

Submitted by
 guyuchao
guyuchao
guyuchaoGet trending papers in your email inbox once a day!
Get trending papers in your email inbox!
Subscribe
guyuchao
 HongchengGao
HongchengGao
 Row11n
Row11n
 phillipinseoul
phillipinseoul bfshi
bfshi
 zichenwen
zichenwen
 richardxp888
richardxp888
 akhaliq
akhaliq
 chuonghm
chuonghm akhaliq
akhaliq
 3587jjh
3587jjh akhaliq
akhaliq
 Ningyu
Ningyu
 pranamanam
pranamanam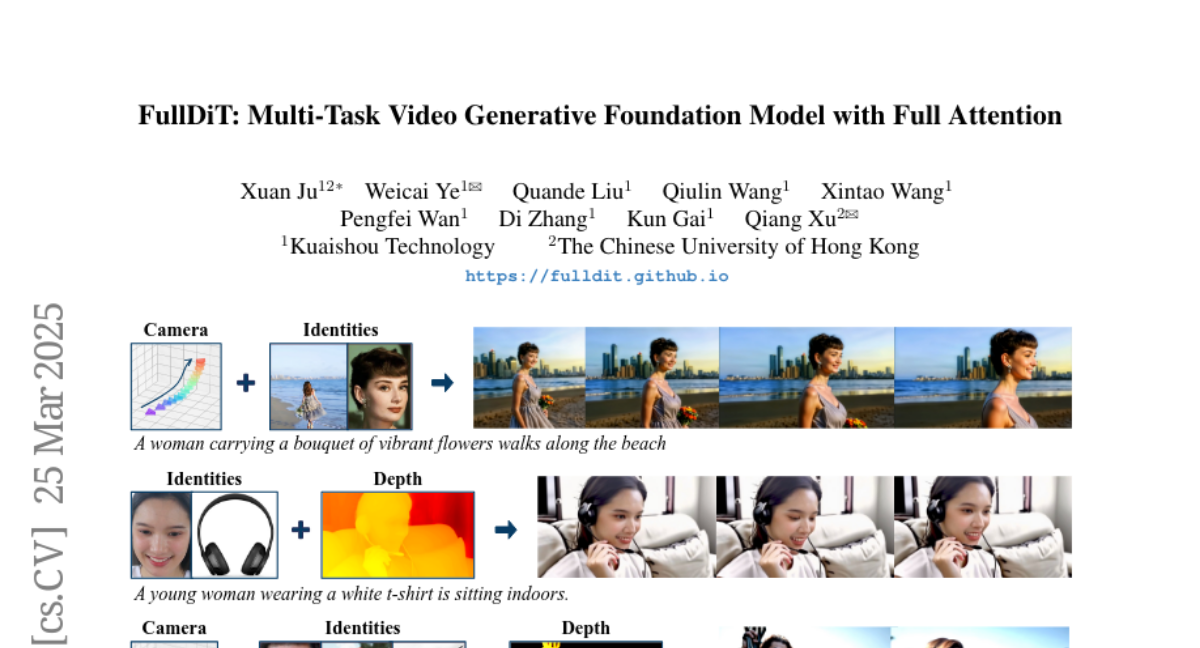
 BestWishYsh
BestWishYsh
 qth
qth
 shadowpa0327
shadowpa0327 haoyuhsu
haoyuhsu wish44165
wish44165
 zhehuderek
zhehuderek
 tuvu
tuvu
 DmitryRyumin
DmitryRyumin
 lx865712528
lx865712528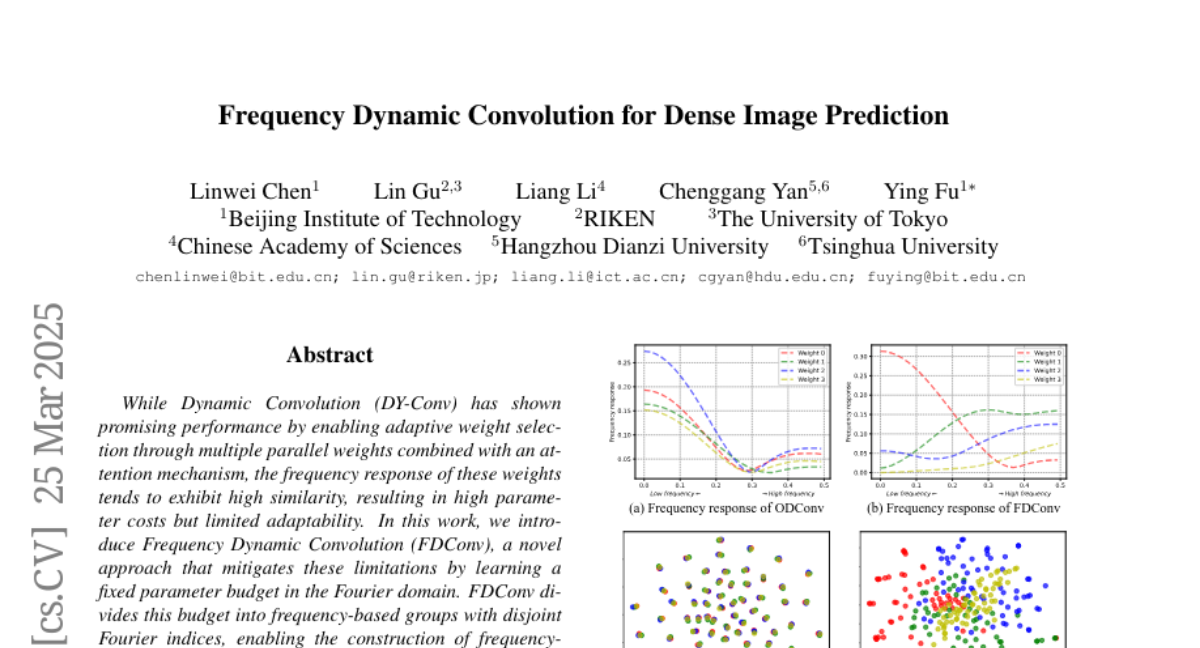
 CharlesChen2023
CharlesChen2023
 mwmathis
mwmathis
 wangyi111
wangyi111
 stojnvla
stojnvla
 rishitdagli
rishitdagli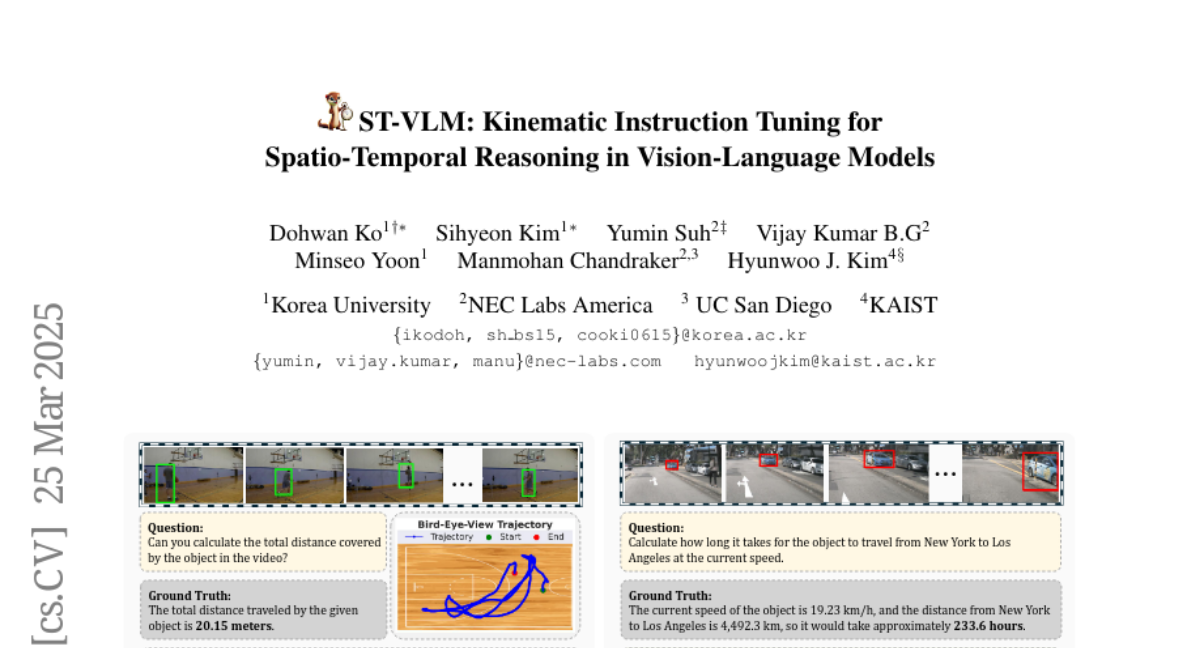
 ikodoh
ikodoh
 taeyeop
taeyeop akhaliq
akhaliq
 yaraalaa0
yaraalaa0
 LUC1O
LUC1O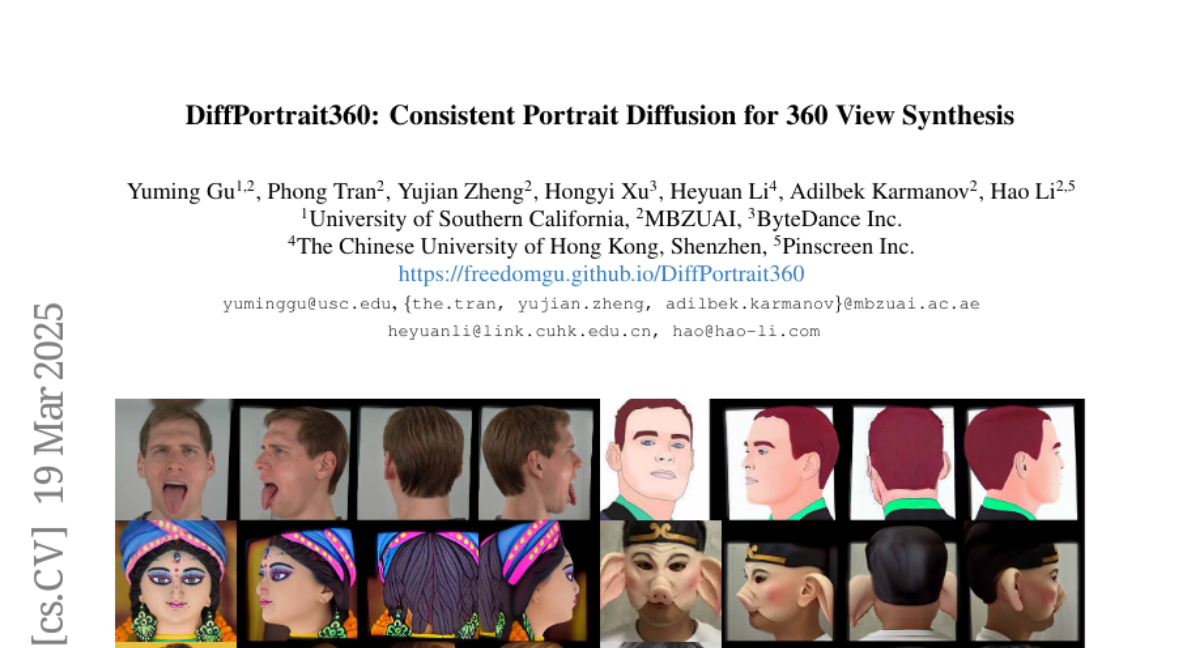
 gym890
gym890




