
bge-base-en-v1.5-quant
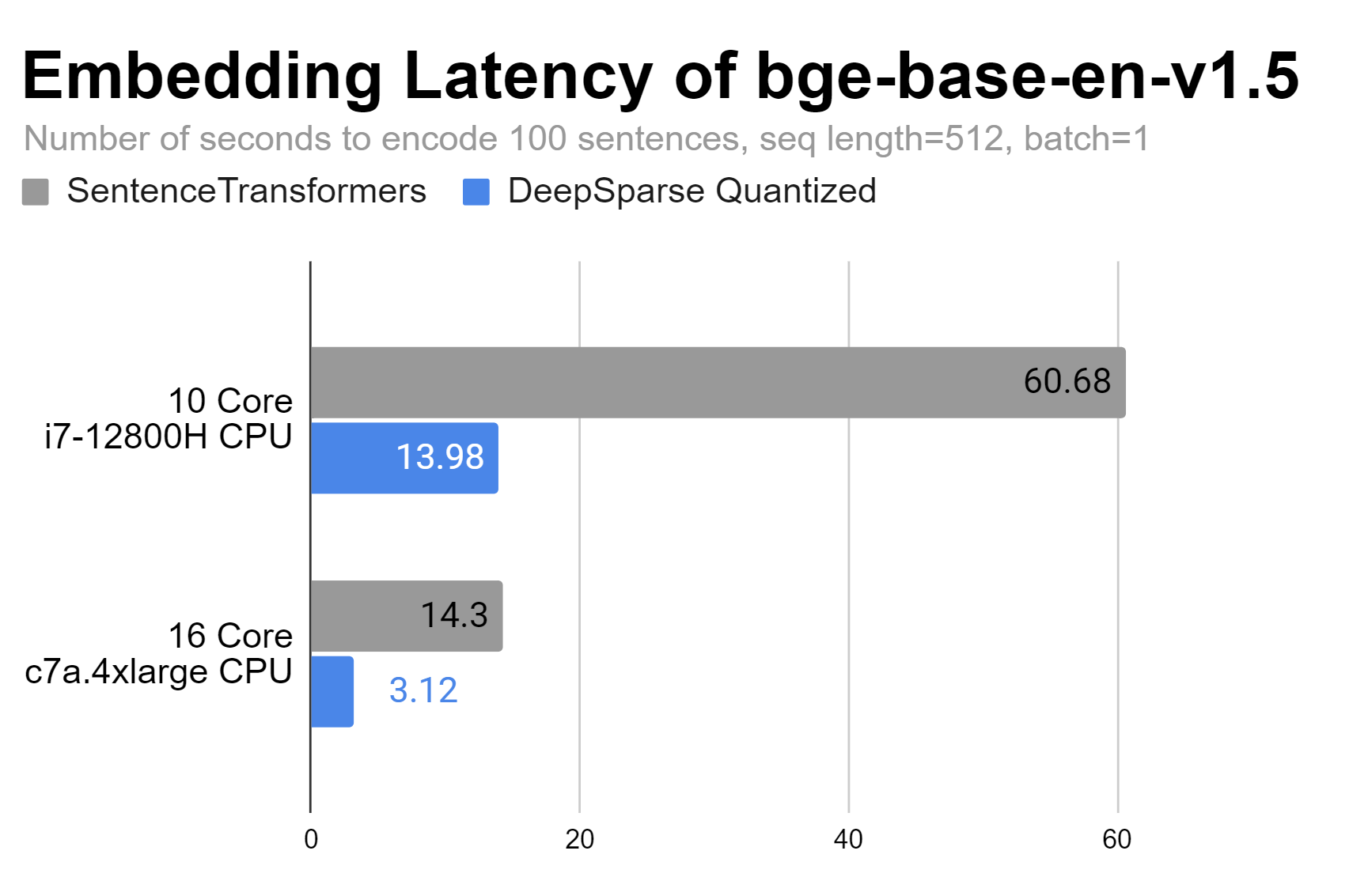
DeepSparse is able to improve latency performance on a 10 core laptop and a 16 core AWS instance by up to 4.5X.
Usage
This is the quantized (INT8) ONNX variant of the bge-base-en-v1.5 embeddings model accelerated with Sparsify for quantization and DeepSparseSentenceTransformers for inference.
pip install -U deepsparse-nightly[sentence_transformers]
from deepsparse.sentence_transformers import DeepSparseSentenceTransformer
model = DeepSparseSentenceTransformer('neuralmagic/bge-base-en-v1.5-quant', export=False)
# Our sentences we like to encode
sentences = ['This framework generates embeddings for each input sentence',
'Sentences are passed as a list of string.',
'The quick brown fox jumps over the lazy dog.']
# Sentences are encoded by calling model.encode()
embeddings = model.encode(sentences)
# Print the embeddings
for sentence, embedding in zip(sentences, embeddings):
print("Sentence:", sentence)
print("Embedding:", embedding.shape)
print("")
For general questions on these models and sparsification methods, reach out to the engineering team on our community Slack.
- Downloads last month
- 54
Spaces using RedHatAI/bge-base-en-v1.5-quant 12
Evaluation results
- accuracy on MTEB AmazonCounterfactualClassification (en)test set self-reported76.164
- ap on MTEB AmazonCounterfactualClassification (en)test set self-reported39.630
- f1 on MTEB AmazonCounterfactualClassification (en)test set self-reported70.300
- accuracy on MTEB AmazonPolarityClassificationtest set self-reported92.951
- ap on MTEB AmazonPolarityClassificationtest set self-reported89.925
- f1 on MTEB AmazonPolarityClassificationtest set self-reported92.942
- accuracy on MTEB AmazonReviewsClassification (en)test set self-reported48.214
- f1 on MTEB AmazonReviewsClassification (en)test set self-reported47.571
- v_measure on MTEB ArxivClusteringP2Ptest set self-reported48.500
- v_measure on MTEB ArxivClusteringS2Stest set self-reported42.007