
1. Introduction of this repository
Official Repository of "Can Large Language Models Analyze Graphs like Professionals? A Benchmark, Datasets and Models". NeurIPS 2024
- Paper Link: (https://arxiv.org/abs/2409.19667/)
- GitHub Repository: (https://github.com/BUPT-GAMMA/ProGraph)
2. Pipelines and Experimental Results
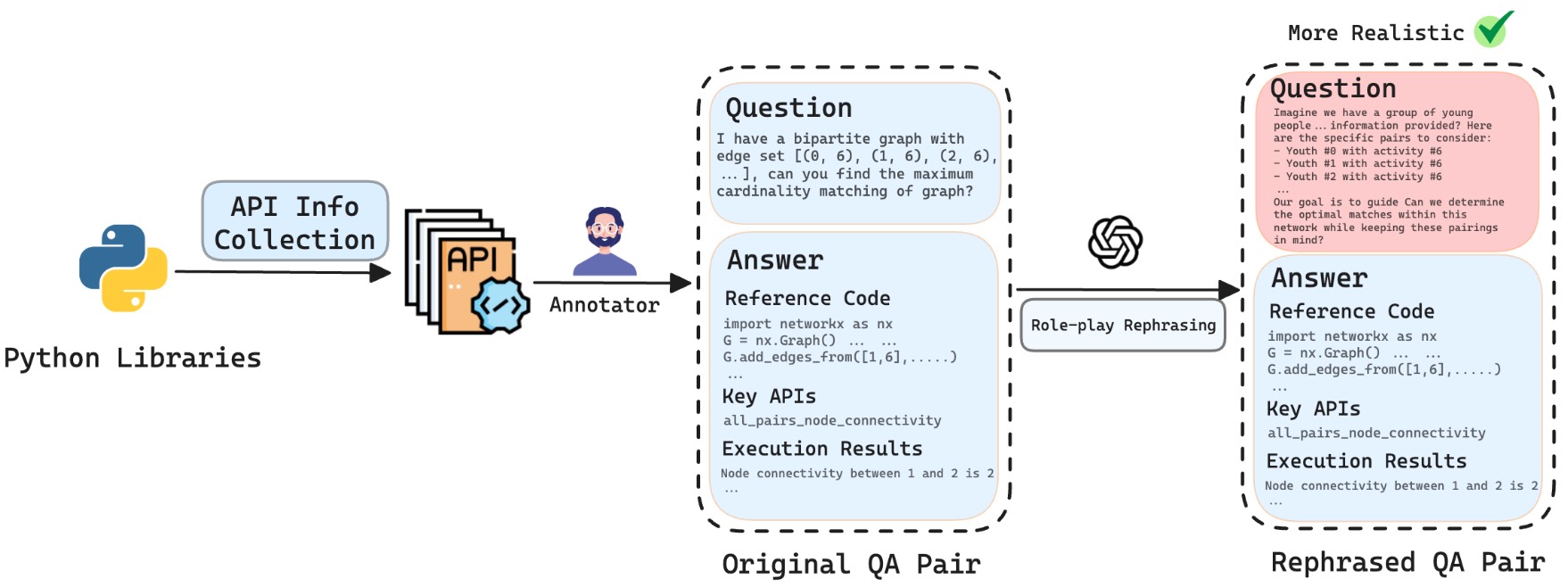
The pipeline of ProGraph benchmark construction
The pipeline of LLM4Graph dataset construction and corresponding model enhancement.

The pass rate (left) and accuracy (right) of open-source models with instruction tuning.

Compilation error statistics for open source models.

Performance (%) of open-source models regarding different question types.
| Model | Method | True/False | Drawing | Calculation | Hybrid | ||||
|---|---|---|---|---|---|---|---|---|---|
| Pass Rate | Accuracy | Pass Rate | Accuracy | Pass Rate | Accuracy | Pass Rate | Accuracy | ||
| Llama 3 | No Fine-tune | 43.6 | 33.3 | 28.3 | 10.0 | 15.6 | 12.5 | 26.8 | 8.3 |
| Code Only | 82.1 | 71.8 | 59.2 | 42.0 | 34.4 | 31.3 | 60.7 | 43.6 | |
| Code+RAG 3 | 84.6 | 44.0 | 56.9 | 29.0 | 50.0 | 37.5 | 66.1 | 37.2 | |
| Code+RAG 5 | 66.7 | 36.8 | 53.5 | 25.4 | 37.5 | 28.1 | 60.7 | 36.3 | |
| Code+RAG 7 | 66.7 | 37.2 | 50.9 | 24.4 | 50.0 | 35.9 | 64.3 | 39.3 | |
| Doc+Code | 82.1 | 73.1 | 64.4 | 43.7 | 40.6 | 31.8 | 67.9 | 41.3 | |
| Deepseek Coder | No Fine-tune | 66.7 | 41.5 | 47.8 | 22.1 | 53.1 | 39.4 | 46.4 | 18.2 |
| Code Only | 71.8 | 61.5 | 60.0 | 41.1 | 50.0 | 45.3 | 62.5 | 42.1 | |
| Code+RAG 3 | 71.8 | 48.3 | 57.7 | 32.2 | 53.1 | 45.3 | 44.6 | 22.8 | |
| Code+RAG 5 | 71.8 | 53.9 | 50.7 | 29.3 | 40.6 | 34.4 | 39.3 | 28.6 | |
| Code+RAG 7 | 74.4 | 54.7 | 50.4 | 28.7 | 37.5 | 34.4 | 48.2 | 31.4 | |
| Doc+Code | 79.5 | 68.0 | 66.2 | 46.0 | 37.5 | 34.4 | 66.1 | 42.3 |
3. How to Use
Here give some examples of how to use our models.
Chat Model Inference
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, StoppingCriteria, StoppingCriteriaList
from peft import PeftModel
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model_name_or_path = '../models/deepseek-ai/deepseek-coder-7b-instruct-v1.5'
# You can use Llama-3-8B by 'meta-llama/Meta-Llama-3-8B-Instruct'.
# You can also use your local path.
peft_model_path = 'https://huggingface.co/lixin4sky/ProGraph/tree/main/deepseek-code-only'
# Or other models in the repository.
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path).to(device)
peft_model = PeftModel.from_pretrained(model, peft_model_path).to(device)
input_text = '' # the question.
message = [
{"role": "user", "content": f"{input_text}"},
]
input_ids = tokenizer.apply_chat_template(conversation=message,
tokenize=True,
add_generation_prompt=False,
return_tensors='pt')
input_ids = input_ids.to("cuda:0" if torch.cuda.is_available() else "cpu")
with torch.inference_mode():
output_ids = model.generate(input_ids=input_ids[:, :-3], max_new_tokens=4096, do_sample=False, pad_token_id=2)
response = tokenizer.batch_decode(output_ids.detach().cpu().numpy(), skip_special_tokens = True)
print(response)
You can find more tutorials in our GitHub repository: (https://github.com/BUPT-GAMMA/ProGraph)
4. Next Level
- GraphTeam: (https://arxiv.org/abs/2410.18032)
- Github Repository: (https://github.com/BUPT-GAMMA/GraphTeam)
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support
Model tree for lixin4sky/ProGraph
Base model
deepseek-ai/deepseek-coder-7b-instruct-v1.5