
DC-AE-Diffusion
Collection
Efficient Diffusion Models with Deep Compression Autoencoder
•
10 items
•
Updated
•
6

Figure 1: We address the reconstruction accuracy drop of high spatial-compression autoencoders.

Figure 2: DC-AE delivers significant training and inference speedup without performance drop.

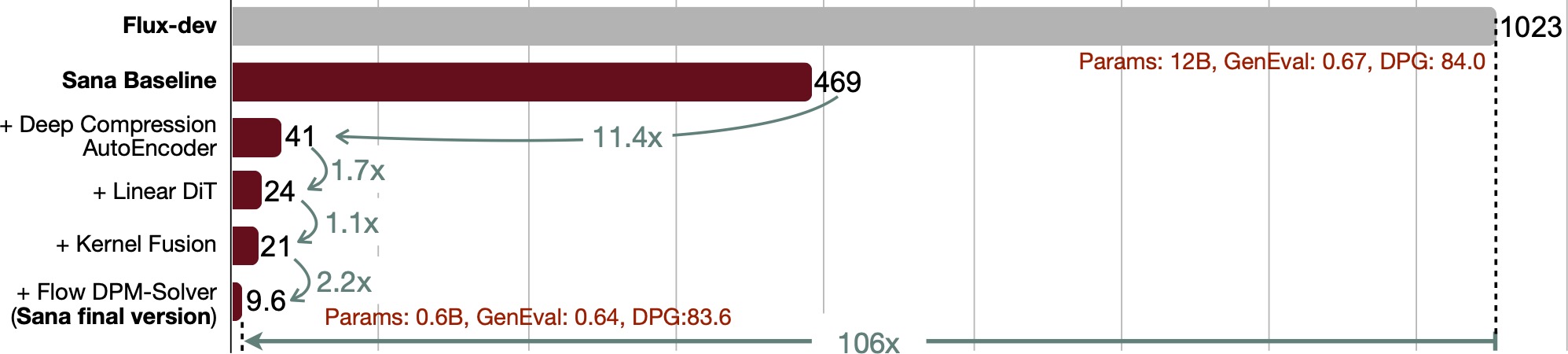
Figure 3: DC-AE enables efficient text-to-image generation on the laptop.
We present Deep Compression Autoencoder (DC-AE), a new family of autoencoder models for accelerating high-resolution diffusion models. Existing autoencoder models have demonstrated impressive results at a moderate spatial compression ratio (e.g., 8x), but fail to maintain satisfactory reconstruction accuracy for high spatial compression ratios (e.g., 64x). We address this challenge by introducing two key techniques: (1) Residual Autoencoding, where we design our models to learn residuals based on the space-to-channel transformed features to alleviate the optimization difficulty of high spatial-compression autoencoders; (2) Decoupled High-Resolution Adaptation, an efficient decoupled three-phases training strategy for mitigating the generalization penalty of high spatial-compression autoencoders. With these designs, we improve the autoencoder's spatial compression ratio up to 128 while maintaining the reconstruction quality. Applying our DC-AE to latent diffusion models, we achieve significant speedup without accuracy drop. For example, on ImageNet 512x512, our DC-AE provides 19.1x inference speedup and 17.9x training speedup on H100 GPU for UViT-H while achieving a better FID, compared with the widely used SD-VAE-f8 autoencoder.
# build DC-AE models
# full DC-AE model list: https://huggingface.co/collections/mit-han-lab/dc-ae-670085b9400ad7197bb1009b
from efficientvit.ae_model_zoo import DCAE_HF
dc_ae = DCAE_HF.from_pretrained(f"mit-han-lab/dc-ae-f64c128-in-1.0")
# encode
from PIL import Image
import torch
import torchvision.transforms as transforms
from torchvision.utils import save_image
from efficientvit.apps.utils.image import DMCrop
device = torch.device("cuda")
dc_ae = dc_ae.to(device).eval()
transform = transforms.Compose([
DMCrop(512), # resolution
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
image = Image.open("assets/fig/girl.png")
x = transform(image)[None].to(device)
latent = dc_ae.encode(x)
print(latent.shape)
# decode
y = dc_ae.decode(latent)
save_image(y * 0.5 + 0.5, "demo_dc_ae.png")
# build DC-AE-Diffusion models
# full DC-AE-Diffusion model list: https://huggingface.co/collections/mit-han-lab/dc-ae-diffusion-670dbb8d6b6914cf24c1a49d
from efficientvit.diffusion_model_zoo import DCAE_Diffusion_HF
dc_ae_diffusion = DCAE_Diffusion_HF.from_pretrained(f"mit-han-lab/dc-ae-f64c128-in-1.0-uvit-h-in-512px-train2000k")
# denoising on the latent space
import torch
import numpy as np
from torchvision.utils import save_image
torch.set_grad_enabled(False)
device = torch.device("cuda")
dc_ae_diffusion = dc_ae_diffusion.to(device).eval()
seed = 0
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
eval_generator = torch.Generator(device=device)
eval_generator.manual_seed(seed)
prompts = torch.tensor(
[279, 333, 979, 936, 933, 145, 497, 1, 248, 360, 793, 12, 387, 437, 938, 978], dtype=torch.int, device=device
)
num_samples = prompts.shape[0]
prompts_null = 1000 * torch.ones((num_samples,), dtype=torch.int, device=device)
latent_samples = dc_ae_diffusion.diffusion_model.generate(prompts, prompts_null, 6.0, eval_generator)
latent_samples = latent_samples / dc_ae_diffusion.scaling_factor
# decode
image_samples = dc_ae_diffusion.autoencoder.decode(latent_samples)
save_image(image_samples * 0.5 + 0.5, "demo_dc_ae_diffusion.png", nrow=int(np.sqrt(num_samples)))
If DC-AE is useful or relevant to your research, please kindly recognize our contributions by citing our papers:
@article{chen2024deep,
title={Deep Compression Autoencoder for Efficient High-Resolution Diffusion Models},
author={Chen, Junyu and Cai, Han and Chen, Junsong and Xie, Enze and Yang, Shang and Tang, Haotian and Li, Muyang and Lu, Yao and Han, Song},
journal={arXiv preprint arXiv:2410.10733},
year={2024}
}