
Donut (base-sized model, fine-tuned on visual novel like synthetic dataset )
ビジュアルノベル風画像の合成データセットでnaver-clova-ix/donut-baseを訓練したモデルです。
使い方
サンプルノートブックsample_predictions_colab.ipynbを参照してください。
oshizo/donut-base-japanese-visual-novel
認識結果のサンプル
{'options': '', 'names': '結月', 'messages': 'この神社には古い言い伝えがあるの。神樹の下で誓いを立てると、その願いは必ず叶うという。心を開いて、自分の想いを信じてみて。'}

{'options': ['行こう!', '今回は見送る', '準備を整えるまで待って(会話から抜けます)', '旅の目的について詳しく教えてください'], 'names': 'リリアン', 'messages': '私たちの使命は、新たな発見と交流を通じて地球と宇宙の未来を築くこと。この壮大な旅に参加する準備はできているかしら?'}

{'options': ['全力で攻撃する!勝利をつかめ!', '堅実に守り、敵の隙を待とう。'], 'names': '', 'messages': '敵を誘い込んで、戦術を駆使せよ。'}

{'options': 'もちろん、手伝います!', 'names': '下尾崎 菊欠郎', 'messages': 'この書斎は重要な手がかりが隠されているかもしれない。君も協力してくれるか?'}

仕様
- ルビを読み取りません。ルビが表示されていても影響されずに本文を読み取ることを目標にしています。
- SAVE, LOADなどのUI要素と、2日目、4/3などの日付表示をなるべく読み取らないことを目標にしています
- options, names, messsages の3つのキーを持つjsonを出力します
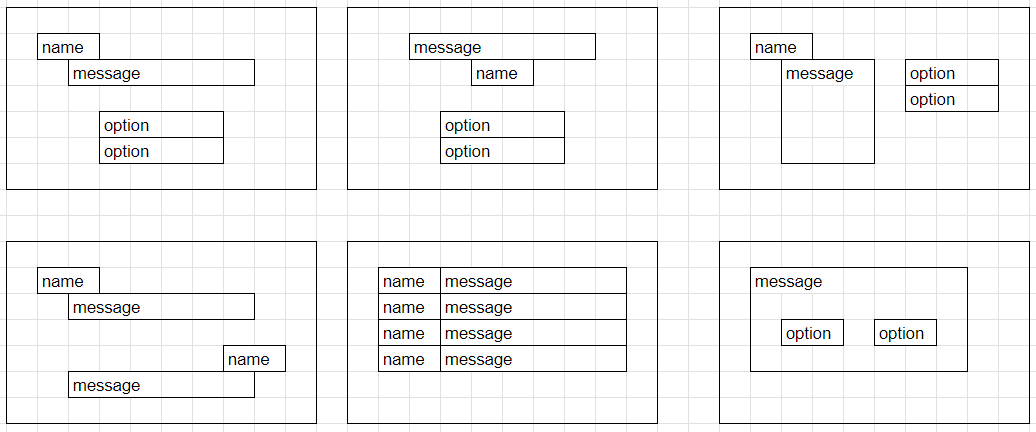
学習に含むレイアウト
以下のレイアウトと、それぞれのパターンが存在しないパターンが学習データに含まれます。

学習に含まないレイアウト
以下のようなパターンなど、学習データに含まれないパターンはうまく読み取れません。
その他の制約
- 幅1,920px, 高さ1,080pxの画像でのみ訓練、評価しているため、縦横比が大きく異なる場合認識精度が落ちる可能性があります
- decoderのtokenizerには
XLMRobertaTokenizerをベースに日本語の漢字を1500種類程度追加したものを使用しています。tokenizerに存在せず出力されない漢字が存在します
学習方法
もう少し詳しい情報を以下のnote記事に記載しました。
- Downloads last month
- 227
Inference Providers
NEW
This model is not currently available via any of the supported Inference Providers.