
BERT (base-multilingual-uncased) fine-tuned for multilingual Q&A
This model was created by Google and fine-tuned on XQuAD like data for multilingual (11 different languages) Q&A downstream task.
Details of the language model('bert-base-multilingual-uncased')
| Languages | Heads | Layers | Hidden | Params |
|---|---|---|---|---|
| 102 | 12 | 12 | 768 | 100 M |
Details of the downstream task (multilingual Q&A) - Dataset
Deepmind XQuAD
Languages covered:
- Arabic:
ar - German:
de - Greek:
el - English:
en - Spanish:
es - Hindi:
hi - Russian:
ru - Thai:
th - Turkish:
tr - Vietnamese:
vi - Chinese:
zh
As the dataset is based on SQuAD v1.1, there are no unanswerable questions in the data. We chose this setting so that models can focus on cross-lingual transfer.
We show the average number of tokens per paragraph, question, and answer for each language in the table below. The statistics were obtained using Jieba for Chinese and the Moses tokenizer for the other languages.
| en | es | de | el | ru | tr | ar | vi | th | zh | hi | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Paragraph | 142.4 | 160.7 | 139.5 | 149.6 | 133.9 | 126.5 | 128.2 | 191.2 | 158.7 | 147.6 | 232.4 |
| Question | 11.5 | 13.4 | 11.0 | 11.7 | 10.0 | 9.8 | 10.7 | 14.8 | 11.5 | 10.5 | 18.7 |
| Answer | 3.1 | 3.6 | 3.0 | 3.3 | 3.1 | 3.1 | 3.1 | 4.5 | 4.1 | 3.5 | 5.6 |
Citation:
@article{Artetxe:etal:2019,
author = {Mikel Artetxe and Sebastian Ruder and Dani Yogatama},
title = {On the cross-lingual transferability of monolingual representations},
journal = {CoRR},
volume = {abs/1910.11856},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.11856}
}
As XQuAD is just an evaluation dataset, I used Data augmentation techniques (scraping, neural machine translation, etc) to obtain more samples and split the dataset in order to have a train and test set. The test set was created in a way that contains the same number of samples for each language. Finally, I got:
| Dataset | # samples |
|---|---|
| XQUAD train | 50 K |
| XQUAD test | 8 K |
Model training
The model was trained on a Tesla P100 GPU and 25GB of RAM. The script for fine tuning can be found here
Model in action
Fast usage with pipelines:
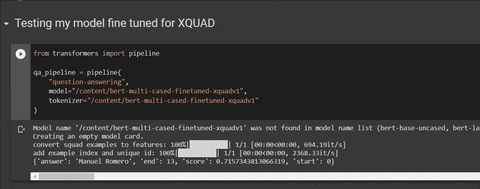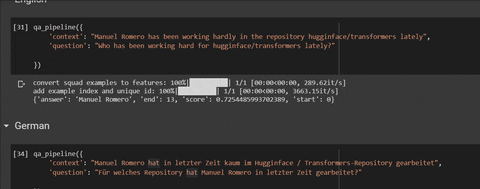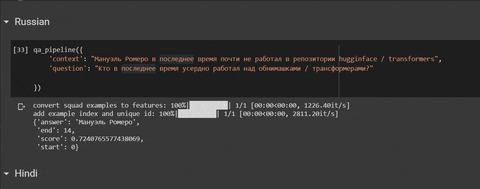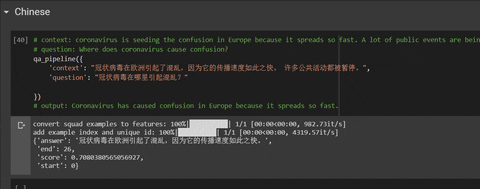
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="mrm8488/bert-multi-uncased-finetuned-xquadv1",
tokenizer="mrm8488/bert-multi-uncased-finetuned-xquadv1"
)
# context: Coronavirus is seeding panic in the West because it expands so fast.
# question: Where is seeding panic Coronavirus?
qa_pipeline({
'context': "कोरोनावायरस पश्चिम में आतंक बो रहा है क्योंकि यह इतनी तेजी से फैलता है।",
'question': "कोरोनावायरस घबराहट कहां है?"
})
# output: {'answer': 'पश्चिम', 'end': 18, 'score': 0.7037217439689059, 'start': 12}
qa_pipeline({
'context': "Manuel Romero has been working hardly in the repository hugginface/transformers lately",
'question': "Who has been working hard for hugginface/transformers lately?"
})
# output: {'answer': 'Manuel Romero', 'end': 13, 'score': 0.7254485993702389, 'start': 0}
qa_pipeline({
'context': "Manuel Romero a travaillé à peine dans le référentiel hugginface / transformers ces derniers temps",
'question': "Pour quel référentiel a travaillé Manuel Romero récemment?"
})
#output: {'answer': 'hugginface / transformers', 'end': 79, 'score': 0.6482061613915384, 'start': 54}
Try it on a Colab:
Created by Manuel Romero/@mrm8488
Made with ♥ in Spain
- Downloads last month
- 8