
File size: 2,784 Bytes
f4ae91f fc4978b f4ae91f fc4978b 4108d4f fc4978b aced173 fc4978b 80698de fc4978b 80698de fc4978b |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 |
---
language:
- en
library_name: peft
pipeline_tag: text-generation
tags:
- medical
license: llama2
---
# i2b2 QueryBuilder - 34b
<!-- TODO: Add a link here N: DONE-->
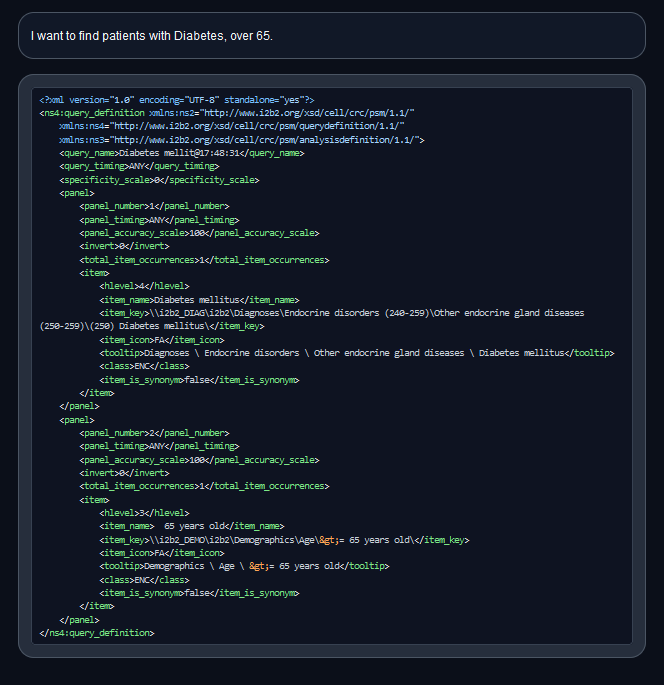
## Model Description
This model will generate queries for your i2b2 query builder trained on [this dataset](https://huggingface.co/datasets/nmitchko/i2b2-query-data-1.0) for `10 epochs` . For evaluation use.
* Do not use as a final research query builder.
* Results may be incorrect or mal-formatted.
* The onus of research accuracy is on the researcher, not the AI model.
## Prompt Format
If you are using text-generation-webui, you can download the instruction template [i2b2.yaml](https://huggingface.co/nmitchko/i2b2-querybuilder-codellama-34b/resolve/main/i2b2.yaml)
```md
Below is an instruction that describes a task.
### Instruction:
{input}
### Response:
```xml
```
### Architecture
`nmitchko/i2b2-querybuilder-codellama-34b` is a large language model LoRa specifically fine-tuned for generating queries in the [i2b2 query builder](https://community.i2b2.org/wiki/display/webclient/3.+Query+Tool).
It is based on [`codellama-34b-hf`](https://huggingface.co/codellama/CodeLlama-34b-hf) at 34 billion parameters.
The primary goal of this model is to improve research accuracy with the i2b2 tool.
It was trained using [LoRA](https://arxiv.org/abs/2106.09685), specifically [QLora Multi GPU](https://github.com/ChrisHayduk/qlora-multi-gpu), to reduce memory footprint.
See Training Parameters for more info This Lora supports 4-bit and 8-bit modes.
### Requirements
```
bitsandbytes>=0.41.0
peft@main
transformers@main
```
Steps to load this model:
1. Load base model (codellama-34b-hf) using transformers
2. Apply LoRA using peft
```python
# Sample Code Coming
```
## Training Parameters
The model was trained for or 10 epochs on [i2b2-query-data-1.0](https://huggingface.co/datasets/nmitchko/i2b2-query-data-1.0)
`i2b2-query-data-1.0` contains only tasks and outputs for i2b2 queries xsd schemas.
| Item | Amount | Units |
|---------------|--------|-------|
| LoRA Rank | 64 | ~ |
| LoRA Alpha | 16 | ~ |
| Learning Rate | 1e-4 | SI |
| Dropout | 5 | % |
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: QuantizationMethod.BITS_AND_BYTES
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
|