Phân loại token

Ứng dụng đầu tiên chúng ta sẽ cùng khám phá là phân loại token. Tác vụ chung này bao gồm bất kỳ vấn đề nào có thể được xây dựng dưới dạng “gán nhãn cho mỗi token trong một câu”, chẳng hạn như:
- Nhận dạng thực thể được đặt tên (NER): Tìm các thực thể (chẳng hạn như người, địa điểm hoặc tổ chức) trong một câu. Điều này có thể được xây dựng như là gán nhãn cho mỗi token bằng cách có một nhãn cho mỗi thực thể và một nhãn cho “không có thực thể”.
- Gán nhãn từ loại (POS): Đánh dấu mỗi từ trong câu tương ứng với một từ loại cụ thể của văn bản (chẳng hạn như danh từ, động từ, tính từ, v.v.).
- Phân khúc: Tìm các token thuộc cùng một thực thể. Tác vụ này (có thể được kết hợp với POS hoặc NER) có thể được xây dựng dưới dạng gán một nhãn (thường là
B-) cho bất kỳ token nào ở đầu một đoạn, một nhãn khác (thường làI-) cho các token đó nằm bên trong một đoạn và một nhãn thứ ba (thường làO) token không thuộc bất kỳ đoạn nào.
Tất nhiên, có nhiều loại vấn đề phân loại token khác; đó chỉ là một vài ví dụ tiêu biểu. Trong phần này, chúng ta sẽ tinh chỉnh một mô hình (BERT) trên một tác vụ NER, sau đó sẽ có thể tính toán các dự đoán như sau:
Bạn có thể tìm mô hình ta sẽ huấn luyện và tải lên Hub và kiểm tra lại các dự đoán tại đây.
Chuẩn bị dữ liệu
Đầu tiên, ta cần bộ dữ liệu chuẩn bị cho phân loại token. Trong chương này, chúng ta sẽ sử dụng bộ dữ liệu CoNLL-2003, bao gồm các câu chuyện tin tức từ Reuters.
💡 Miễn là tập dữ liệu của bạn bao gồm các văn bản được chia thành các từ với nhãn tương ứng của chúng, bạn sẽ có thể điều chỉnh các quy trình xử lý dữ liệu được mô tả ở đây với tập dữ liệu của riêng bạn. Tham khảo lại Chapter 5 nếu bạn cần cập nhật về cách tải dữ liệu tùy chỉnh của riêng bạn trong Dataset.
Tập dữ liệu CoNLL-2003
Để tải bộ dữ liệu CoNLL-2003, ta cần sử dụng phương thức load_dataset() từ thư viện 🤗 Datasets:
from datasets import load_dataset
raw_datasets = load_dataset("conll2003")Ta sẽ tải và lưu bộ dữ liệu vào cache, như ta đã thấy trong Chương 3 cho bộ dữ liệu GLUE MRPC. Việc kiểm tra đối tượng này cho chúng ta thấy các cột hiện có và sự phân chia giữa các tập huấn luyện, kiểm định và kiểm thử:
raw_datasets
DatasetDict({
train: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 14041
})
validation: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 3250
})
test: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 3453
})
})Đặc biệt, chúng ta có thể thấy tập dữ liệu chứa các nhãn cho ba tác vụ mà chúng ta đã đề cập trước đó: NER, POS và chunking. Một sự khác biệt lớn so với các bộ dữ liệu khác là các văn bản đầu vào không được trình bày dưới dạng câu hoặc tài liệu, mà là danh sách các từ (cột cuối cùng được gọi là tokens, nhưng nó chứa các từ theo nghĩa đây là các đầu vào được tokenize trước vẫn cần để đi qua trình tokenize để tokenize từ phụ).
Hãy xem phần tử đầu tiên của tập huấn luyện:
raw_datasets["train"][0]["tokens"]['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb', '.']Vì ta muốn thực hiện nhận dạng thực thể được đặt tên, chúng ta sẽ nhìn vào các thẻ NER:
raw_datasets["train"][0]["ner_tags"][3, 0, 7, 0, 0, 0, 7, 0, 0]Đó là những nhãn dưới dạng số nguyên sẵn sàng để huấn luyện, nhưng chúng không nhất thiết hữu ích khi chúng ta muốn kiểm tra dữ liệu. Giống như phân loại văn bản, chúng ta có thể truy cập sự tương ứng giữa các số nguyên đó và tên nhãn bằng cách xem thuộc tính features của tập dữ liệu:
ner_feature = raw_datasets["train"].features["ner_tags"]
ner_featureSequence(feature=ClassLabel(num_classes=9, names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC'], names_file=None, id=None), length=-1, id=None)Vì vậy, cột này chứa các phần tử là chuỗi của ClassLabel. Loại phần tử của chuỗi nằm trong thuộc tính feature của ner_feature này, và chúng ta có thể truy cập danh sách tên bằng cách xem thuộc tính names của feature đó:
label_names = ner_feature.feature.names label_names
['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC']Chúng ta đã thấy các nhãn khi đào sâu vào pipeline token-classification trong Chương 6, nhưng để cập nhật nhanh:
Onghĩa là từ không thuộc bất kì thực thể nào.B-PER/I-PERnghĩa là từ tương ứng phần bắt đầu/ nằm bên trong của thực thể person hay con người.B-ORG/I-ORGnghĩa là từ tương ứng phần bắt đầu/ nằm bên trong của thực thể organization hay tổ chức.B-LOC/I-LOCnghĩa là từ tương ứng phần bắt đầu/ nằm bên trong của thực thể location hay địa điểm.B-MISC/I-MISCnghĩa là từ tương ứng phần bắt đầu/ nằm bên trong của thực thể miscellaneous hay lộn xộn.
Giờ khi giải mã các nhãn, ta thấy chúng cho ta:
words = raw_datasets["train"][0]["tokens"]
labels = raw_datasets["train"][0]["ner_tags"]
line1 = ""
line2 = ""
for word, label in zip(words, labels):
full_label = label_names[label]
max_length = max(len(word), len(full_label))
line1 += word + " " * (max_length - len(word) + 1)
line2 += full_label + " " * (max_length - len(full_label) + 1)
print(line1)
print(line2)'EU rejects German call to boycott British lamb .'
'B-ORG O B-MISC O O O B-MISC O O'Và đối với một ví dụ trộn nhãn B- và I-, đây là những gì mà cùng một đoạn mã cung cấp cho chúng ta về phần tử của tập huấn luyện ở chỉ mục 4:
'Germany \'s representative to the European Union \'s veterinary committee Werner Zwingmann said on Wednesday consumers should buy sheepmeat from countries other than Britain until the scientific advice was clearer .'
'B-LOC O O O O B-ORG I-ORG O O O B-PER I-PER O O O O O O O O O O O B-LOC O O O O O O O'Như chúng ta có thể thấy, các thực thể bao gồm hai từ, như “European Union” và “Werner Zwingmann”, được gán nhãn B- cho từ đầu tiên và nhãn I- cho từ thứ hai.
✏️ Đến lượt bạn! In hai câu giống nhau bằng nhãn POS hoặc phân khúc của chúng.
Xử lý dữ liệu
Như thường lệ, các văn bản của chúng ta cần được chuyển đổi sang token ID trước khi mô hình có thể hiểu được chúng. Như chúng ta đã thấy trong Chương 6, một sự khác biệt lớn trong trường hợp tác vụ phân loại token là chúng ta có các đầu vào được tokenize trước. May mắn thay, API tokenizer có thể giải quyết vấn đề đó khá dễ dàng; chúng ta chỉ cần báo tokenizer bằng một lá cờ đặc biệt.
Để bắt đầu, hãy tạo đối tượng tokenizer của chúng ta. Như chúng tôi đã nói trước đây, chúng ta sẽ sử dụng mô hình huấn luyện trước BERT, vì vậy chúng ta sẽ bắt đầu bằng cách tải xuống và lưu vào bộ nhớ đệm của tokenizer liên quan:
from transformers import AutoTokenizer
model_checkpoint = "bert-base-cased"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)Bạn có thể thay thế model_checkpoint bằng bất kỳ mô hình nào khác mà bạn thích từ Hub hoặc bằng một thư mục cục bộ trong đó bạn đã lưu một mô hình được huấn luyện trước và một trình tokenize. Hạn chế duy nhất là tokenizer cần được hỗ trợ bởi thư viện 🤗 Tokenizers, vì vậy sẽ có phiên bản “nhanh”. Bạn có thể xem tất cả các kiến trúc đi kèm với phiên bản nhanh trong bảng lớn này và để kiểm tra xem đối tượng tokenizer mà bạn đang sử dụng có thực sự là được hỗ trợ bởi 🤗 Tokenizers, bạn có thể xem thuộc tính is_fast của nó:
tokenizer.is_fast
TrueĐể tokenize dữ liệu đầu vào đã tiền tokenize, ta có thể sử dụng tokenizer như thường lệ và chỉ thêm is_split_into_words=True:
inputs = tokenizer(raw_datasets["train"][0]["tokens"], is_split_into_words=True)
inputs.tokens()['[CLS]', 'EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'la', '##mb', '.', '[SEP]']Như chúng ta có thể thấy, trình tokenizer đã thêm các token đặc biệt được sử dụng bởi mô hình ([CLS] ở đầu và [SEP] ở cuối) và để nguyên hầu hết các từ. Tuy nhiên, từ lamb đã được tokenize thành hai từ phụ, la và ##mb. Điều này dẫn đến sự không khớp giữa đầu vào và các nhãn: danh sách nhãn chỉ có 9 phần tử, trong khi đầu vào của chúng ta hiện có 12 token. Việc tính toán các token đặc biệt rất dễ dàng (chúng ta biết chúng nằm ở đầu và cuối), nhưng chúng ta cũng cần đảm bảo rằng chúng ta sắp xếp tất cả các nhãn với các từ thích hợp.
May mắn thay, bởi vì chúng ta đang sử dụng một tokenizer nhanh, chúng ta có quyền truy cập vào sức mạnh siêu cường 🤗 Tokenizers, có nghĩa là chúng ta có thể dễ dàng ánh xạ từng token với từ tương ứng của nó (như đã thấy trong Chương 6):
inputs.word_ids()
[None, 0, 1, 2, 3, 4, 5, 6, 7, 7, 8, None]Với một chút công việc, sau đó chúng ta có thể mở rộng danh sách nhãn của mình để phù hợp với các token. Quy tắc đầu tiên chúng ta sẽ áp dụng là các token đặc biệt có nhãn là -100. Điều này là do theo mặc định -100 là chỉ số bị bỏ qua trong hàm mất mát mà chúng ta sẽ sử dụng (entropy chéo). Sau đó, mỗi token có cùng nhãn với token bắt đầu từ bên trong nó, vì chúng là một phần của cùng một thực thể. Đối với các token bên trong một từ nhưng không ở đầu, chúng ta thay thế B- bằng I- (vì token không bắt đầu thực thể):
def align_labels_with_tokens(labels, word_ids):
new_labels = []
current_word = None
for word_id in word_ids:
if word_id != current_word:
# Bắt đầu một từ mới!
current_word = word_id
label = -100 if word_id is None else labels[word_id]
new_labels.append(label)
elif word_id is None:
# Token đặc biệt
new_labels.append(-100)
else:
# Từ giống với token trước đó
label = labels[word_id]
# Nếu nhãn là B-XXX, ta đổi sang I-XXX
if label % 2 == 1:
label += 1
new_labels.append(label)
return new_labelsHãy cùng thử với câu đầu tiên:
labels = raw_datasets["train"][0]["ner_tags"]
word_ids = inputs.word_ids()
print(labels)
print(align_labels_with_tokens(labels, word_ids))[3, 0, 7, 0, 0, 0, 7, 0, 0]
[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]Như chúng ta có thể thấy, hàm đã thêm -100 cho hai token đặc biệt ở đầu và cuối, và dấu 0 mới cho từ của chúng ta đã được chia thành hai token.
✏️ Đến lượt bạn! Một số nhà nghiên cứu chỉ thích gán một nhãn cho mỗi từ và gán -100 cho các token con khác trong một từ nhất định. Điều này là để tránh các từ dài được chia thành nhiều token phụ góp phần lớn vào hàm mất mát. Thay đổi chức năng trước đó để căn chỉnh nhãn với ID đầu vào bằng cách tuân theo quy tắc này.
Để xử lý trước toàn bộ tập dữ liệu của mình, chúng ta cần tokenize tất cả các đầu vào và áp dụng align_labels_with_tokens() trên tất cả các nhãn. Để tận dụng tốc độ của trình tokenize nhanh của mình, tốt nhất bạn nên tokenize nhiều văn bản cùng một lúc, vì vậy chúng ta sẽ viết một hàm xử lý danh sách các ví dụ và sử dụng phương thức Dataset.map() với tùy chọn batched=True. Điều duy nhất khác với ví dụ trước là hàm word_ids() cần lấy chỉ mục của mẫu mà chúng ta muốn các ID từ khi các đầu vào cho tokenizer là danh sách văn bản (hoặc trong trường hợp của chúng ta là danh sách danh sách các từ), vì vậy chúng ta cũng thêm vào đó:
def tokenize_and_align_labels(examples):
tokenized_inputs = tokenizer(
examples["tokens"], truncation=True, is_split_into_words=True
)
all_labels = examples["ner_tags"]
new_labels = []
for i, labels in enumerate(all_labels):
word_ids = tokenized_inputs.word_ids(i)
new_labels.append(align_labels_with_tokens(labels, word_ids))
tokenized_inputs["labels"] = new_labels
return tokenized_inputsLưu ý rằng chúng ta chưa đệm vào của mình; chúng ta sẽ làm điều đó sau, khi tạo các lô bằng trình đối chiếu dữ liệu.
Bây giờ chúng ta có thể áp dụng tất cả tiền xử lý đó trong một lần vào các phần khác của tập dữ liệu của mình:
tokenized_datasets = raw_datasets.map(
tokenize_and_align_labels,
batched=True,
remove_columns=raw_datasets["train"].column_names,
)Chúng ta đã hoàn thành phần khó nhất! Bây giờ, dữ liệu đã được tiền xử lý, quá trình huấn luyện thực tế sẽ giống như những gì chúng ta đã làm trong Chương 3.
Tinh chỉnh mô hình trong API Trainer
Mã thực sử dụng Trainer sẽ giống như trước đây; những thay đổi duy nhất là cách dữ liệu được đối chiếu thành một lô và chức năng tính toán số liệu.
Đối chiếu dữ liệu
Chúng ta không thể chỉ sử dụng một DataCollatorWithPadding như trong Chương 3 vì nó chỉ đệm các đầu vào (ID đầu vào, attention mask và loại token ID). Ở đây, các nhãn của chúng ta nên được đệm theo cùng một cách giống như các đầu vào để chúng giữ nguyên kích thước, sử dụng -100 làm giá trị để các dự đoán tương ứng bị bỏ qua trong tính toán tổn thất.
Tất cả điều này được thực hiện bởi DataCollatorForTokenClassification. Giống như DataCollatorWithPadding, nó sử dụng tokenizer để xử lý trước các đầu vào:
from transformers import DataCollatorForTokenClassification
data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)Để kiểm tra nó trên vài mẫu, ta có thể gọi nó trên danh sách các mẫu từ tập huấn luyện đã được tokenize:
batch = data_collator([tokenized_datasets["train"][i] for i in range(2)])
batch["labels"]tensor([[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100],
[-100, 1, 2, -100, -100, -100, -100, -100, -100, -100, -100, -100]])Hãy so sánh điều này với các nhãn cho phần tử đầu tiên và thứ hai trong tập dữ liệu của mình:
for i in range(2):
print(tokenized_datasets["train"][i]["labels"])[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
[-100, 1, 2, -100]Như chúng ta có thể thấy, tập hợp nhãn thứ hai đã được đệm bằng độ dài của tập đầu tiên bằng cách sử dụng -100.
Thước đo
Để Trainer tính toán một thước đo cho mỗi epoch, ta sẽ cần định nghĩa hàm compute_metrics() nhận một array các dự đoán và nhãn, và trả về một từ điển với tên các thước đo và giá trị tương ứng.
Khung truyền thống được sử dụng để đánh giá phân loại token là seqeval. Để sử dụng thước đo này, ta sẽ cần cài đặt thư viện seqeval:
!pip install seqeval
Chúng ta có thể tải nó qua hàm evaluate.load() như đã làm ở Chương 3 3:
import evaluate
metric = evaluate.load("seqeval")Thước đo này không giống như các thước đo độ chính xác thông thương: nó sẽ nhận một danh sách các nhãn như là chuỗi văn bản, không phải số nguyên, nên ta sẽ cần giải mã toàn bộ những dự đoán và nhãn trước khi truyền chúng vào thước đo. Hãy cùng xem nó hoạt động ra sao. Đầu tiên, ta sẽ lấy những nhãn từ mẫu huấn luyện đầu tiên:
labels = raw_datasets["train"][0]["ner_tags"]
labels = [label_names[i] for i in labels]
labels['B-ORG', 'O', 'B-MISC', 'O', 'O', 'O', 'B-MISC', 'O', 'O']Ta có thể tạo ra những dự đoán giả cho chúng bằng cách thay đổi giá trị ở chỉ mục 2:
predictions = labels.copy()
predictions[2] = "O"
metric.compute(predictions=[predictions], references=[labels])Lưu ý rằng thước đo nhận danh sách các dự đoán (không chỉ một) và danh sách các nhãn. Đây là đầu ra:
{'MISC': {'precision': 1.0, 'recall': 0.5, 'f1': 0.67, 'number': 2},
'ORG': {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 1},
'overall_precision': 1.0,
'overall_recall': 0.67,
'overall_f1': 0.8,
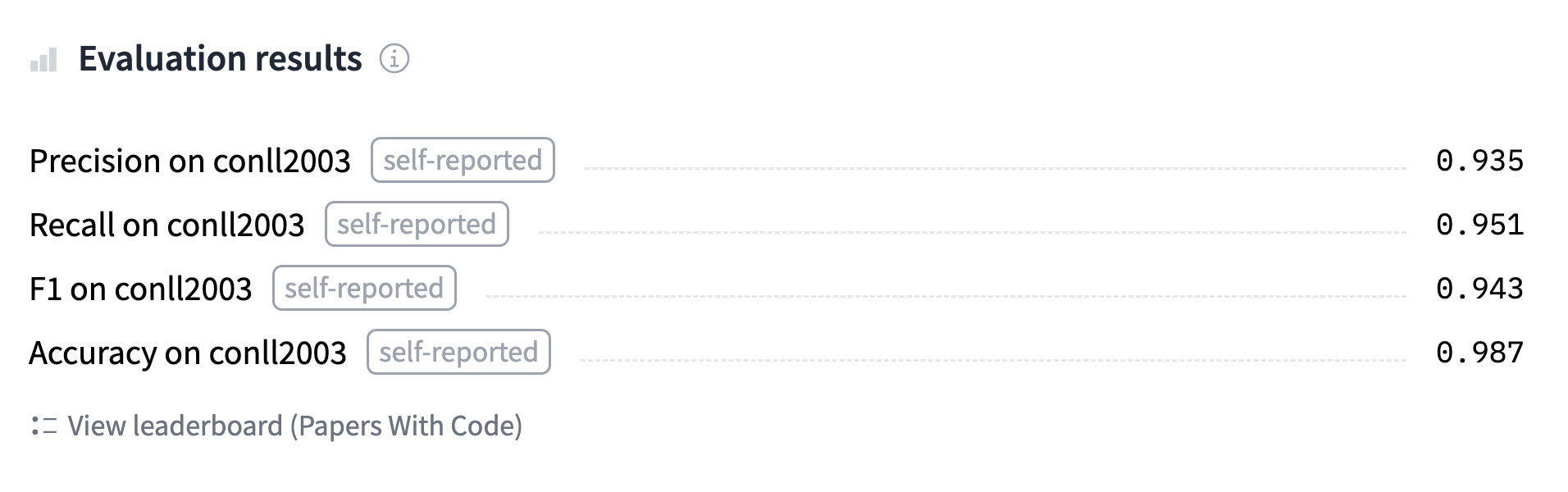
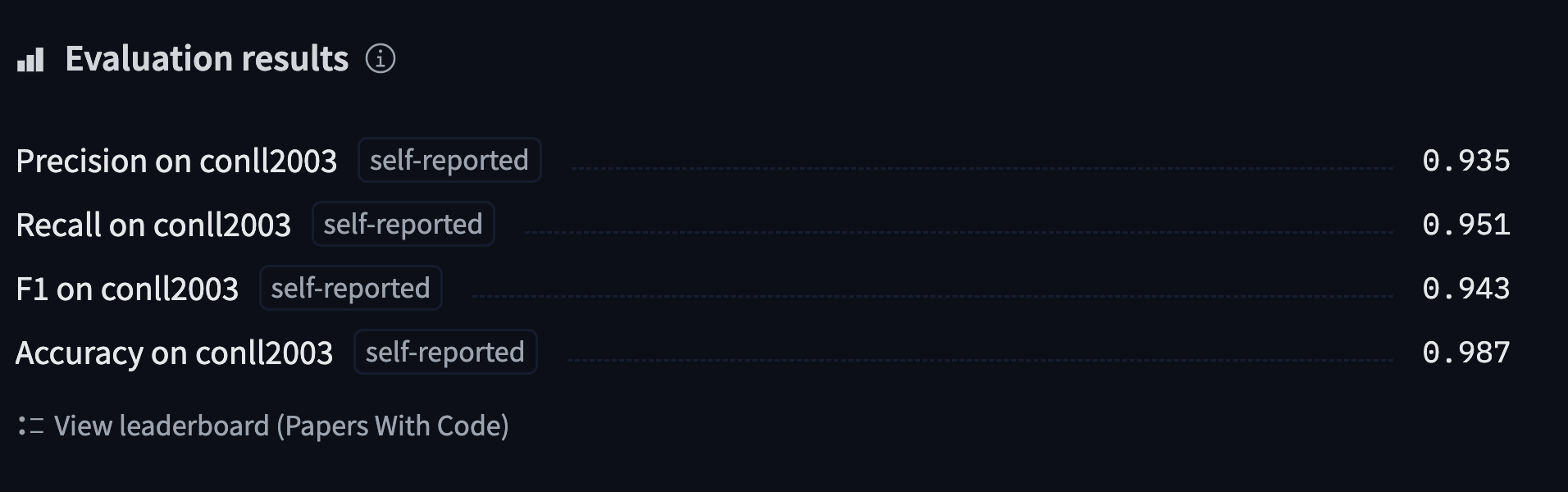
'overall_accuracy': 0.89}Điều này đang gửi lại rất nhiều thông tin! Chúng ta nhận được precision, recall, và điểm F1 cho từng thực thể riêng biệt, cũng như tổng thể. Đối với tính toán số liệu của mình, chúng ta sẽ chỉ giữ lại điểm tổng thể, nhưng hãy tinh chỉnh chức năng compute_metrics() để trả về tất cả các số liệu bạn muốn báo cáo.
Hàm compute_metrics() này trước tiên lấy argmax của logits để chuyển chúng thành các dự đoán (như thường lệ, logits và xác suất theo cùng một thứ tự, vì vậy chúng ta không cần áp dụng softmax). Sau đó, chúng ta phải chuyển đổi cả nhãn và dự đoán từ số nguyên sang chuỗi. Chúng ta xóa tất cả các giá trị có nhãn là -100, sau đó chuyển kết quả đến phương thức metric.compute():
import numpy as np
def compute_metrics(eval_preds):
logits, labels = eval_preds
predictions = np.argmax(logits, axis=-1)
# Xoá những chỉ mục bị ngó lơ (token đặc biệt) và chuyển chúng thành nhãn
true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
true_predictions = [
[label_names[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
all_metrics = metric.compute(predictions=true_predictions, references=true_labels)
return {
"precision": all_metrics["overall_precision"],
"recall": all_metrics["overall_recall"],
"f1": all_metrics["overall_f1"],
"accuracy": all_metrics["overall_accuracy"],
}Bây giờ điều này đã được thực hiện, chúng ta gần như đã sẵn sàng để xác định Trainer của mình. Chúng ta chỉ cần một model để tinh chỉnh!
Định nghĩa mô hình
Vì chúng ta đang giải quyết vấn đề phân loại token, chúng ta sẽ sử dụng lớp AutoModelForTokenClassification. Điều chính cần nhớ khi xác định mô hình này là truyền một số thông tin về số lượng nhãn mà chúng ta có. Cách dễ nhất để làm điều này là truyền vào tham số num_labels, nhưng nếu chúng ta muốn một tiện ích luận suy hoạt động giống như tiện ích chúng ta đã thấy ở đầu phần này, tốt hơn nên đặt các nhãn tương ứng chính xác thay thế.
Chúng phải được đặt bởi hai từ điển, id2label và label2id, chứa các ánh xạ từ ID đến nhãn và ngược lại:
id2label = {i: label for i, label in enumerate(label_names)}
label2id = {v: k for k, v in id2label.items()}Giờ ta có thể truyền chúng vào phương thức AutoModelForTokenClassification.from_pretrained(), và chúng sẽ được thiết lập trong cấu hình mô hình và sau đó được lưu vả tải lên Hub:
from transformers import AutoModelForTokenClassification
model = AutoModelForTokenClassification.from_pretrained(
model_checkpoint,
id2label=id2label,
label2id=label2id,
)Giống như khi chúng tôi định nghĩa AutoModelForSequenceClassification của mình trong Chương 3, việc tạo mô hình đưa ra cảnh báo rằng một số trọng số không được sử dụng (những trọng số từ đầu huấn luyện trước) và một số trọng số khác được khởi tạo ngẫu nhiên (những trọng số từ đầu phân loại token mới) và mô hình này nên được huấn luyện. Chúng ta sẽ làm điều đó sau một phút, nhưng trước tiên hãy kiểm tra kỹ xem mô hình của chúng ta có đúng số lượng nhãn hay không:
model.config.num_labels
9⚠️ Nếu bạn có mô hình với số lượng nhãn sai, bạn sẽ nhận một lỗi khó hiểu khi gọi hàm Trainer.train() sau đó (giống như “CUDA error: device-side assert triggered”). Đây là nguyên nhân số một gây ra lỗi do người dùng báo cáo về những lỗi như vậy, vì vậy hãy đảm bảo bạn thực hiện kiểm tra này để xác nhận rằng bạn có số lượng nhãn dự kiến.
Tinh chỉnh mô hình
Giờ ta đã sẵn sàng để huấn luyện mô hình của mình! Chúng ta chỉ cần làm hai điều trước khi định nghĩa Trainer: đăng nhập vào Hugging Face và định nghĩa các tham số huấn luyện. Nếu bạn đang làm việc với notebook, có một hàm thuận tiện có thể giúp bạn:
from huggingface_hub import notebook_login
notebook_login()Thao tác này sẽ hiển thị một tiện ích mà bạn có thể nhập thông tin đăng nhập Hugging Facecủa mình.
Nếu bạn không làm việc trong sổ ghi chép, chỉ cần nhập dòng sau vào thiết bị đầu cuối của bạn:
huggingface-cli login
Once this is done, we can define our TrainingArguments:
from transformers import TrainingArguments
args = TrainingArguments(
"bert-finetuned-ner",
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=2e-5,
num_train_epochs=3,
weight_decay=0.01,
push_to_hub=True,
)Bạn đã từng thấy hầu hết những điều đó trước đây: chúng ta đặt một số siêu tham số (như tốc độ học, số epoch cần luyện tập và giảm trọng lượng) và chúng ta chỉ định push_to_hub=True để chỉ ra rằng chúng ta muốn lưu mô hình và đánh giá nó vào cuối mỗi epoch và rằng chúng ta muốn tải kết quả của mình lên Model Hub. Lưu ý rằng bạn có thể chỉ định tên của kho lưu trữ mà bạn muốn đẩy đến bằng tham số hub_model_id (cụ thể là bạn sẽ phải sử dụng tham số này để đẩy đến một tổ chức). Ví dụ: khi đẩy mô hình vào tổ chức huggingface-course chúng ta đã thêm hub_model_id="huggingface-course/bert-finetuned-ner" vào TrainingArguments. Theo mặc định, kho lưu trữ được sử dụng sẽ nằm trong không gian tên của bạn và được đặt tên theo thư mục đầu ra mà bạn đã đặt, vì vậy trong trường hợp của chúng tôi, nó sẽ là "sgugger/bert-finetuned-ner".
💡 Nếu thư mục đầu ra bạn đang sử dụng đã tồn tại, nó cần phải là bản sao cục bộ của kho lưu trữ mà bạn muốn đẩy đến. Nếu không, bạn sẽ gặp lỗi khi xác định Trainer của mình và sẽ cần đặt một tên mới.
Cuối cùng, chúng ta chỉ cần truyền mọi thứ cho Trainer và bắt đầu huấn luyện:
from transformers import Trainer
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
compute_metrics=compute_metrics,
tokenizer=tokenizer,
)
trainer.train()Lưu ý rằng trong khi quá trình huấn luyện diễn ra, mỗi khi mô hình được lưu (ở đây, mỗi epoch), nó sẽ được tải lên Hub ở chế độ nền. Bằng cách này, bạn sẽ có thể tiếp tục huấn luyện của mình trên một máy khác nếu cần.
Sau khi quá trình huấn luyện hoàn tất, chúng ta sử dụng phương thức push_to_hub() để đảm bảo chúng ta tải lên phiên bản mới nhất của mô hình:
trainer.push_to_hub(commit_message="Training complete")Câu lệnh này trả về URL của cam khết nó vừa làm, nếu bạn muốn kiểm tra nó:
'https://huggingface.co/sgugger/bert-finetuned-ner/commit/26ab21e5b1568f9afeccdaed2d8715f571d786ed'Trainer cũng soạn thảo một thẻ mô hình với tất cả các kết quả đánh giá và tải nó lên. Ở giai đoạn này, bạn có thể sử dụng tiện ích luận suy trên Model Hub để kiểm tra mô hình của mình và chia sẻ với bạn bè. Bạn đã tinh chỉnh thành công một mô hình trong tác vụ phân loại token - xin chúc mừng!
Nếu bạn muốn tìm hiểu sâu hơn một chút về vòng huấn luyện, bây giờ chúng tôi sẽ hướng dẫn bạn cách thực hiện điều tương tự bằng cách sử dụng 🤗 Accelerate.
Một vòng huấn luyện tuỳ chỉnh
Bây giờ chúng ta hãy xem toàn bộ vòng lặp huấn luyện, vì vậy bạn có thể dễ dàng tùy chỉnh các phần bạn cần. Nó sẽ trông rất giống những gì chúng ta đã làm trong Chương 3, với một vài thay đổi cho phần đánh giá.
Chuẩn bị mọi thứ để huấn luyện
Đầu tiên, chúng ta cần xây dựng các DataLoader từ các tập dữ liệu của mình. Chúng ta sẽ sử dụng lại data_collator của mình dưới dạng collate_fn và xáo trộn tập huấn luyện, nhưng không phải tập kiểm định:
from torch.utils.data import DataLoader
train_dataloader = DataLoader(
tokenized_datasets["train"],
shuffle=True,
collate_fn=data_collator,
batch_size=8,
)
eval_dataloader = DataLoader(
tokenized_datasets["validation"], collate_fn=data_collator, batch_size=8
)Tiếp theo, chúng ta khôi phục mô hình của mình, để đảm bảo rằng chúng ta không tiếp tục tinh chỉnh từ trước mà bắt đầu lại từ mô hình được huấn luyện trước BERT:
model = AutoModelForTokenClassification.from_pretrained(
model_checkpoint,
id2label=id2label,
label2id=label2id,
)Sau đó, chúng tôi sẽ cần một trình tối ưu hóa. Chúng ta sẽ sử dụng AdamW cổ điển, giống như Adam, nhưng với một bản sửa lỗi trong cách áp dụng weight decay (phân rã trọng số):
from torch.optim import AdamW
optimizer = AdamW(model.parameters(), lr=2e-5)Once we have all those objects, we can send them to the accelerator.prepare() method:
from accelerate import Accelerator
accelerator = Accelerator()
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader
)🚨 Nếu bạn huấn luyện trên TPU, bạn sẽ cần chuyển tất cả các đoạn mã ở trên thành một hàm huấn luyện. Xem Chương 3 để biết thêm chi tiết.
Bây giờ, chúng ta đã gửi train_dataloader của mình tới speedrator.prepare(), chúng ta có thể sử dụng độ dài của nó để tính số bước huấn luyện. Hãy nhớ rằng chúng ta phải luôn làm điều này sau khi chuẩn bị dataloader, vì phương thức đó sẽ thay đổi độ dài của nó. Chúng ta sử dụng một lịch trình tuyến tính cổ điển từ tốc độ học đến 0:
from transformers import get_scheduler
num_train_epochs = 3
num_update_steps_per_epoch = len(train_dataloader)
num_training_steps = num_train_epochs * num_update_steps_per_epoch
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)Cuối cùng, để đẩy mô hình của chúng ta lên Hub, chúng ta sẽ cần tạo một đối tượng Repository trong một thư mục đang làm việc. Đầu tiên hãy đăng nhập vào Hugging Face, nếu bạn chưa đăng nhập. Chúng ta sẽ xác định tên kho lưu trữ từ ID mô hình mà ta muốn cung cấp cho mô hình của mình (vui lòng thay thế repo_name bằng sự lựa chọn của riêng bạn; nó chỉ cần chứa tên người dùng của bạn, đó là những gì hàm get_full_repo_name () thực hiện):
from huggingface_hub import Repository, get_full_repo_name
model_name = "bert-finetuned-ner-accelerate"
repo_name = get_full_repo_name(model_name)
repo_name'sgugger/bert-finetuned-ner-accelerate'Sau đó, ta có thể sao chép kho lưu trữ đó trong một thư mục cục bộ. Nếu nó đã tồn tại, thư mục cục bộ này phải là bản sao hiện có của kho lưu trữ mà chúng ta đang làm việc:
output_dir = "bert-finetuned-ner-accelerate"
repo = Repository(output_dir, clone_from=repo_name)Giờ ta có thể tải mọi thứ ta lưu trong output_dir bằng cách gọi phương thức repo.push_to_hub(). Điều này sẽ giúp ta tải ngay lập tức mô hình ở cuối mỗi epoch.
Vòng lặp huấn luyện
Bây giờ chúng ta đã sẵn sàng để viết vòng lặp huấn luyện đầy đủ. Để đơn giản hóa phần đánh giá của nó, chúng ta định nghĩa hàm postprocess() lấy các dự đoán và nhãn và chuyển đổi chúng thành danh sách các chuỗi, giống như đối tượng metric mong đợi:
def postprocess(predictions, labels):
predictions = predictions.detach().cpu().clone().numpy()
labels = labels.detach().cpu().clone().numpy()
# Loại bỏ các chỉ mục bị ngó lơ (các token đặc biệt) và chuyển chúng thành nhãn
true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
true_predictions = [
[label_names[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
return true_labels, true_predictionsSau đó, chúng ta có thể viết vòng lặp huấn luyện. Sau khi xác định một thanh tiến trình để theo dõi quá trình huấn luyện diễn ra như thế nào, vòng lặp có ba phần:
- Bản thân quá trình huấn luyện, là vòng lặp cổ điển trên
train_dataloader, truyền thẳng qua mô hình, sau đó truyền ngược và tối ưu hóa. - Đánh giá, trong đó có một điểm mới sau khi nhận được kết quả đầu ra của mô hình trên một lô: vì hai quy trình có thể đã độn các đầu vào và nhãn thành các hình dạng khác nhau, chúng ta cần sử dụng
accelerator.pad_across_processes()để đưa ra dự đoán và dán nhãn cho cùng một hình dạng trước khi gọi phương thứccollect(). Nếu không làm điều này, đánh giá sẽ bị lỗi hoặc bị treo vĩnh viễn. Sau đó, chúng ta gửi kết quả đếnmetric.add_batch()và gọimetric.compute()khi vòng lặp đánh giá kết thúc. - Lưu và tải lên, nơi đầu tiên chúng ta lưu mô hình và trình tokenize, sau đó gọi
repo.push_to_hub(). Lưu ý rằng chúng ta sử dụng đối sốblocks=Falseđể yêu cầu thư viện 🤗 Hub đẩy vào một quá trình không đồng bộ. Bằng cách này, quá trình huấn luyện tiếp tục diễn ra bình thường và lệnh (dài) này được thực thi ở chế độ nền.
Đây là mã hoàn chỉnh cho vòng lặp huấn luyện:
from tqdm.auto import tqdm
import torch
progress_bar = tqdm(range(num_training_steps))
for epoch in range(num_train_epochs):
# Huấn luyện
model.train()
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
# Đánh giá
model.eval()
for batch in eval_dataloader:
with torch.no_grad():
outputs = model(**batch)
predictions = outputs.logits.argmax(dim=-1)
labels = batch["labels"]
# Cần đệm các dự đoán và nhãn để tập hợp
predictions = accelerator.pad_across_processes(predictions, dim=1, pad_index=-100)
labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
predictions_gathered = accelerator.gather(predictions)
labels_gathered = accelerator.gather(labels)
true_predictions, true_labels = postprocess(predictions_gathered, labels_gathered)
metric.add_batch(predictions=true_predictions, references=true_labels)
results = metric.compute()
print(
f"epoch {epoch}:",
{
key: results[f"overall_{key}"]
for key in ["precision", "recall", "f1", "accuracy"]
},
)
# Lưu và tải
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
if accelerator.is_main_process:
tokenizer.save_pretrained(output_dir)
repo.push_to_hub(
commit_message=f"Training in progress epoch {epoch}", blocking=False
)Trong trường hợp đây là lần đầu tiên bạn thấy một mô hình được lưu bằng 🤗 Accelerate, hãy dành một chút thời gian để kiểm tra ba dòng mã đi kèm với nó:
accelerator.wait_for_everyone() unwrapped_model = accelerator.unwrap_model(model) unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
Dòng đầu tiên đã tự giải thích: nó cho tất cả các quá trình chờ cho đến khi mọi người ở giai đoạn đó trước khi tiếp tục. Điều này là để đảm bảo rằng ta có cùng một mô hình trong mọi quy trình trước khi lưu. Sau đó, chúng ta lấy unwrapped_model, là mô hình cơ sở mà ta đã xác định. Phương thức accelerator.prepare() thay đổi mô hình để hoạt động trong huấn luyện phân tán, vì vậy nó sẽ không có phương thức save_pretrained() nữa; phương thức accelerator.unwrap_model() hoàn tác bước đó. Cuối cùng, chúng ta gọi là save_pretrained() nhưng yêu cầu phương thức đó sử dụng accelerator.save() thay vì torch.save().
Khi điều này được thực hiện, bạn sẽ có một mô hình tạo ra kết quả khá giống với mô hình được huấn luyện với Trainer. Bạn có thể kiểm tra mô hình mà chúng ta đã huấn luyện bằng cách sử dụng đoạn mã này tại huggingface-course/bert-finetuned-ner-accelerate. Và nếu bạn muốn kiểm tra bất kỳ tinh chỉnh nào đối với vòng lặp huấn luyện, bạn có thể trực tiếp thực hiện chúng bằng cách chỉnh sửa đoạn mã được hiển thị ở trên!
Sử dụng mô hình đã được tinh chỉnh
Chúng tôi đã chỉ cho bạn cách bạn có thể sử dụng mô hình mà chúng ta đã tinh chỉnh trên Model Hub bằng tiện ích luận suy. Để sử dụng nó cục bộ trong một pipeline, bạn chỉ cần chỉ định mã định danh mô hình thích hợp:
from transformers import pipeline
# Thay thế nó với checkpoint của ta
model_checkpoint = "huggingface-course/bert-finetuned-ner"
token_classifier = pipeline(
"token-classification", model=model_checkpoint, aggregation_strategy="simple"
)
token_classifier("My name is Sylvain and I work at Hugging Face in Brooklyn.")[{'entity_group': 'PER', 'score': 0.9988506, 'word': 'Sylvain', 'start': 11, 'end': 18},
{'entity_group': 'ORG', 'score': 0.9647625, 'word': 'Hugging Face', 'start': 33, 'end': 45},
{'entity_group': 'LOC', 'score': 0.9986118, 'word': 'Brooklyn', 'start': 49, 'end': 57}]Tuyệt quá! Mô hình của chúng ta đang hoạt động tốt như mô hình mặc định cho pipeline này!