微调 SpeechT5
现在您已经熟悉了语音合成任务和 SpeechT5 模型的内部工作原理,该模型是在英语数据上预训练的,让我们看看如何将其微调到另一种语言。
基础准备
如果您想复现这个示例,请确保您有一个 GPU。在笔记本中,您可以使用以下命令检查:
nvidia-smi
在我们的示例中,我们将使用大约 40 小时的训练数据。如果您想使用 Google Colab 免费版的 GPU 复现,需要将训练数据量减少到大约 10-15 小时,并减少训练步骤的数量。
您还需要一些额外的依赖:
pip install transformers datasets soundfile speechbrain accelerate
最后,不要忘记登录您的 Hugging Face 账户,以便您能够上传并与社区共享您的模型:
from huggingface_hub import notebook_login
notebook_login()数据集
在这个示例中,我们将使用 VoxPopuli 数据集的荷兰语(nl)子集。
VoxPopuli 是一个大规模的多语言语音语料库,包含了 2009-2020 年欧洲议会事件的录音数据。
它包含 15 种欧洲语言的带标签的音频-转写数据。虽然我们将使用荷兰语子集,但您可以自由选择其他子集。
这是一个语音识别(ASR)数据集,所以,如前所述,它不是训练 TTS 模型的最佳选择。然而,对于这个练习来说,它已经足够好了。
让我们加载数据:
from datasets import load_dataset, Audio
dataset = load_dataset("facebook/voxpopuli", "nl", split="train")
len(dataset)输出:
20968
20968 条数据应该足以进行微调。输入 SpeechT5 的音频数据应具有 16 kHz 的采样率,所以要确保我们的数据集满足这一要求:
dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))数据预处理
处理器包含了分词器和特征提取器,我们需要用它们来预处理训练数据。所以我们先定义要使用的模型检查点,并加载对应的处理器:
from transformers import SpeechT5Processor
checkpoint = "microsoft/speecht5_tts"
processor = SpeechT5Processor.from_pretrained(checkpoint)为 SpeechT5 分词进行文本清理
首先,为了处理文本,我们需要处理器的分词器部分,所以让我们来获取它:
tokenizer = processor.tokenizer
让我们看一个示例:
dataset[0]输出:
{'audio_id': '20100210-0900-PLENARY-3-nl_20100210-09:06:43_4',
'language': 9,
'audio': {'path': '/root/.cache/huggingface/datasets/downloads/extracted/02ec6a19d5b97c03e1379250378454dbf3fa2972943504a91c7da5045aa26a89/train_part_0/20100210-0900-PLENARY-3-nl_20100210-09:06:43_4.wav',
'array': array([ 4.27246094e-04, 1.31225586e-03, 1.03759766e-03, ...,
-9.15527344e-05, 7.62939453e-04, -2.44140625e-04]),
'sampling_rate': 16000},
'raw_text': 'Dat kan naar mijn gevoel alleen met een brede meerderheid die wij samen zoeken.',
'normalized_text': 'dat kan naar mijn gevoel alleen met een brede meerderheid die wij samen zoeken.',
'gender': 'female',
'speaker_id': '1122',
'is_gold_transcript': True,
'accent': 'None'}您可能会注意到数据包含 raw_text 和 normalized_text 特征。在决定使用哪个特征作为文本输入时,需要注意的是 SpeechT5 分词器没有任何数字的词元。
在 normalized_text 中,数字被写成文本。因此,它更合适,我们应该使用 normalized_text 作为输入文本。
因为 SpeechT5 是在英语上训练的,它可能无法识别荷兰语数据集中的某些字符。如果保持原样,这些字符将被转换为 <unk> 词元。
然而,在荷兰语中,某些字符如 à 用于强调音节。为了保留文本的含义,我们可以将此字符替换为普通的 a。
要识别不支持的词元,使用 SpeechT5Tokenizer 提取数据集中所有独特字符,该分词器将字符视为词元。为此,我们将编写 extract_all_chars 映射函数,
该函数将所有数据样例的转写连接成一个字符串,然后转换为字符集。确保在 dataset.map() 中设置 batched=True 和 batch_size=-1,以便一次性获取所有转写并输入映射函数。
def extract_all_chars(batch):
all_text = " ".join(batch["normalized_text"])
vocab = list(set(all_text))
return {"vocab": [vocab], "all_text": [all_text]}
vocabs = dataset.map(
extract_all_chars,
batched=True,
batch_size=-1,
keep_in_memory=True,
remove_columns=dataset.column_names,
)
dataset_vocab = set(vocabs["vocab"][0])
tokenizer_vocab = {k for k, _ in tokenizer.get_vocab().items()}现在您有两组字符:一个来自数据集,另一个来自分词器。要识别数据集中任何不支持的字符,您可以取这两组的差集,结果将包含在数据集中而不在分词器中的字符。
dataset_vocab - tokenizer_vocab
输出:
{' ', 'à', 'ç', 'è', 'ë', 'í', 'ï', 'ö', 'ü'}为了处理上一步骤中识别的不支持字符,我们可以定义一个将这些字符映射到有效词元的函数。注意,分词器中的空格已经被替换为 ▁,因此不需要单独处理。
replacements = [
("à", "a"),
("ç", "c"),
("è", "e"),
("ë", "e"),
("í", "i"),
("ï", "i"),
("ö", "o"),
("ü", "u"),
]
def cleanup_text(inputs):
for src, dst in replacements:
inputs["normalized_text"] = inputs["normalized_text"].replace(src, dst)
return inputs
dataset = dataset.map(cleanup_text)现在我们处理好了文本中的特殊字符,是时候将注意力转移到音频数据上了。
说话人
VoxPopuli 数据集包含多个说话人的语音,但到底有多少呢?我们可以计算一下数据集中说话人的数量以及每个说话人贡献的数据量。 数据集总共有 20,968 条数据,这些信息将帮助我们更好地了解数据中的说话人和数据样例的分布。
from collections import defaultdict
speaker_counts = defaultdict(int)
for speaker_id in dataset["speaker_id"]:
speaker_counts[speaker_id] += 1通过绘制直方图,您可以了解每个说话人的数据量。
import matplotlib.pyplot as plt
plt.figure()
plt.hist(speaker_counts.values(), bins=20)
plt.ylabel("Speakers")
plt.xlabel("Examples")
plt.show()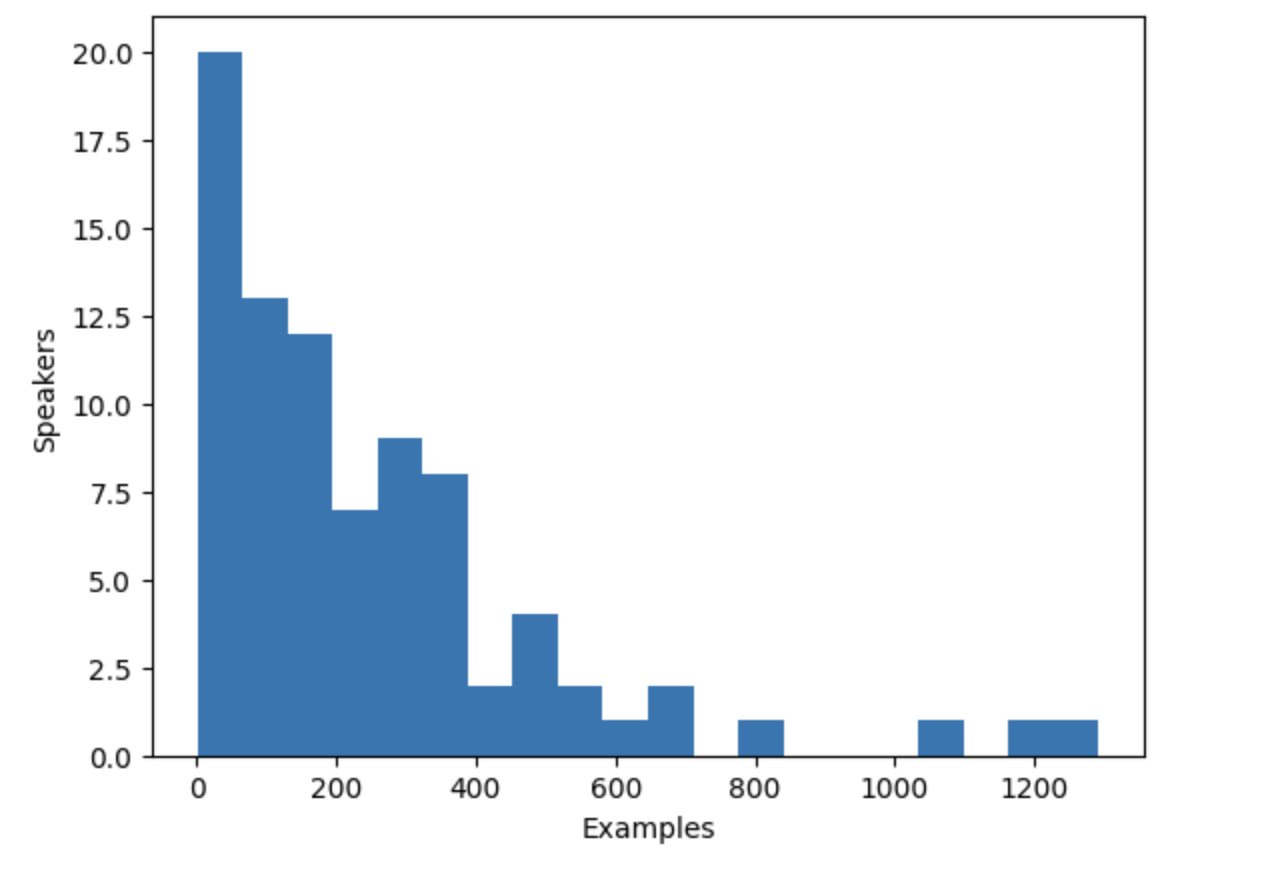
直方图显示,数据集中大约三分之一的说话人的数据少于 100 条,而大约十个说话人的数据超过 500 条。为了提高训练效率并平衡数据集,我们可以将数据限制在有 100 到 400 条数据的说话人之间。
def select_speaker(speaker_id):
return 100 <= speaker_counts[speaker_id] <= 400
dataset = dataset.filter(select_speaker, input_columns=["speaker_id"])让我们检查还剩多少个说话人:
len(set(dataset["speaker_id"]))输出:
42
让我们看看还剩多少条数据:
len(dataset)输出:
9973您留下了不到 10,000 条数据,来自大约 40 个独特的说话人,这应该足够用了。
请注意,如果某些数据很长,一些看似数据样例量较少的说话人可能有比预想的更多的音频数据。然而,确定每个说话人的总音频量需要扫描整个数据集, 这是一个耗时的过程,涉及加载和解码每个音频文件。因此,我们在这里选择跳过这一步。
说话人嵌入
为了使 TTS 模型能够区分多个说话人,您需要为每条数据创建一个说话人嵌入。说话人嵌入是模型的一个额外输入,用于描述特定说话人的声音特征。 要生成这些说话人嵌入,可以使用来自 SpeechBrain 的预训练模型 spkrec-xvect-voxceleb。
创建一个 create_speaker_embedding() 函数,该函数接受音频波形作为输入,并输出包含相应说话人嵌入的 512 维向量。
import os
import torch
from speechbrain.pretrained import EncoderClassifier
spk_model_name = "speechbrain/spkrec-xvect-voxceleb"
device = "cuda" if torch.cuda.is_available() else "cpu"
speaker_model = EncoderClassifier.from_hparams(
source=spk_model_name,
run_opts={"device": device},
savedir=os.path.join("/tmp", spk_model_name),
)
def create_speaker_embedding(waveform):
with torch.no_grad():
speaker_embeddings = speaker_model.encode_batch(torch.tensor(waveform))
speaker_embeddings = torch.nn.functional.normalize(speaker_embeddings, dim=2)
speaker_embeddings = speaker_embeddings.squeeze().cpu().numpy()
return speaker_embeddings注意,speechbrain/spkrec-xvect-voxceleb 模型是在 VoxCeleb 数据集的英语语音上训练的,而这个示例训练的是荷兰语。
虽然我们相信这个模型仍然可以为我们的荷兰语数据集生成合理的说话人嵌入,但这个假设可能不总是成立。
为了获得最佳结果,我们需要首先在目标语音上训练 X-Vector 模型。这将确保模型能够更好地捕捉荷兰语中存在的独特声音特征。如果您想训练自己的 X-向量模型, 可以参考 此脚本。
处理数据集
最后,让我们将数据处理成模型能够读入的格式。创建一个 prepare_dataset 函数,输入单个示例并使用 SpeechT5Processor 对象来对输入文本进行分词,并将目标音频加载成对数梅尔谱。它还应该额外输入说话人嵌入。
def prepare_dataset(example):
audio = example["audio"]
example = processor(
text=example["normalized_text"],
audio_target=audio["array"],
sampling_rate=audio["sampling_rate"],
return_attention_mask=False,
)
# 去掉批量处理的维度
example["labels"] = example["labels"][0]
# 用 SpeechBrain 获取 X-Vector
example["speaker_embeddings"] = create_speaker_embedding(audio["array"])
return example查看单个示例来验证处理是否正确:
processed_example = prepare_dataset(dataset[0])
list(processed_example.keys())输出:
['input_ids', 'labels', 'stop_labels', 'speaker_embeddings']说话人嵌入应该是一个 512 维向量:
processed_example["speaker_embeddings"].shape输出:
(512,)标签应该是一个有 80 个 mel 频段的对数梅尔谱。
import matplotlib.pyplot as plt
plt.figure()
plt.imshow(processed_example["labels"].T)
plt.show()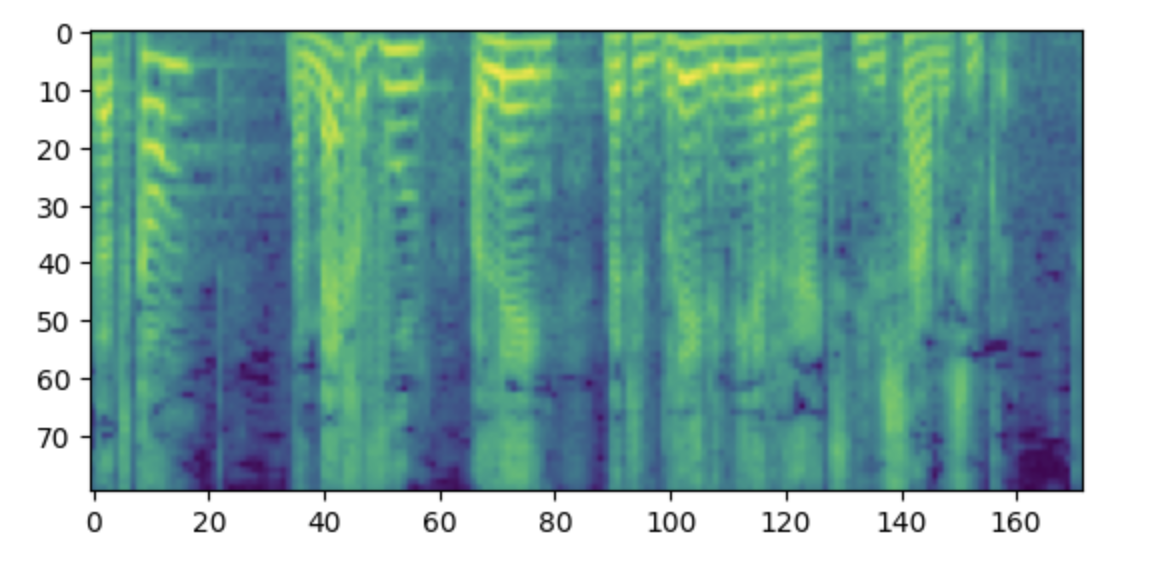
注:如果您看不明白这个频谱图,可能是因为您习惯将低频放在底部,高频放在顶部。然而,在使用 matplotlib 库将频谱图作为图像绘制时,y 轴是反过来的,频谱图看起来是倒置的。
现在我们需要将处理函数应用于整个数据集。这将花费 5 到 10 分钟的时间。
dataset = dataset.map(prepare_dataset, remove_columns=dataset.column_names)您会看到一个警告说数据集中的某些数据长于模型能够处理的最大输入长度(600 词元),得从数据集中删除这些数据。在这里,我们更进一步,为了允许更大的批量大小,删除任何超过 200 词元的内容。
def is_not_too_long(input_ids):
input_length = len(input_ids)
return input_length < 200
dataset = dataset.filter(is_not_too_long, input_columns=["input_ids"])
len(dataset)输出:
8259接下来,把数据集分成基本的训练/测试子集:
dataset = dataset.train_test_split(test_size=0.1)数据整理器
为了将多条数据组合成一个批次,您需要定义一个自定义数据整理器。这个整理器将使用填充词元填充较短的序列,确保所有示例都具有相同的长度。
对于频谱图标签,填充部分将被特殊值 -100 替换。这个特殊值指示模型在计算频谱图的损失函数时忽略那部分频谱图。
from dataclasses import dataclass
from typing import Any, Dict, List, Union
@dataclass
class TTSDataCollatorWithPadding:
processor: Any
def __call__(
self, features: List[Dict[str, Union[List[int], torch.Tensor]]]
) -> Dict[str, torch.Tensor]:
input_ids = [{"input_ids": feature["input_ids"]} for feature in features]
label_features = [{"input_values": feature["labels"]} for feature in features]
speaker_features = [feature["speaker_embeddings"] for feature in features]
# 把输入数据和生成目标整合进一个批次
batch = processor.pad(
input_ids=input_ids, labels=label_features, return_tensors="pt"
)
# 把填充词元换成 -100 来正确地忽略这一部分的损失函数
batch["labels"] = batch["labels"].masked_fill(
batch.decoder_attention_mask.unsqueeze(-1).ne(1), -100
)
# 在微调时用不上,删了
del batch["decoder_attention_mask"]
# 把目标长度下调到 reduction factor 的整数倍
if model.config.reduction_factor > 1:
target_lengths = torch.tensor(
[len(feature["input_values"]) for feature in label_features]
)
target_lengths = target_lengths.new(
[
length - length % model.config.reduction_factor
for length in target_lengths
]
)
max_length = max(target_lengths)
batch["labels"] = batch["labels"][:, :max_length]
# 加上说话人嵌入
batch["speaker_embeddings"] = torch.tensor(speaker_features)
return batch在 SpeechT5 中,模型的解码器部分的输入减少了 2 倍(reduction factor)。换句话说,它抛弃了目标序列中每两步中的一步。然后,解码器预测一个两倍长度的序列。 由于原来的目标序列长度可能是奇数,数据整理器会确保将批次的最大长度调整为 2 的倍数。
data_collator = TTSDataCollatorWithPadding(processor=processor)
训练模型
从与处理器相同的检查点加载预训练模型:
from transformers import SpeechT5ForTextToSpeech
model = SpeechT5ForTextToSpeech.from_pretrained(checkpoint)use_cache=True 选项与梯度检查点不兼容。我们在训练时禁用这个选项,并在生成时重新启用缓存以加快推理:
from functools import partial
# 在训练时禁用缓存
model.config.use_cache = False
# 设置语言和任务准备推理,并重新启用缓存
model.generate = partial(model.generate, use_cache=True)定义训练参数。这里我们在训练过程中不计算任何评估指标,我们将在本章稍后讨论评估。这里,我们先只关注损失函数:
from transformers import Seq2SeqTrainingArguments
training_args = Seq2SeqTrainingArguments(
output_dir="speecht5_finetuned_voxpopuli_nl", # 改成您选择的仓库名
per_device_train_batch_size=4,
gradient_accumulation_steps=8,
learning_rate=1e-5,
warmup_steps=500,
max_steps=4000,
gradient_checkpointing=True,
fp16=True,
evaluation_strategy="steps",
per_device_eval_batch_size=2,
save_steps=1000,
eval_steps=1000,
logging_steps=25,
report_to=["tensorboard"],
load_best_model_at_end=True,
greater_is_better=False,
label_names=["labels"],
push_to_hub=True,
)实例化 Trainer 对象并将模型、数据集和数据整理器传递给它。
from transformers import Seq2SeqTrainer
trainer = Seq2SeqTrainer(
args=training_args,
model=model,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
data_collator=data_collator,
tokenizer=processor,
)有了这个,我们就准备开始训练了!训练将花费几个小时。由于 GPU 不同,当您开始训练时,可能会遇到 CUDA 报“out-of-memory”(显存不足)的错误。这时,您可以尝试将 per_device_train_batch_size 两倍两倍地减少,并将 gradient_accumulation_steps 增加到两倍以补偿。
trainer.train()
将最终的模型上传到 🤗 Hub:
trainer.push_to_hub()
推理
一旦您微调了一个模型,您就可以使用它进行推理!从 🤗 Hub 加载模型(记得在以下代码片段中使用您的账号名):
model = SpeechT5ForTextToSpeech.from_pretrained(
"您的账号/speecht5_finetuned_voxpopuli_nl"
)选择一个示例,这里我们将从测试数据集中取一个。获取说话人嵌入。
example = dataset["test"][304]
speaker_embeddings = torch.tensor(example["speaker_embeddings"]).unsqueeze(0)定义一些输入文本并对它进行分词。
text = "hallo allemaal, ik praat nederlands. groetjes aan iedereen!"预处理输入文本:
inputs = processor(text=text, return_tensors="pt")实例化一个声码器并生成语音:
from transformers import SpeechT5HifiGan
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan")
speech = model.generate_speech(inputs["input_ids"], speaker_embeddings, vocoder=vocoder)准备好听结果了吗?
from IPython.display import Audio
Audio(speech.numpy(), rate=16000)用这个模型在新语言上获得的满意结果可能很有挑战性。说话人嵌入的质量可能是一个重要因素。由于 SpeechT5 是使用英语 X-Vector 预训练的,它在使用英语说话人嵌入时表现最佳。如果合成的语音听起来效果不好,尝试使用不同的说话人嵌入。
增加训练时长也可能提高结果的质量。但即便不继续训练,语音也显然是荷兰语而不是英语,并且它确实学到了说话人的声音特征(与示例中的原始音频相比较)。另一个可以试验的是模型的配置。例如,尝试使用 config.reduction_factor = 1 来看是否能改善结果。
在下一节中,我们将讨论如何评估语音合成模型。
< > Update on GitHub