
Model card for NOS Dutch Youth Comment Classifier
A classifier that decides whether Dutch comments are appropriate for children 8-12 years old with 83,5% accuracy. This model was originally trained for jeugdjournaal.nl, a news platform for kids aged 8-12. On the platform users can comment on polls, but comments will only be shown after manual approval by one of the editors. This model was trained on a data set constructed by tracking moderation decisions by editors. We also evaluated a Rule-Based System and trained a gibberish detector, which together with this model can be seen in action in the following huggingface-space. For more detail see our blogpost.
Intended uses
This model indicates if a comment or other text is appropriate for children aged 8-12. We find this model useful, but by no means 100% accurate at this time. We advise to implement additional measures on top of this model in order shape a safe online environment for children. We are not liable for damages as a result of applying this technology.
Bias, Risks and Limitations
This model was trained specifically for youth and may be overly strict when used to moderate grown-up comments. At NOS the model is used to assist our moderators, but the final call is always up to a person.
One should be aware of bias: some words are used many times in inappropriate ways, but may also be used in comments that are appropriate, which may cause the model to label such a comment as inappropriate. For example, our data set shows the word "gay" sadly is used often in offensive ways, which causes the model to flag all comments using the word "gay" as inappropriate.
Users can place comments using a pseudonym of their choosing, of which many are inappropriate. We choose not to use this data in our training set as this may introduce strong biases towards particular names, which would be unfair to users with similar/identical names.
How to Get Started with the Model
Use the code below to get started with the model.
# load the model
from huggingface_hub import from_pretrained_fastai
learner = from_pretrained_fastai("nosdigitalmedia/dutch-youth-comment-classifier")
# make some predictions
comments = ['Ik zag gisteren een puppy', 'Jij bent lelijk']
for comment in comments:
verdict = learner.predict(comment)
print(verdict) # 1 is ok, 0 is inappriopriate
How to use the Huggingface-Space
We made a Huggingface Space available here where this model is used in conjunction with two rule based systems and a gibberish detection model to judge whether comments might be appropriate for youth.
We decided to use two different rule based systems (RBS), so that one could focus on finding all comments that are certainly inappropriate (the strong RBS), which can be achieved reletively easily using regular expressions.
The second RBS (weak RBS) was build to flag comments that might be inappropriate, but should be checked by a human.
The interface allows a user to input text and returns verdicts by the 4 different systems in json format as shown below.
The keys refer the to various systems, where model refers to the model described on this page. gibberish refers to a Markov-Chain model trained to detect whether text is not a random sequence of characters.
weak_rbs and strong_rbs refer to the two rule based systems.
For each system it is shown whether the comment is allowed and if the comment is not allowed highlights will show the tokens the system triggered on and reasons will describe the reasons why the comment is not allowed.
{
"model": {
"allowed": true,
"verdict": "Allowed",
"highlights": [],
"reasons": []
},
"gibberish": {
"allowed": true,
"verdict": "Allowed",
"highlights": [],
"reasons": []
},
"weak_rbs": {
"allowed": true,
"verdict": "Allowed",
"highlights": [],
"reasons": []
},
"strong_rbs": {
"allowed": true,
"verdict": "Allowed",
"highlights": [],
"reasons": []
}
}
Experimental setup
Data set
The data set consists out of 59.469 removed comments and 4 million approved comments. Using random sampling 59.469 approved comments have been selected. Train, validate and test splits have been created with fraction 0.6, 0.2, 0.2 respectively. A comment in our data set consists of the comment text and a label, where the label indicates whether the editorial team approved or removed the comment. Unfortunately, we cannot publicly share this data set.
This data set is quite an interesting data set, because the way the comments are written deviates from regular texts, which is illustrated in Fig. 1. In this figure the 30 most frequent words not in the standard Dutch vocabulary (i.e. words that are not entries of the Dutch dictionary) are shown on the x-axis and the frequency of these words within the 4 million comments data set is shown on the y-axis. One point of interest are the 6000 occurrences of 'mischien' and 4000 occurrences of 'meschien', which would be correctly spelled as 'misschien'. Next to that, abbreviations such as 'gwn' which in full form would be written as 'gewoon' are abundant in the data. Other interesting cases are the words 'jaa' and 'jaaaa', which ordinarily would be written as 'ja'. These typos, spelling errors, typical child-like ways of writing, abbreviations and elongations of words complicates the task of classification, because the performance of a machine learning model will depend on the frequency of the words it encounters in the data set. If many words are infrequent, the accuracy will be lower, because the model cannot learn good word representations. The example abbreviations/elongations and typos in Fig. 1 occur frequently so these might not cause too much trouble, but one can expect many other and even more unusual examples to occur in the data with low frequencies. Another complication caused by alternative spelling arises when using pre-trained word embeddings, which are often used in ML tasks to initialize word representations. Embeddings are trained on very large text corpora, which most-likely will not contain the alternatively spelled words, and so no pre-trained embedding will be available for such words.
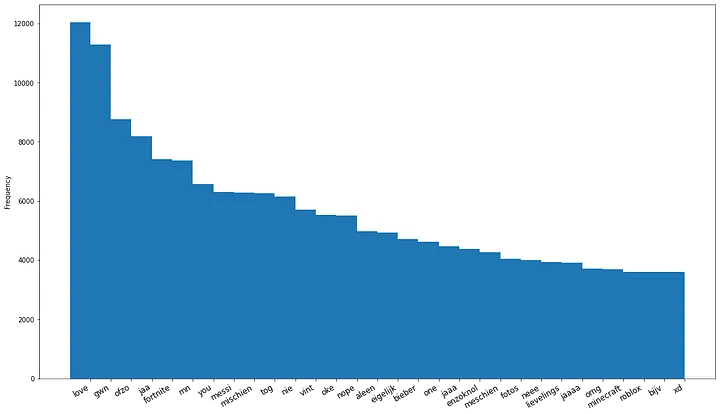 Apart from alternative spellings, completely random combinations of characters are abundant in the data set. These gibberish comments add noise to our data, complicating and slowing down training of the ML models.
Apart from alternative spellings, completely random combinations of characters are abundant in the data set. These gibberish comments add noise to our data, complicating and slowing down training of the ML models.
Models and evaluation
We experimented with a Naive Bayes, LSTM and AWD-LSTM model. The models were compared by calculating accuracy on the test set, where the AWD-LSTM model performed best with an accuracy of 83.5%.
Details
- Shared by Dutch Public Broadcasting Foundation (NOS)
- Model type: text-classification
- Language: Dutch
- License: Creative Commons Attribution Non Commercial No Derivatives 4.0
- Finetuned from model: AWD-LSTM