
Overview
CLAP
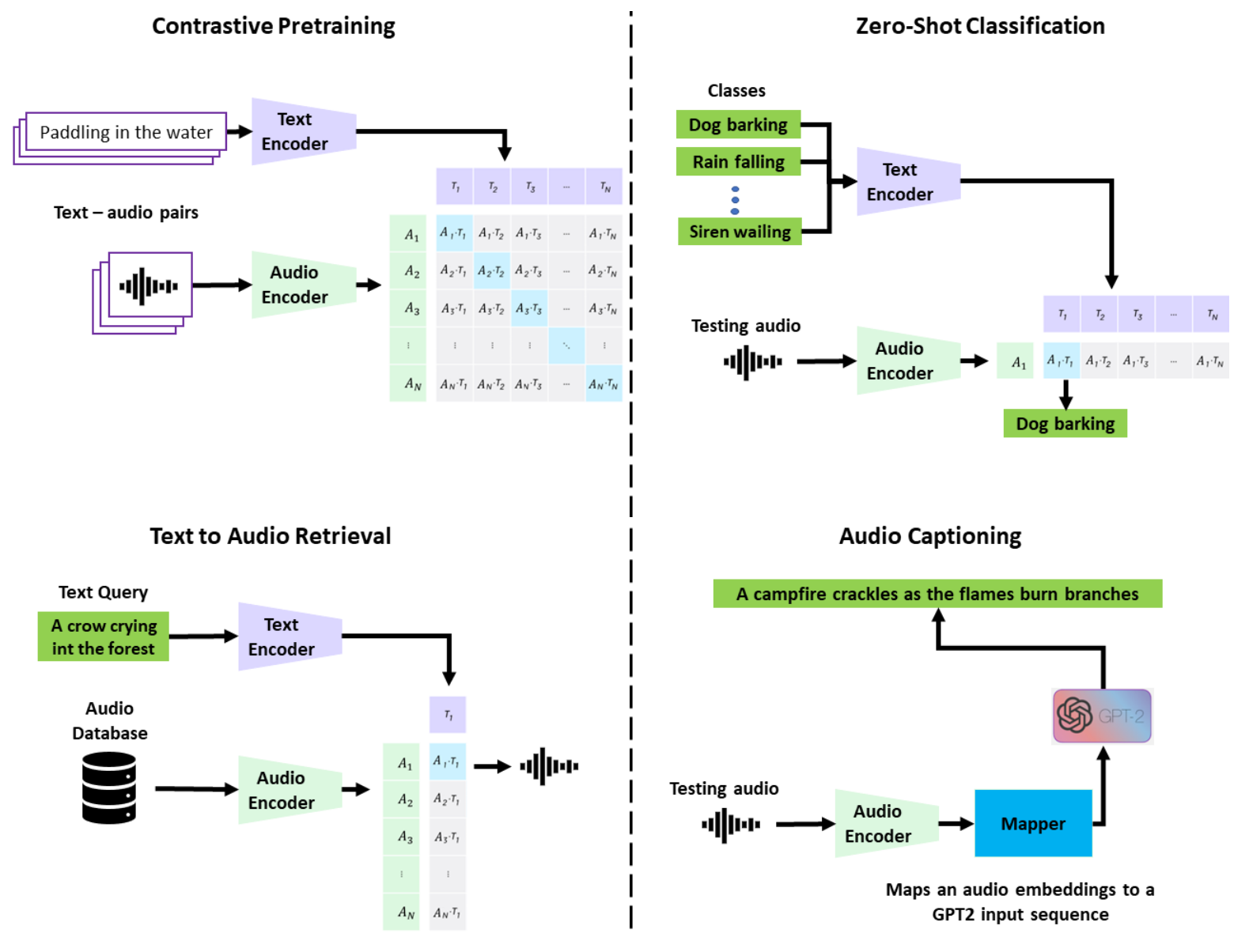
CLAP (Contrastive Language-Audio Pretraining) is a model that learns acoustic concepts from natural language supervision and enables “Zero-Shot” inference. The model has been extensively evaluated in 26 audio downstream tasks achieving SoTA in several of them including classification, retrieval, and captioning.
Setup
First, install python 3.8 or higher (3.11 recommended). Then, install CLAP using either of the following:
# Install pypi pacakge
pip install msclap
# Or Install latest (unstable) git source
pip install git+https://github.com/microsoft/CLAP.git
NEW CLAP weights
CLAP weights: versions 2022, 2023, and clapcap
clapcap is the audio captioning model that uses the 2023 encoders.
Usage
CLAP code is in https://github.com/microsoft/CLAP
- Zero-Shot Classification and Retrieval
from msclap import CLAP
# Load model (Choose between versions '2022' or '2023')
clap_model = CLAP("<PATH TO WEIGHTS>", version = '2023', use_cuda=False)
# Extract text embeddings
text_embeddings = clap_model.get_text_embeddings(class_labels: List[str])
# Extract audio embeddings
audio_embeddings = clap_model.get_audio_embeddings(file_paths: List[str])
# Compute similarity between audio and text embeddings
similarities = clap_model.compute_similarity(audio_embeddings, text_embeddings)
- Audio Captioning
from msclap import CLAP
# Load model (Choose version 'clapcap')
clap_model = CLAP("<PATH TO WEIGHTS>", version = 'clapcap', use_cuda=False)
# Generate audio captions
captions = clap_model.generate_caption(file_paths: List[str])
Citation
Kindly cite our work if you find it useful.
CLAP: Learning Audio Concepts from Natural Language Supervision
@inproceedings{CLAP2022,
title={Clap learning audio concepts from natural language supervision},
author={Elizalde, Benjamin and Deshmukh, Soham and Al Ismail, Mahmoud and Wang, Huaming},
booktitle={ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={1--5},
year={2023},
organization={IEEE}
}
Natural Language Supervision for General-Purpose Audio Representations
@misc{CLAP2023,
title={Natural Language Supervision for General-Purpose Audio Representations},
author={Benjamin Elizalde and Soham Deshmukh and Huaming Wang},
year={2023},
eprint={2309.05767},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2309.05767}
}
Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow Microsoft's Trademark & Brand Guidelines. Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party's policies.