Token 分类

我们将探索的第一个应用是Token分类。这个通用任务包括任何可以表述为“为句子中的词或字分配标签”的问题,例如:
- 实体命名识别 (NER): 找出句子中的实体(如人物、地点或组织)。这可以通过为每个实体或“无实体”指定一个类别的标签。
- 词性标注 (POS): 将句子中的每个单词标记为对应于特定的词性(如名词、动词、形容词等)。
- 分块(chunking): 找到属于同一实体的Token。这个任务(可结合POS或NER)可以任何将一块Token作为制定一个标签(通常是B -),另一个标签(通常I -)表示Token是否是同一块,和第三个标签(通常是O)表示Token不属于任何块。也就是标出句子中的短语块,例如名词短语(NP),动词短语(VP)等。
当然,还有很多其他类型的token分类问题;这些只是几个有代表性的例子。在本节中,我们将在 NER 任务上微调模型 (BERT),然后该模型将能够计算如下预测:
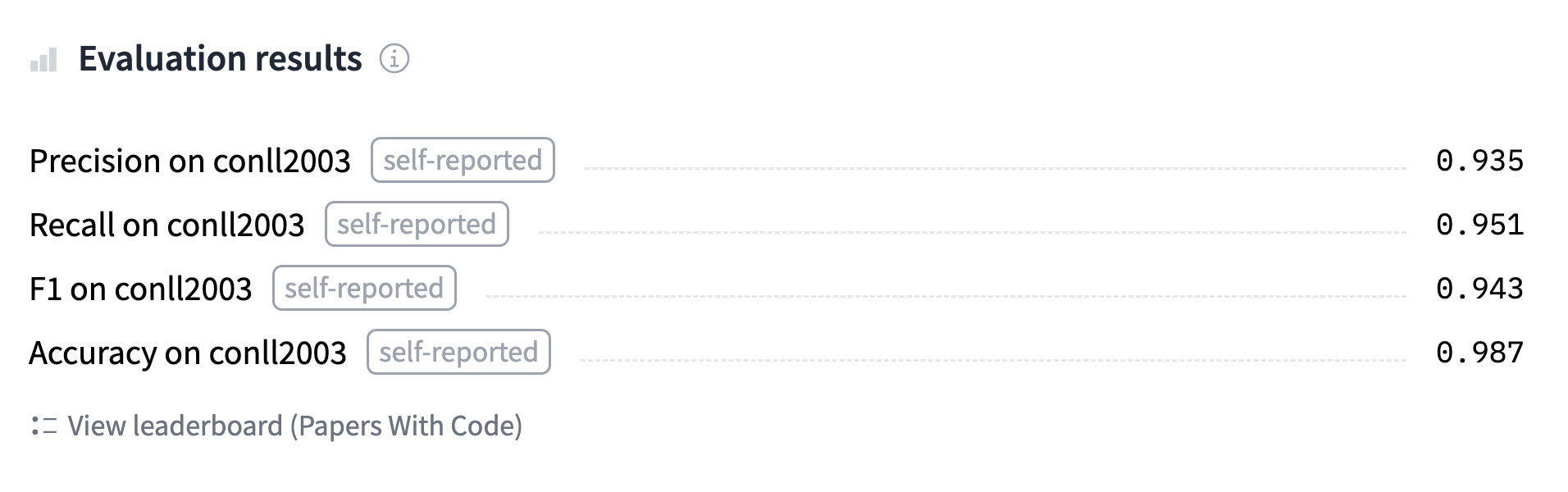
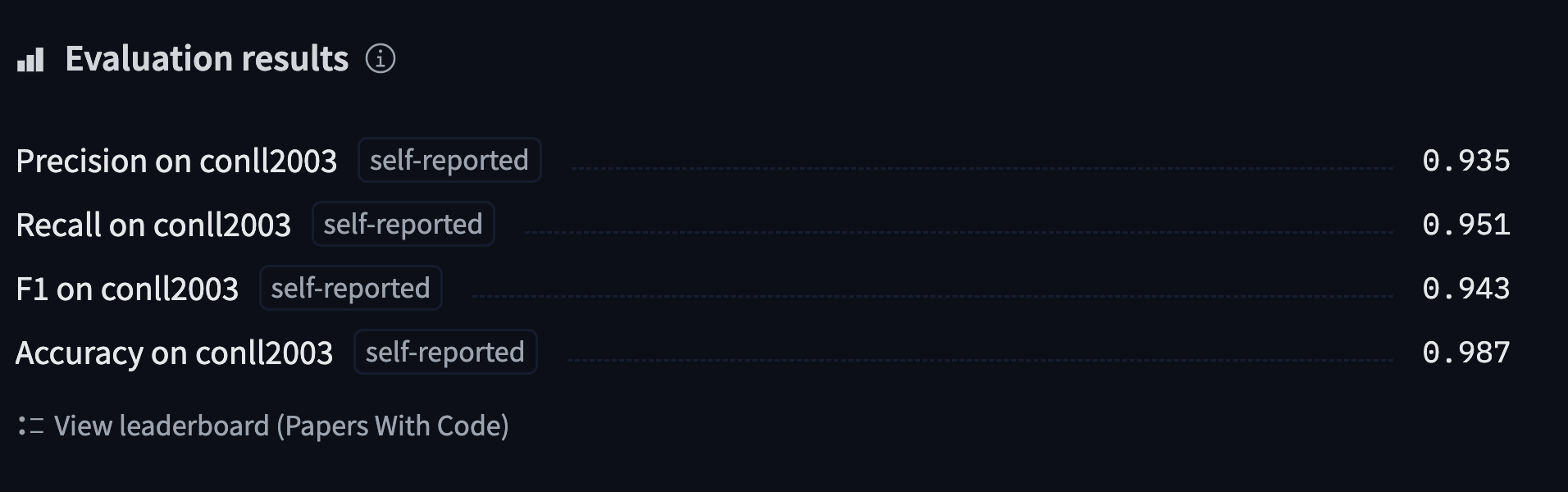
您可以在这里.找到我们将训练并上传到 Hub的模型,可以尝试输入一些句子看看模型的预测结果。
准备数据
首先,我们需要一个适合标记分类的数据集。在本节中,我们将使用CoNLL-2003 数据集, 其中包含来自路透社的新闻报道。
💡 只要您的数据集由带有相应标签的分割成单词并的文本组成,您就能够将这里描述的数据处理过程应用到您自己的数据集。如果需要复习如何在.Dataset中加载自定义数据,请参阅Chapter 5。
CoNLL-2003 数据集
要加载 CoNLL-2003 数据集,我们使用 来自 🤗 Datasets 库的load_dataset() 方法:
from datasets import load_dataset
raw_datasets = load_dataset("conll2003")这将下载并缓存数据集,就像和我们在第三章 加载GLUE MRPC 数据集一样。检查这个对象可以让我们看到存在哪些列,以及训练集、验证集和测试集之间是如何分割的:
raw_datasets
DatasetDict({
train: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 14041
})
validation: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 3250
})
test: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 3453
})
})特别是,我们可以看到数据集包含我们之前提到的三个任务的标签:NER、POS 和chunking。与其他数据集的一个很大区别是输入文本不是作为句子或文档呈现的,而是单词列表(最后一列称为 tokens ,但它包含的是这些词是预先标记化的输入,仍然需要通过标记器进行子词标记)。
我们来看看训练集的第一个元素:
raw_datasets["train"][0]["tokens"]['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb', '.']由于我们要执行命名实体识别,我们将查看 NER 标签:
raw_datasets["train"][0]["ner_tags"][3, 0, 7, 0, 0, 0, 7, 0, 0]这一列是类标签的序列。元素的类型在ner_feature的feature属性中,我们可以通过查看该特性的names属性来访问名称列表:
ner_feature = raw_datasets["train"].features["ner_tags"]
ner_featureSequence(feature=ClassLabel(num_classes=9, names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC'], names_file=None, id=None), length=-1, id=None)因此,这一列包含的元素是ClassLabels的序列。序列元素的类型在ner_feature的feature中,我们可以通过查看该feature的names属性来访问名称列表:
label_names = ner_feature.feature.names label_names
['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC']我们在第六章, 深入研究token-classification 管道时已经看到了这些标签 ,但为了快速复习:
O表示这个词不对应任何实体。B-PER/I-PER意味着这个词对应于人名实体的开头/内部。B-ORG/I-ORG的意思是这个词对应于组织名称实体的开头/内部。B-LOC/I-LOC指的是是这个词对应于地名实体的开头/内部。B-MISC/I-MISC表示该词对应于一个杂项实体的开头/内部。
现在解码我们之前看到的标签:
words = raw_datasets["train"][0]["tokens"]
labels = raw_datasets["train"][0]["ner_tags"]
line1 = ""
line2 = ""
for word, label in zip(words, labels):
full_label = label_names[label]
max_length = max(len(word), len(full_label))
line1 += word + " " * (max_length - len(word) + 1)
line2 += full_label + " " * (max_length - len(full_label) + 1)
print(line1)
print(line2)'EU rejects German call to boycott British lamb .'
'B-ORG O B-MISC O O O B-MISC O O'例如混合 B- 和 I- 标签,这是相同的代码在索引 4 的训练集元素上的预测结果:
'Germany \'s representative to the European Union \'s veterinary committee Werner Zwingmann said on Wednesday consumers should buy sheepmeat from countries other than Britain until the scientific advice was clearer .'
'B-LOC O O O O B-ORG I-ORG O O O B-PER I-PER O O O O O O O O O O O B-LOC O O O O O O O'正如我们所看到的,跨越两个单词的实体,如“European Union”和“Werner Zwingmann”,模型为第一个单词标注了一个B-标签,为第二个单词标注了一个I-标签。
✏️ 轮到你了! 使用 POS 或chunking标签识别同一个句子。
处理数据
像往常一样,我们的文本需要转换为Token ID,然后模型才能理解它们。正如我们在第六章所学的那样。不过在标记任务中,一个很大的区别是我们有pre-tokenized的输入。幸运的是,tokenizer API可以很容易地处理这个问题;我们只需要用一个特殊的tokenizer。
首先,让我们创建tokenizer对象。如前所述,我们将使用 BERT 预训练模型,因此我们将从下载并缓存关联的分词器开始:
from transformers import AutoTokenizer
model_checkpoint = "bert-base-cased"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)你可以更换把 model_checkpoint 更换为 Hub,上您喜欢的任何其他型号,或使用您本地保存的预训练模型和分词器。唯一的限制是分词器需要由 🤗 Tokenizers 库支持,有一个“快速”版本可用。你可以在这张大表, 上看到所有带有快速版本的架构,或者检查 您可以通过查看它is_fast 属性来检测正在使用的tokenizer对象是否由 🤗 Tokenizers 支持:
tokenizer.is_fast
True要对预先标记的输入进行标记,我们可以像往常一样使用我们的tokenizer 只需添加 is_split_into_words=True:
inputs = tokenizer(raw_datasets["train"][0]["tokens"], is_split_into_words=True)
inputs.tokens()['[CLS]', 'EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'la', '##mb', '.', '[SEP]']正如我们所见,分词器添加了模型使用的特殊Token([CLS] 在开始和[SEP] 最后) 而大多数单词未被修改。然而,单词 lamb,被分为两个子单词 la and ##mb。这导致了输入和标签之间的不匹配:标签列表只有9个元素,而我们的输入现在有12个token 。计算特殊Token很容易(我们知道它们在开头和结尾),但我们还需要确保所有标签与适当的单词对齐。
幸运的是,由于我们使用的是快速分词器,因此我们可以访问🤗 Tokenizers超能力,这意味着我们可以轻松地将每个令牌映射到其相应的单词(如Chapter 6):
inputs.word_ids()
[None, 0, 1, 2, 3, 4, 5, 6, 7, 7, 8, None]通过一点点工作,我们可以扩展我们的标签列表以匹配token 。我们将应用的第一条规则是,特殊token 的标签为 -100 。这是因为默认情况下 -100 是一个在我们将使用的损失函数(交叉熵)中被忽略的索引。然后,每个token 都会获得与其所在单词的token 相同的标签,因为它们是同一实体的一部分。对于单词内部但不在开头的Token,我们将B- 替换为 I- (因为token 不以实体开头):
def align_labels_with_tokens(labels, word_ids):
new_labels = []
current_word = None
for word_id in word_ids:
if word_id != current_word:
# Start of a new word!
current_word = word_id
label = -100 if word_id is None else labels[word_id]
new_labels.append(label)
elif word_id is None:
# Special token
new_labels.append(-100)
else:
# Same word as previous token
label = labels[word_id]
# If the label is B-XXX we change it to I-XXX
if label % 2 == 1:
label += 1
new_labels.append(label)
return new_labels让我们在我们的第一句话上试一试:
labels = raw_datasets["train"][0]["ner_tags"]
word_ids = inputs.word_ids()
print(labels)
print(align_labels_with_tokens(labels, word_ids))[3, 0, 7, 0, 0, 0, 7, 0, 0]
[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]正如我们所看到的,我们的函数为开头和结尾的两个特殊标记添加了 -100 ,并为分成两个标记的单词添加了一个新的0 。
✏️ 轮到你了! 一些研究人员更喜欢每个词只归属一个标签, 并分配 -100 给定词中的其他子标记。这是为了避免分解成大量子标记的长词对损失造成严重影响。按照此规则更改前一个函数使标签与输入id对齐。
为了预处理我们的整个数据集,我们需要标记所有输入并在所有标签上应用 align_labels_with_tokens() 。为了利用我们的快速分词器的速度优势,最好同时对大量文本进行分词,因此我们将编写一个处理示例列表的函数并使用带 batched=True 有选项的 Dataset.map()方法 .与我们之前的示例唯一不同的是当分词器的输入是文本列表(或者像例子中的单词列表)时 word_ids() 函数需要获取我们想要单词的索引的ID,所以我们也添加它:
def tokenize_and_align_labels(examples):
tokenized_inputs = tokenizer(
examples["tokens"], truncation=True, is_split_into_words=True
)
all_labels = examples["ner_tags"]
new_labels = []
for i, labels in enumerate(all_labels):
word_ids = tokenized_inputs.word_ids(i)
new_labels.append(align_labels_with_tokens(labels, word_ids))
tokenized_inputs["labels"] = new_labels
return tokenized_inputs请注意,我们还没有填充我们的输入;我们稍后会在使用数据整理器创建batch时这样做。
我们现在可以一次性将所有预处理应用于数据集的其他部分:
tokenized_datasets = raw_datasets.map(
tokenize_and_align_labels,
batched=True,
remove_columns=raw_datasets["train"].column_names,
)我们已经完成了最难的部分!现在数据已经被预处理了,实际的训练看起来很像我们第三章做的.
使用 Trainer API 微调模型
使用 Trainer 的实际代码会和以前一样;唯一的变化是数据整理成时批处理的方式和度量计算函数。
数据排序
我们不能像第三章那样只使用一个 DataCollatorWithPadding 因为这只会填充输入(输入 ID、注意掩码和标记类型 ID)。在这里我们的标签应该以与输入完全相同的方式填充,以便它们保持长度相同,使用 -100 ,这样在损失计算中就可以忽略相应的预测。
这一切都是由一个 DataCollatorForTokenClassification完成.它是一个带有填充的数据整理器它需要 tokenizer 用于预处理输入:
from transformers import DataCollatorForTokenClassification
data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)为了在几个样本上测试这一点,我们可以在训练集中的示例列表上调用它:
batch = data_collator([tokenized_datasets["train"][i] for i in range(2)])
batch["labels"]tensor([[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100],
[-100, 1, 2, -100, -100, -100, -100, -100, -100, -100, -100, -100]])让我们将其与数据集中第一个和第二个元素的标签进行比较:
for i in range(2):
print(tokenized_datasets["train"][i]["labels"])[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
[-100, 1, 2, -100]正如我们所看到的,第二组标签的长度已经使用 -100 填充到与第一组标签相同。
评估指标
为了让 Trainer 在每个epoch计算一个度量,我们需要定义一个 compute_metrics() 函数,该函数接受预测和标签数组,并返回一个包含度量名称和值的字典
用于评估Token分类预测的传统框架是 seqeval. 要使用此指标,我们首先需要安装seqeval库:
!pip install seqeval
然后我们可以通过加载它 evaluate.load() 函数就像我们在第三章做的那样:
import evaluate
metric = evaluate.load("seqeval")这个评估方式与标准精度不同:它实际上将标签列表作为字符串,而不是整数,因此在将预测和标签传递给它之前,我们需要完全解码它们。让我们看看它是如何工作的。首先,我们将获得第一个训练示例的标签:
labels = raw_datasets["train"][0]["ner_tags"]
labels = [label_names[i] for i in labels]
labels['B-ORG', 'O', 'B-MISC', 'O', 'O', 'O', 'B-MISC', 'O', 'O']然后我们可以通过更改索引 2 处的值来为那些创建假的预测:
predictions = labels.copy()
predictions[2] = "O"
metric.compute(predictions=[predictions], references=[labels])请注意,该指标的输入是预测列表(不仅仅是一个)和标签列表。这是输出:
{'MISC': {'precision': 1.0, 'recall': 0.5, 'f1': 0.67, 'number': 2},
'ORG': {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 1},
'overall_precision': 1.0,
'overall_recall': 0.67,
'overall_f1': 0.8,
'overall_accuracy': 0.89}它返回很多信息!我们获得每个单独实体以及整体的准确率、召回率和 F1 分数。对于我们的度量计算,我们将只保留总分,但可以随意调整 compute_metrics() 函数返回您想要查看的所有指标。
这compute_metrics() 函数首先采用 logits 的 argmax 将它们转换为预测(像往常一样,logits 和概率的顺序相同,因此我们不需要应用 softmax)。然后我们必须将标签和预测从整数转换为字符串。我们删除标签为 -100 所有值 ,然后将结果传递给 metric.compute() 方法:
import numpy as np
def compute_metrics(eval_preds):
logits, labels = eval_preds
predictions = np.argmax(logits, axis=-1)
# Remove ignored index (special tokens) and convert to labels
true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
true_predictions = [
[label_names[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
all_metrics = metric.compute(predictions=true_predictions, references=true_labels)
return {
"precision": all_metrics["overall_precision"],
"recall": all_metrics["overall_recall"],
"f1": all_metrics["overall_f1"],
"accuracy": all_metrics["overall_accuracy"],
}现在已经完成了,我们几乎准备好定义我们的 Trainer .我们只需要一个 model 微调!
定义模型
由于我们正在研究Token分类问题,因此我们将使用 AutoModelForTokenClassification 类。定义这个模型时要记住的主要事情是传递一些关于我们的标签数量的信息。执行此操作的最简单方法是将该数字传递给 num_labels 参数,但是如果我们想要一个很好的推理小部件,就像我们在本节开头看到的那样,最好设置正确的标签对应关系。
它们应该由两个字典设置, id2label 和 label2id ,其中包含从 ID 到标签的映射,反之亦然:
id2label = {str(i): label for i, label in enumerate(label_names)}
label2id = {v: k for k, v in id2label.items()}现在我们可以将它们传递给 AutoModelForTokenClassification.from_pretrained() 方法,它们将在模型的配置中设置,然后保存并上传到Hub:
from transformers import AutoModelForTokenClassification
model = AutoModelForTokenClassification.from_pretrained(
model_checkpoint,
id2label=id2label,
label2id=label2id,
)就像我们在第三章,定义我们的 AutoModelForSequenceClassification ,创建模型会发出警告,提示一些权重未被使用(来自预训练头的权重)和一些其他权重被随机初始化(来自新Token分类头的权重),我们将要训练这个模型。我们将在一分钟内完成,但首先让我们仔细检查我们的模型是否具有正确数量的标签:
model.config.num_labels
9⚠️ 如果模型的标签数量错误,稍后调用Trainer.train()方法时会出现一个模糊的错误(类似于“CUDA error: device-side assert triggered”)。这是用户报告此类错误的第一个原因,因此请确保进行这样的检查以确认您拥有预期数量的标签。
微调模型
我们现在准备好训练我们的模型了!在定义我们的 Trainer之前,我们只需要做最后两件事:登录 Hugging Face 并定义我们的训练参数。如果您在notebook上工作,有一个方便的功能可以帮助您:
from huggingface_hub import notebook_login
notebook_login()这将显示一个小部件,您可以在其中输入您的 Hugging Face 账号和密码。如果您不是在notebook上工作,只需在终端中输入以下行:
huggingface-cli login
Once this is done, we can define our TrainingArguments:
from transformers import TrainingArguments
args = TrainingArguments(
"bert-finetuned-ner",
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=2e-5,
num_train_epochs=3,
weight_decay=0.01,
push_to_hub=True,
)您之前已经看过其中的大部分内容:我们设置了一些超参数(例如学习率、要训练的 epoch 数和权重衰减),然后我们指定 push_to_hub=True 表明我们想要保存模型并在每个时期结束时对其进行评估,并且我们想要将我们的结果上传到模型中心。请注意,可以使用hub_model_id参数指定要推送到的存储库的名称(特别是,必须使用这个参数来推送到一个组织)。例如,当我们将模型推送到huggingface-course organization, 我们添加了 hub_model_id=huggingface-course/bert-finetuned-ner 到 TrainingArguments 。默认情况下,使用的存储库将在您的命名空间中并以您设置的输出目录命名,因此在我们的例子中它将是 sgugger/bert-finetuned-ner。
💡 如果您正在使用的输出目录已经存在,那么输出目录必须是从同一个存储库clone下来的。如果不是,您将在声明 Trainer 时遇到错误,并且需要设置一个新名称。
最后,我们只是将所有内容传递给 Trainer 并启动训练:
from transformers import Trainer
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
compute_metrics=compute_metrics,
tokenizer=tokenizer,
)
trainer.train()请注意,当训练发生时,每次保存模型时(这里是每个epooch),它都会在后台上传到 Hub。这样,如有必要,您将能够在另一台机器上继续您的训练。
训练完成后,我们使用 push_to_hub() 确保我们上传模型的最新版本
trainer.push_to_hub(commit_message="Training complete")This command returns the URL of the commit it just did, if you want to inspect it:
'https://huggingface.co/sgugger/bert-finetuned-ner/commit/26ab21e5b1568f9afeccdaed2d8715f571d786ed'这 Trainer 还创建了一张包含所有评估结果的模型卡并上传。在此阶段,您可以使用模型中心上的推理小部件来测试您的模型并与您的朋友分享。您已成功在Token分类任务上微调模型 - 恭喜!
如果您想更深入地了解训练循环,我们现在将向您展示如何使用 🤗 Accelerate 做同样的事情。
自定义训练循环
现在让我们看一下完整的训练循环,这样您可以轻松定义所需的部分。它看起来很像我们在第三章, 所做的,对评估进行了一些更改。
做好训练前的准备
首先我们需要为我们的数据集构建 DataLoader 。我们将重用我们的 data_collator 作为一个 collate_fn 并打乱训练集,但不打乱验证集:
from torch.utils.data import DataLoader
train_dataloader = DataLoader(
tokenized_datasets["train"],
shuffle=True,
collate_fn=data_collator,
batch_size=8,
)
eval_dataloader = DataLoader(
tokenized_datasets["validation"], collate_fn=data_collator, batch_size=8
)接下来,我们重新实例化我们的模型,以确保我们不会从之前的训练继续训练,而是再次从 BERT 预训练模型开始:
model = AutoModelForTokenClassification.from_pretrained(
model_checkpoint,
id2label=id2label,
label2id=label2id,
)然后我们将需要一个优化器。我们将使用经典 AdamW ,这就像 Adam ,但在应用权重衰减的方式上进行了改进:
from torch.optim import AdamW
optimizer = AdamW(model.parameters(), lr=2e-5)Once we have all those objects, we can send them to the accelerator.prepare() method:
from accelerate import Accelerator
accelerator = Accelerator()
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader
)🚨 如果您在 TPU 上进行训练,则需要将以上单元格中的所有代码移动到专用的训练函数中。有关详细信息,请参阅 第3章。
现在我们已经发送了我们的 train_dataloader 到 accelerator.prepare() ,我们可以使用它的长度来计算训练步骤的数量。请记住,我们应该始终在准备好dataloader后执行此操作,因为该方法会改变其长度。我们使用经典线性学习率调度:
from transformers import get_scheduler
num_train_epochs = 3
num_update_steps_per_epoch = len(train_dataloader)
num_training_steps = num_train_epochs * num_update_steps_per_epoch
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)最后,要将我们的模型推送到 Hub,我们需要创建一个 Repository 工作文件夹中的对象。如果您尚未登录,请先登录 Hugging Face。我们将从我们想要为模型提供的模型 ID 中确定存储库名称(您可以自由地用自己的选择替换 repo_name ;它只需要包含您的用户名,可以使用get_full_repo_name()函数的查看目前的repo_name):
from huggingface_hub import Repository, get_full_repo_name
model_name = "bert-finetuned-ner-accelerate"
repo_name = get_full_repo_name(model_name)
repo_name'sgugger/bert-finetuned-ner-accelerate'然后我们可以将该存储库克隆到本地文件夹中。 如果它已经存在,这个本地文件夹应该是我们正在使用的存储库的现有克隆:
output_dir = "bert-finetuned-ner-accelerate"
repo = Repository(output_dir, clone_from=repo_name)我们现在可以通过调用 repo.push_to_hub() 方法上传保存在 output_dir 中的任何内容。 这将帮助我们在每个训练周期结束时上传中间模型。
训练循环
我们现在准备编写完整的训练循环。为了简化它的评估部分,我们定义了这个 postprocess() 接受预测和标签并将它们转换为字符串列表的函数,也就是 metric对象需要的输入格式:
def postprocess(predictions, labels):
predictions = predictions.detach().cpu().clone().numpy()
labels = labels.detach().cpu().clone().numpy()
# Remove ignored index (special tokens) and convert to labels
true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
true_predictions = [
[label_names[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
return true_labels, true_predictions然后我们可以编写训练循环。在定义一个进度条来跟踪训练的进行后,循环分为三个部分:
- 训练本身,这是对
train_dataloader的经典迭代,向前传递模型,然后反向传递和优化参数 - 评估,在获得我们模型的输出后:因为两个进程可能将输入和标签填充成不同的形状,在调用
gather()方法前我们需要使用accelerator.pad_across_processes()来让预测和标签形状相同。如果我们不这样做,评估要么出错,要么永远不会得到结果。然后,我们将结果发送给metric.add_batch(),并在计算循环结束后调用metric.compute()。 - 保存和上传,首先保存模型和标记器,然后调用
repo.push_to_hub()。注意,我们使用参数blocking=False告诉🤗 hub 库用在异步进程中推送。这样,训练将正常继续,并且该(长)指令将在后台执行。
这是训练循环的完整代码:
from tqdm.auto import tqdm
import torch
progress_bar = tqdm(range(num_training_steps))
for epoch in range(num_train_epochs):
# Training
model.train()
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
# Evaluation
model.eval()
for batch in eval_dataloader:
with torch.no_grad():
outputs = model(**batch)
predictions = outputs.logits.argmax(dim=-1)
labels = batch["labels"]
# Necessary to pad predictions and labels for being gathered
predictions = accelerator.pad_across_processes(predictions, dim=1, pad_index=-100)
labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
predictions_gathered = accelerator.gather(predictions)
labels_gathered = accelerator.gather(labels)
true_predictions, true_labels = postprocess(predictions_gathered, labels_gathered)
metric.add_batch(predictions=true_predictions, references=true_labels)
results = metric.compute()
print(
f"epoch {epoch}:",
{
key: results[f"overall_{key}"]
for key in ["precision", "recall", "f1", "accuracy"]
},
)
# Save and upload
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
if accelerator.is_main_process:
tokenizer.save_pretrained(output_dir)
repo.push_to_hub(
commit_message=f"Training in progress epoch {epoch}", blocking=False
)果这是您第一次看到用 🤗 Accelerate 保存的模型,让我们花点时间检查一下它附带的三行代码:
accelerator.wait_for_everyone() unwrapped_model = accelerator.unwrap_model(model) unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
第一行是不言自明的:它告诉所有进程等到都处于那个阶段再继续(阻塞)。这是为了确保在保存之前,我们在每个过程中都有相同的模型。然后获取unwrapped_model,它是我们定义的基本模型。
accelerator.prepare()方法将模型更改为在分布式训练中工作,所以它不再有save_pretraining()方法;accelerator.unwrap_model()方法将撤销该步骤。最后,我们调用save_pretraining(),但告诉该方法使用accelerator.save()而不是torch.save()。
当完成之后,你应该有一个模型,它产生的结果与Trainer的结果非常相似。你可以在hugs face-course/bert-fine - tuning -ner-accelerate中查看我们使用这个代码训练的模型。如果你想测试训练循环的任何调整,你可以直接通过编辑上面显示的代码来实现它们!
使用微调模型
我们已经向您展示了如何使用我们在模型中心微调的模型和推理小部件。在本地使用它 pipeline ,您只需要指定正确的模型标识符:
from transformers import pipeline
# Replace this with your own checkpoint
model_checkpoint = "huggingface-course/bert-finetuned-ner"
token_classifier = pipeline(
"token-classification", model=model_checkpoint, aggregation_strategy="simple"
)
token_classifier("My name is Sylvain and I work at Hugging Face in Brooklyn.")[{'entity_group': 'PER', 'score': 0.9988506, 'word': 'Sylvain', 'start': 11, 'end': 18},
{'entity_group': 'ORG', 'score': 0.9647625, 'word': 'Hugging Face', 'start': 33, 'end': 45},
{'entity_group': 'LOC', 'score': 0.9986118, 'word': 'Brooklyn', 'start': 49, 'end': 57}]太棒了!我们的模型与此管道的默认模型一样有效!