Q-Align: Teaching LMMs for Visual Scoring via Discrete Text-Defined Levels




Abstract
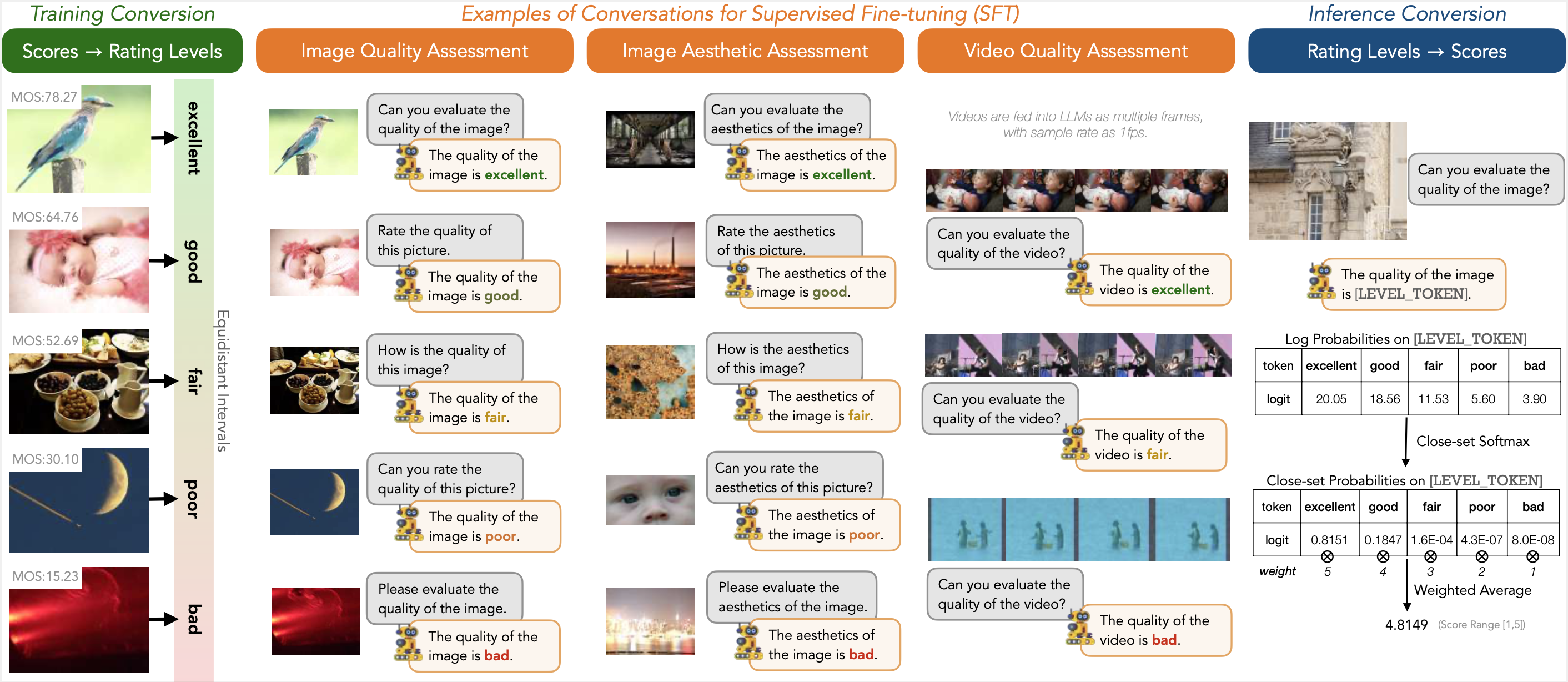
The explosion of visual content available online underscores the requirement for an accurate machine assessor to robustly evaluate scores across diverse types of visual contents. While recent studies have demonstrated the exceptional potentials of large multi-modality models (LMMs) on a wide range of related fields, in this work, we explore how to teach them for visual rating aligned with human opinions. Observing that human raters only learn and judge discrete text-defined levels in subjective studies, we propose to emulate this subjective process and teach LMMs with text-defined rating levels instead of scores. The proposed Q-Align achieves state-of-the-art performance on image quality assessment (IQA), image aesthetic assessment (IAA), as well as video quality assessment (VQA) tasks under the original LMM structure. With the syllabus, we further unify the three tasks into one model, termed the OneAlign. In our experiments, we demonstrate the advantage of the discrete-level-based syllabus over direct-score-based variants for LMMs. Our code and the pre-trained weights are released at https://github.com/Q-Future/Q-Align.
Community
🎆AutoModel available now! Try the following code to have a quick start!
import requests
import torch
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("q-future/one-align", trust_remote_code=True,
torch_dtype=torch.float16, device_map="auto")
from PIL import Image
url = "https://raw.githubusercontent.com/Q-Future/Q-Align/main/fig/singapore_flyer.jpg"
image = Image.open(requests.get(url,stream=True).raw)
model.score([image], task_="quality", input_="image")
# task_ : quality | aesthetics; # input_: image | video
Homepage: https://q-align.github.io
HF Space (NEW!): https://huggingface.co/spaces/teowu/OneScorer
Inference Latency on One RTX3090 24GB GPU:
| Batch Size | 1 | 2 | 4 | 8 | 16 | 32 | 64 (max available) |
|---|---|---|---|---|---|---|---|
| Latency (ms) | 101 | 154 | 239 | 414 | 757 | 1441 | 2790 |
| Throughput (image/sec) | 9.90 | 12.99 | 16.74 | 19.32 | 21.14 | 22.21 | 22.94 |
4-bit/8-bit Usage for OneAlign AutoModel
8-bit
model = AutoModelForCausalLM.from_pretrained("q-future/one-align",
load_in_8bit=True,
trust_remote_code=True,
torch_dtype=torch.float16,
device_map="auto")
4-bit
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type='nf4'
)
model = AutoModelForCausalLM.from_pretrained("q-future/one-align",
trust_remote_code=True,
load_in_4bit=True,
torch_dtype=torch.float16,
device_map="auto",
quantization_config=bnb_config)
Results of 4-bit/8-bit
TL, DR: They are with almost identical accuracy compared to original fp16 model.
| Precision | vRAM (bs=1) | AGIQA-3K | CSIQ | LIVE | LIVE-C | KADID | KonIQ | SPAQ |
|---|---|---|---|---|---|---|---|---|
| 4-bit (BnB) | 5396MB | 0.801/0.838 | 0.877/0.904 | 0.886/0.853 | 0.886/0.897 | 0.939/0.939 | 0.937/0.947 | 0.931/0.933 |
| 8-bit (BnB) | 8944MB | 0.801/0.836 | 0.877/0.902 | 0.886/0.855 | 0.882/0.894 | 0.941/0.941 | 0.936/0.947 | 0.931/0.934 |
| 16-bit (fp16) | 16204MB | 0.801/0.838 | 0.881/0.906 | 0.887/0.856 | 0.881/0.894 | 0.941/0.942 | 0.941/0.950 | 0.932/0.935 |
Models citing this paper 7
Browse 7 models citing this paperDatasets citing this paper 0
No dataset linking this paper
Spaces citing this paper 4
Collections including this paper 0
No Collection including this paper