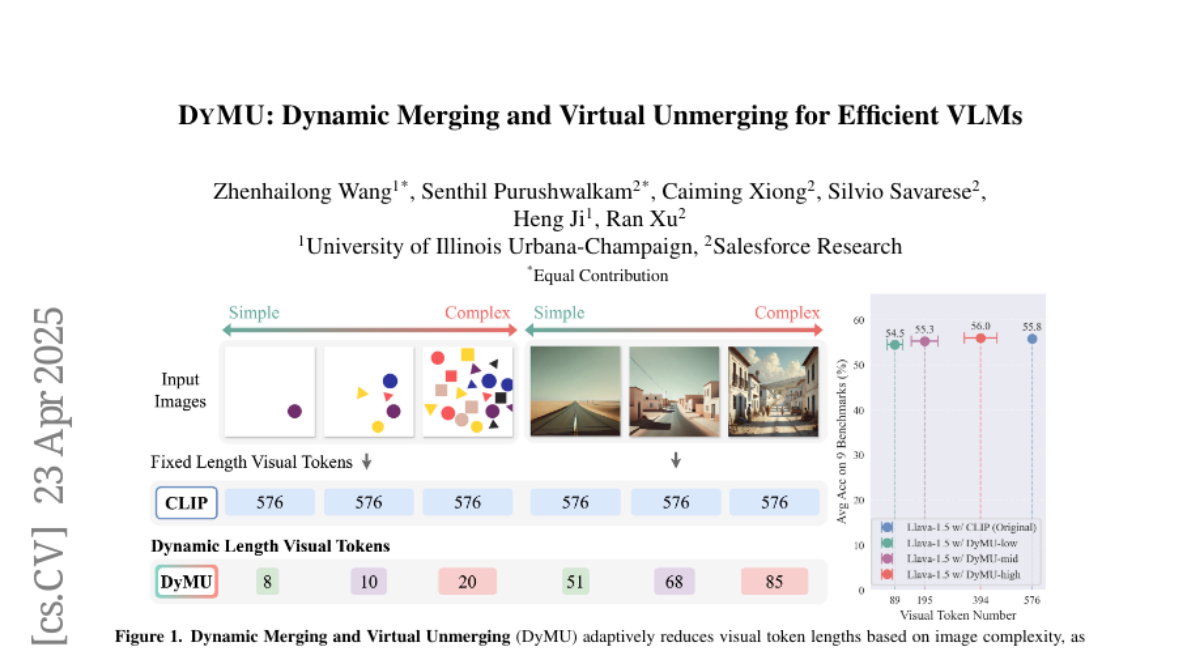 akhaliq
akhaliq
 mkhalifa
mkhalifa
 Sta8is
Sta8is akhaliq
akhaliq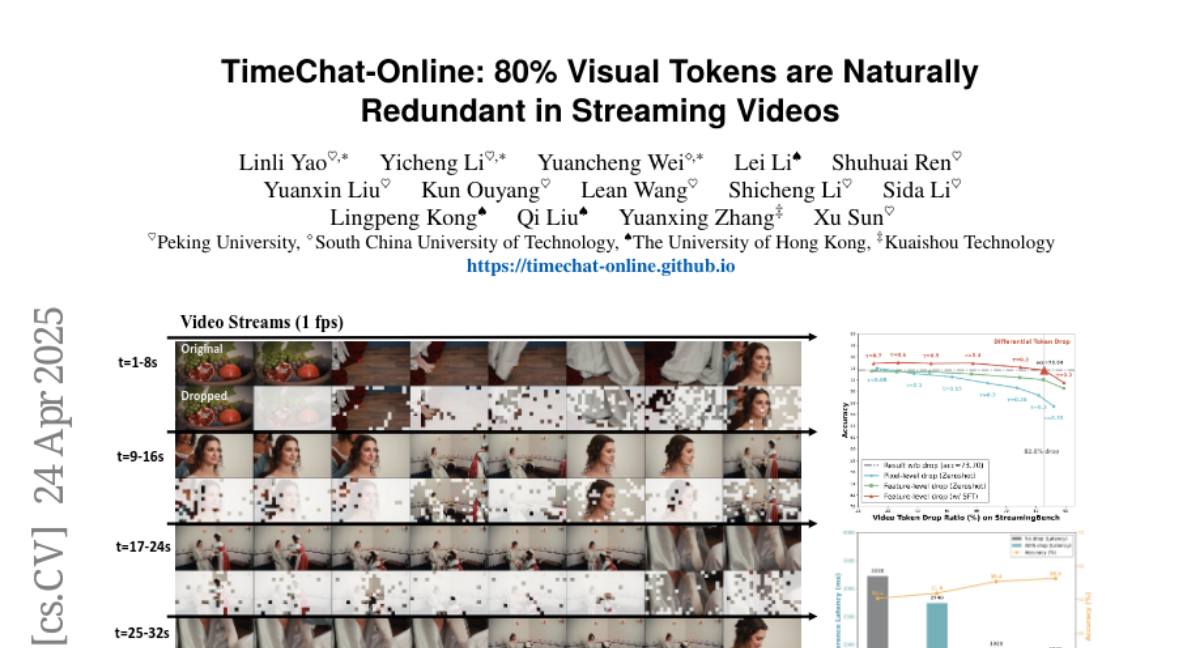
 yaolily
yaolily
 asarvazyan
asarvazyan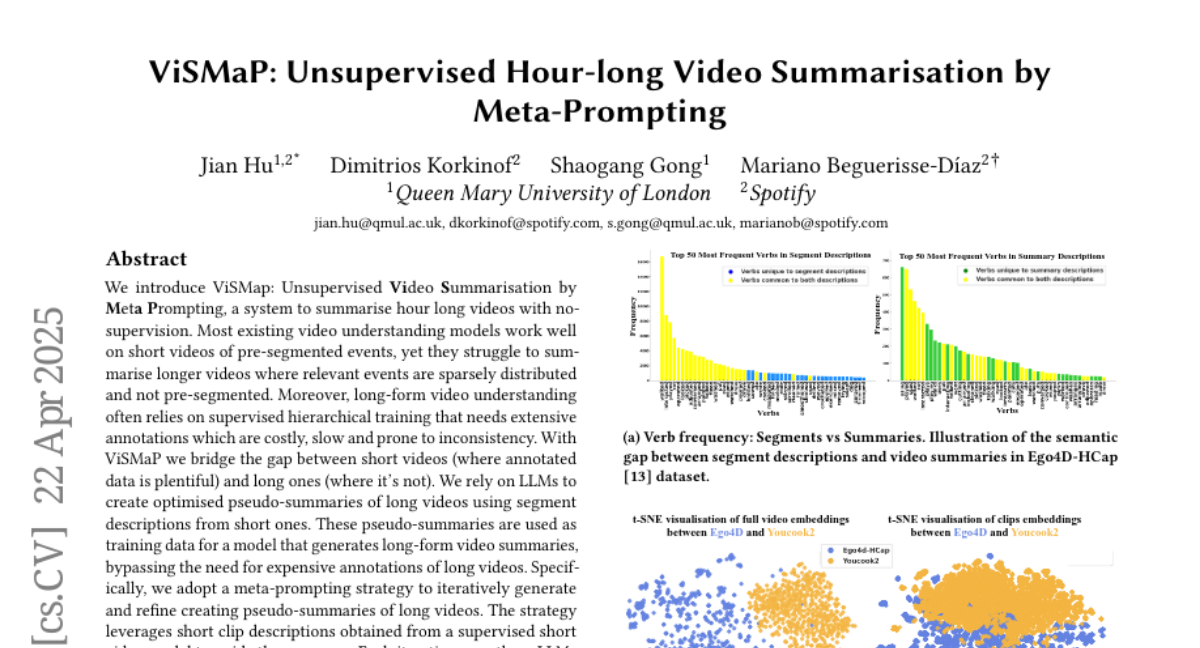
 lwpyh
lwpyh
 joanrodai
joanrodai
 crockwell
crockwell
 erikbergh
erikbergh










