YAML Metadata
Warning:
The pipeline tag "text2text-generation" is not in the official list: text-classification, token-classification, table-question-answering, question-answering, zero-shot-classification, translation, summarization, feature-extraction, text-generation, fill-mask, sentence-similarity, text-to-speech, text-to-audio, automatic-speech-recognition, audio-to-audio, audio-classification, audio-text-to-text, voice-activity-detection, depth-estimation, image-classification, object-detection, image-segmentation, text-to-image, image-to-text, image-to-image, image-to-video, unconditional-image-generation, video-classification, reinforcement-learning, robotics, tabular-classification, tabular-regression, tabular-to-text, table-to-text, multiple-choice, text-ranking, text-retrieval, time-series-forecasting, text-to-video, image-text-to-text, visual-question-answering, document-question-answering, zero-shot-image-classification, graph-ml, mask-generation, zero-shot-object-detection, text-to-3d, image-to-3d, image-feature-extraction, video-text-to-text, keypoint-detection, visual-document-retrieval, any-to-any, video-to-video, other
ENKO-T5-SMALL-V0
This model is for English to Korean Machine Translator, which is based on T5-small architecture, but trained from scratch.
Code
The training code is from my lecture(LLM을 위한 김기현의 NLP EXPRESS), which is published on FastCampus. You can check the training code in this github repo.
Dataset
The training dataset for this model is mainly from AI-Hub. The dataset consists of 11M parallel samples.
Tokenizer
I use Byte-level BPE tokenizer for both source and target language. Since it covers both languages, tokenizer vocab size is 60k.
Architecture
The model architecture is based on T5-small, which is popular encoder-decoder model architecture. Please, note that this model is trained from-scratch, not fine-tuned.
Evaluation
I conducted the evaluation with 5 different test sets. Following figure shows BLEU scores on each test set.
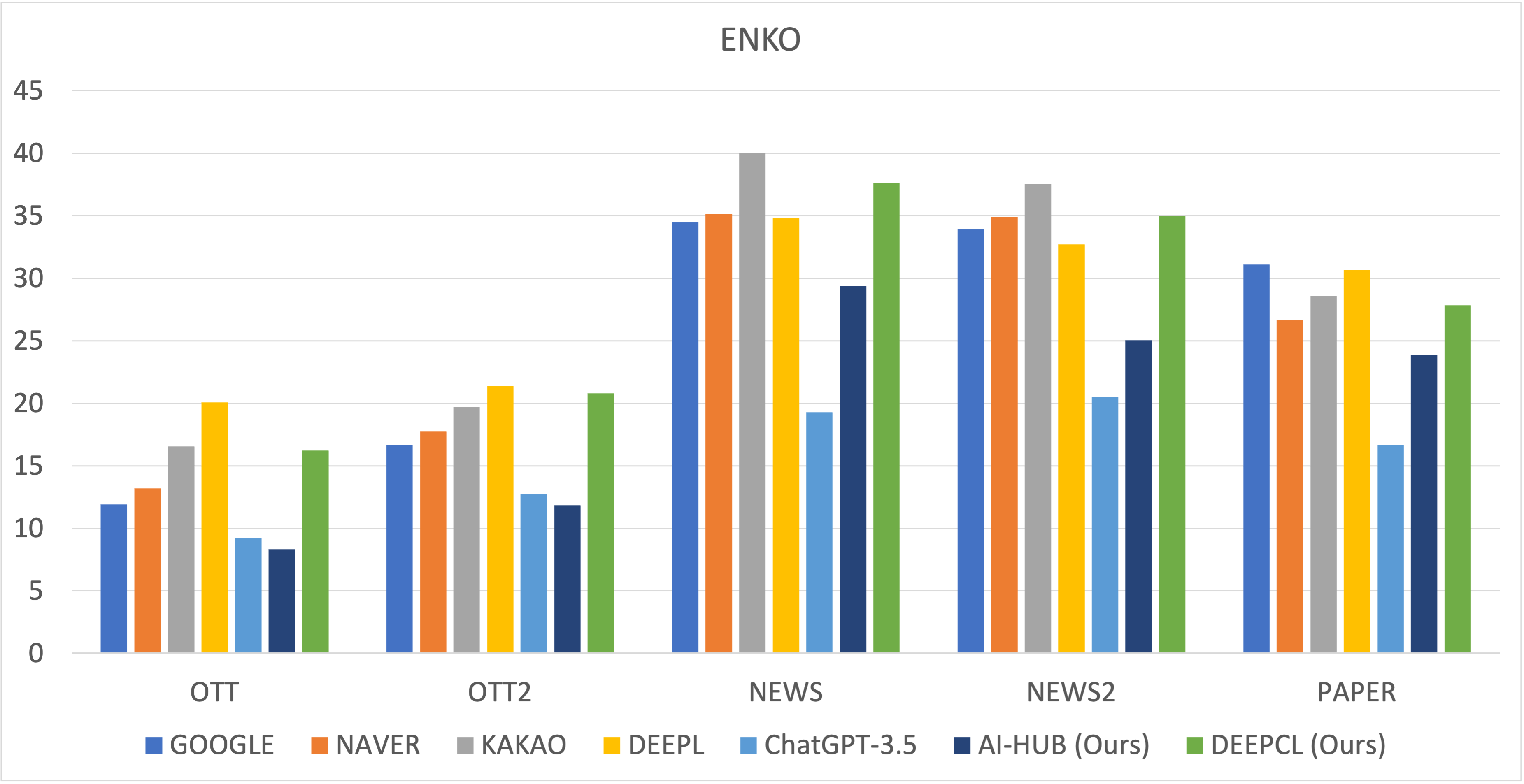
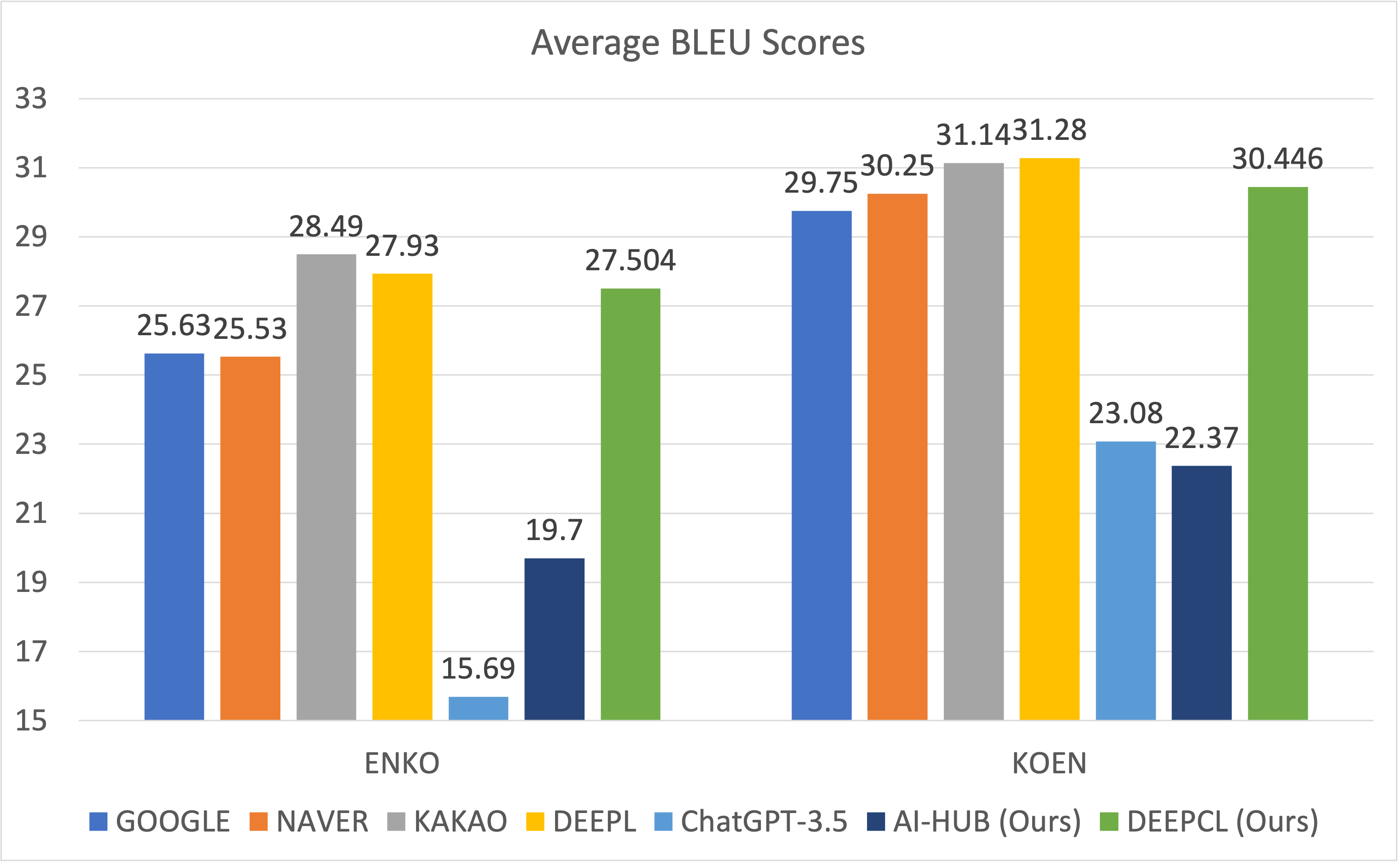
DEEPCL model is private version of this model, which is trained on much more data.
Contact
Kim Ki Hyun (nlp.with.deep.learning@gmail.com)


