语音合成的预训练模型
与 ASR(语音识别)和音频分类任务相比,语音合成的预训练模型检查点明显较少。在 🤗 Hub 上,您可以找到近 300 个适合的检查点。 在这些预训练模型中,我们将重点关注两种在 🤗 Transformers 库中开箱即用的架构——SpeechT5 和 Massive Multilingual Speech(MMS)。 在本节中,我们将探索如何在 Transformers 库中使用这些预训练模型进行 TTS(语音合成)。
SpeechT5
SpeechT5 是由 Microsoft 的 Junyi Ao 等人发布的模型,它能够处理一系列语音任务。虽然本单元中我们关注的是文本转语音, 但这个模型还可以用于语音转文本的任务(语音识别或说话人识别),以及语音转语音的任务(例如语音增强或变声器)。这是模型设计和预训练的方式所决定的。
SpeechT5 的核心是一个常规的 Transformer 编码器-解码器模型。就像任何其他 Transformer 一样,编码器-解码器网络使用隐藏表示来模拟序列到序列的转换。这个 Transformer 骨架对 SpeechT5 支持的所有任务都是相同的。
除此之外,SpeechT5 还有六个模态特定(语音/文本)的预处理网络(pre-nets)和后处理网络(post-nets)。输入的语音或文本(取决于任务)通过相应的预处理网络被预处理, 以获得 Transformer 可以使用的隐藏表示。然后,Transformer 的输出被送进后处理网络,转化为目标模态的输出。
以下是该模型的架构(图片来源于原始论文):
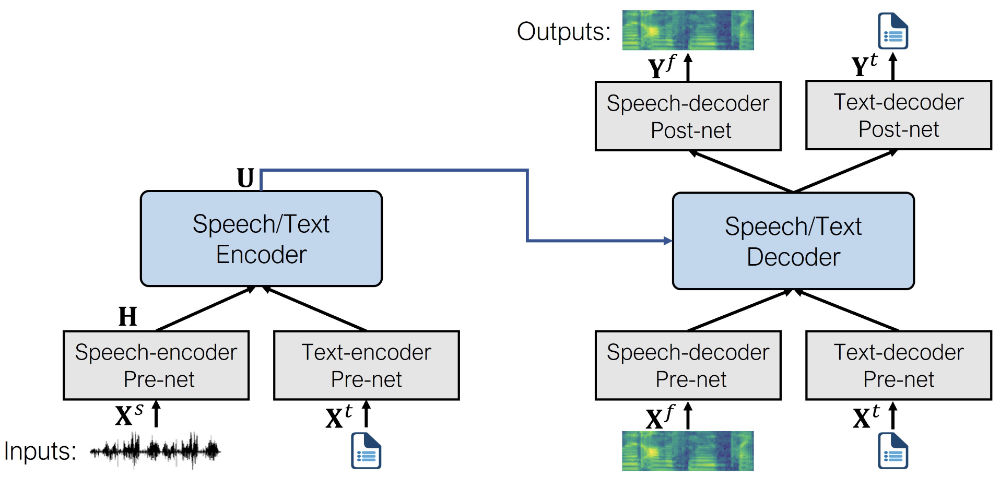
SpeechT5 首先使用大规模的未标注语音和文本数据进行预训练,以获得不同模态的统一表示。在预训练阶段,所有的预处理网络和后处理网络同时使用。
预训练之后,将整个编解码器骨架针对每个单独任务进行微调。在这个步骤中,只有与特定任务相关的预处理和后处理网络被采用。 例如,要使用 SpeechT5 进行语音合成,您需要选择文本编码器预处理网络来处理文本输入,以及语音解码器的预处理和后处理网络来处理语音输出。
这样就可以获得多个针对不同语音任务微调的模型,它们都受益于最开始在未标注数据上预训练时学到的知识。
尽管模型开始时使用的是同一个预训练模型的相同权重集,但微调后的最终版本会大不相同。所以,您不能仅仅通过更换预处理和后处理网络, 就将一个微调后的 ASR 模型转换为一个可用的 TTS 模型。SpeechT5 很灵活,但还没有灵活到这个程度 QwQ
让我们具体看看 SpeechT5 在 TTS(文本到语音)任务中使用的预/后处理网络是什么:
- 文本编码器预处理网络(Text encoder pre-net):一个文本嵌入层,将文本词元映射到编码器可以读入的隐藏表示。这与 NLP 模型(如 BERT)中的做法类似。
- 语音解码器预处理网络(Speech decoder pre-net):这个网络以对数梅尔谱(log mel spectrogram)为输入,并使用一连串的线性层来将频谱图压缩成隐藏表示。
- 语音解码器后处理网络(Speech decoder post-net):这个网络预测一个残差来添加到输出的频谱图中,用于优化模型输出的结果。
结合起来,这就是 SpeechT5 在语音合成中使用的架构:
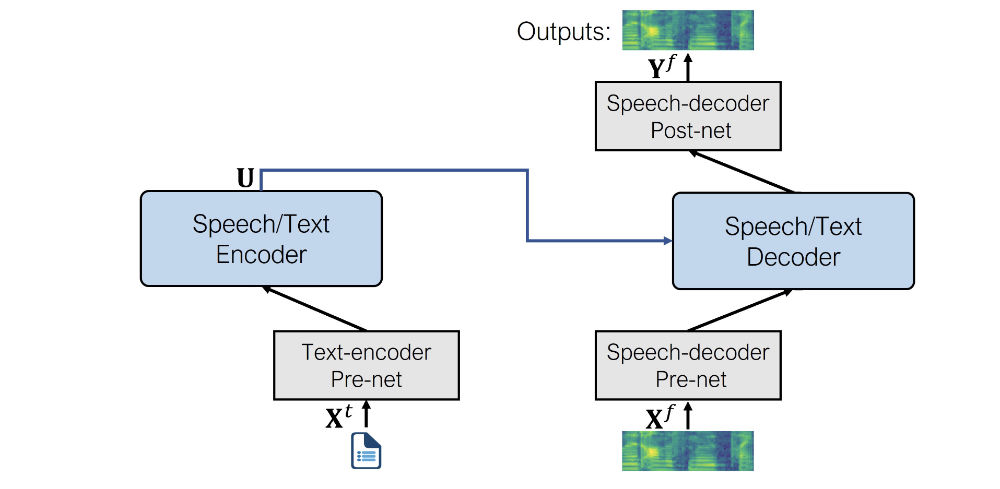
正如您所看到的,输出是一个对数梅尔谱,而不是最终的波形。如果您记得,我们在 第 3 单元 简要讨论过这个话题。 生成语音的模型的输出常常是对数梅尔谱,还需要通过一个额外的神经网络,即声码器(vocoder),才能转换成波形。
让我们看看具体应该怎么做。
首先,让我们从 🤗 Hub 加载微调过的 TTS SpeechT5 模型,以及用于分词和特征提取的处理器对象:
from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts")
model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts")接下来,给输入的文本分词。
inputs = processor(text="Don't count the days, make the days count.", return_tensors="pt")SpeechT5 TTS 模型不仅限于生成一种音色的语音。相反,它能够使用所谓的“说话人嵌入”(speaker embeddings)来模仿各种特定说话人的声音特征。
说话人嵌入(Speaker embeddings)是一个固定大小的向量,不论音频的长度如何都能用一种紧凑的方式表示说话人的身份。这些向量捕获了关于说话人的音色、口音、 语调以及其他独特特征的关键信息,这些特征区分了不同的说话人。这样的嵌入有说话人验证(speaker verification)、说话人分离(speaker diarization)、 说话人识别(speaker identification)等多种应用。生成说话人嵌入时最常用的技术包括:
- I-Vectors(身份向量):I-Vectors 基于高斯混合模型(Gaussian mixture model,GMM)。它属于无监督学习,用一个特定说话人的 GMM 的统计数据得出一个低维度、固定大小的向量来代表说话人。
- X-Vectors:X-Vectors 利用了深度神经网络(DNN),通过整合时间维度的上下文来捕获帧级的说话人信息。
X-Vectors 是 SOTA(state-of-the-art)的方法,在测试集上的表现优于 I-Vectors。 X-Vectors 是深度神经网络产生的:它被训练以区分不同说话人,并将长度不一的语音音频映射到固定维度的嵌入。您还可以加载提前计算好的 X-Vector 说话人嵌入,它封装好了某个特定说话人的说话特征。
让我们从 Hub 上的数据集中加载一个说话人嵌入。这些嵌入是使用 CMU ARCTIC 数据集 和 这个脚本 获得的,这里使用任何 X-Vector 嵌入都可以。
from datasets import load_dataset
embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
import torch
speaker_embeddings = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0)说话人嵌入是形状为 (1, 512) 的张量,我们选的这个说话人嵌入描述的是一个女声。
此时,我们已经有足够的输入来生成对数梅尔谱作为输出,您可以这样做:
spectrogram = model.generate_speech(inputs["input_ids"], speaker_embeddings)这会输出一个形状为 (140, 80) 的张量,包含对数梅尔谱。第一维是序列长度,可能每次运行代码它的取值都会不一样, 因为语音解码器预处理网络(pre-net)总是对输入序列用 dropout。这给生成的语音添加了一些随机变化。
如果我们想生成语音波形,我们还需要指定一个用于把频谱图转换为波形的声码器(vocoder)。理论上,您可以使用任何适用于 80-bin 梅尔谱的声码器。 🤗 Transformers 提供了一个基于 HiFi-GAN 的声码器,可以很方便地使用。其权重由 SpeechT5 的原作者友情提供。
HiFi-GAN 是一种用于高保真语音合成的 SOTA 生成对抗网络(GAN)。它能够根据输入的频谱图生成高品质且逼真的音频波形。
总的来说,HiFi-GAN 由一个生成器和两个鉴别器组成。生成器是一个全卷积神经网络,它以梅尔谱作为输入并学习产生原始音频波形。 鉴别器负责区分真实音频和生成音频。这两个鉴别器关注音频的不同方面。
HiFi-GAN 在大量高品质音频数据上进行训练。它采用所谓的对抗训练,其中生成器和鉴别器网络相互竞争。最初,生成器产生的音频质量较低, 鉴别器可以轻松地将其与真实音频区分开。随着训练的进行,生成器改进其输出,目标是欺骗鉴别器。反过来,鉴别器也学会更准确地区分真实和生成的音频。 这种对抗性反馈循环帮助两个网络随时间推移提升性能。最终,HiFi-GAN 学会生成高保真音频,精密地模仿训练数据的特征。
加载声码器就像加载任何其他 🤗 Transformers 模型一样简单。
from transformers import SpeechT5HifiGan
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan")现在您需要做的就是在生成语音时将其作为参数传递,输出将自动转换为语音波形。
speech = model.generate_speech(inputs["input_ids"], speaker_embeddings, vocoder=vocoder)让我们来听听输出的结果。SpeechT5 使用的采样率始终是 16 kHz。
from IPython.display import Audio
Audio(speech, rate=16000)真不错!
请随意使用 SpeechT5 语音合成 demo 探索其他声音,尝试各种各样的输入。请注意,该预训练检查点仅支持英语:
Bark
Bark 是 Suno AI 提出的基于 transformer 的语音合成模型,见 suno-ai/bark。
与 SpeechT5 不同,Bark 直接生成语音波形,无需在推理过程中使用单独的声码器——它已经集成了这一功能。这种功能是通过使用 Encodec 实现的,它既是编解码器也是压缩工具。
借助 Encodec,您可以将音频压缩成轻量级格式以减少内存使用,然后再解压缩以恢复原始音频。这个压缩过程由 8 个 codebook 帮助完成,
每个 codebook 都由整数向量组成。可以将这些 codebook 视为音频的整数形式表示或嵌入,并且每个后续的 codebook 都能在前一个的基础上提高音频重建的质量。
由于 codebook 是整数向量,它们可以被 transformer 模型学习,而 transformer 在这项任务上非常高效。这正是 Bark 被训练去做的任务。
更具体地说,Bark 由 4 个主要的模型组成:
BarkSemanticModel(也称为“文本”模型):一个因果自回归的 transformer 模型,它接收分词后的文本作为输入,并预测表示文本含义的语义文本词元。BarkCoarseModel(也称为“粗粒度声学”模型):一个因果自回归的 transformer,它接收BarkSemanticModel模型的结果作为输入,预测 EnCodec 所需的前两个音频 codebook 。BarkFineModel(“细粒度声学”模型),这次是一个非因果自编码 transformer,它基于之前生成的所有 codebook 嵌入,迭代地预测下一个 codebook 。- 在
EncodecModel预测了所有 codebook 通道后,Bark 使用它来解码输出音频数组。
需要注意的是,前三个模块中的每一个都支持说话人嵌入作为条件参数,以根据预特定的预设调整输出的声音。
Bark 是一个高度可控的语音合成模型,意味着您可以调整各种各样的设置,下面我们将见证这一功能。
在一切开始之前,我们需要加载模型及其处理器。
处理器在这里有两方面的作用:
- 它用于对输入文本进行分词,即将其切割成模型可以理解的小片段。
- 它存储说话人嵌入,即可以调节生成结果的声音预设。
from transformers import BarkModel, BarkProcessor
model = BarkModel.from_pretrained("suno/bark-small")
processor = BarkProcessor.from_pretrained("suno/bark-small")Bark 非常多功能,可以通过处理器加载一个 说话人嵌入库 中的说话人嵌入来调节它产生的声音。
# 设置说话人嵌入
inputs = processor("This is a test!", voice_preset="v2/en_speaker_3")
speech_output = model.generate(**inputs).cpu().numpy()它还可以生成随时可用的多语言语音,例如法语和中文。您可以在 这里 找到支持的语言列表。与下面讨论的 MMS 不同,它不需要指定所使用的语言,只需将输入文本调整为相应的语言即可。
# 试试法语,同时我们也来用一个法语说话人嵌入
inputs = processor("C'est un test!", voice_preset="v2/fr_speaker_1")
speech_output = model.generate(**inputs).cpu().numpy()该模型还可以生成非语言交流,例如笑、叹息和哭泣。 您只需使用相应的提示修改输入文本,例如 [clears throat]、[laughter] 或 ...。
inputs = processor(
"[clears throat] This is a test ... and I just took a long pause.",
voice_preset="v2/fr_speaker_1",
)
speech_output = model.generate(**inputs).cpu().numpy()Bark 甚至可以产生音乐。您可以通过在单词周围添加 ♪ 音符 ♪ 来做到这一点。
inputs = processor(
"♪ In the mighty jungle, I'm trying to generate barks.",
)
speech_output = model.generate(**inputs).cpu().numpy()除了所有这些功能之外,Bark 还支持批处理,这意味着您可以同时处理多个文本条目,但代价是更密集的计算。在某些硬件(例如 GPU)上,批处理可以加快整体生成速度,这意味着一次性生成所有样本比逐个生成样本更快。
让我们尝试生成一些示例:
input_list = [
"[clears throat] Hello uh ..., my dog is cute [laughter]",
"Let's try generating speech, with Bark, a text-to-speech model",
"♪ In the jungle, the mighty jungle, the lion barks tonight ♪",
]
# 设置一个说话人嵌入
inputs = processor(input_list, voice_preset="v2/en_speaker_3")
speech_output = model.generate(**inputs).cpu().numpy()让我们来一个一个听这些输出。
第一个:
from IPython.display import Audio
sampling_rate = model.generation_config.sample_rate
Audio(speech_output[0], rate=sampling_rate)第二个:
Audio(speech_output[1], rate=sampling_rate)第三个:
Audio(speech_output[2], rate=sampling_rate)Bark 与其他 🤗 Transformers 模型一样,只需几行代码即可针对速度和内存影响进行优化。要了解具体操作方法,请单击 此 colab 演示笔记本。
Massive Multilingual Speech (MMS)
如果您需要一个非英语的预训练模型怎么办?Massive Multilingual Speech(MMS,大规模多语种语音)是另一个涵盖多种语音任务的模型,并且,它支持大量的语言。比方说,它可以合成超过 1,100 种语言的语音。
MMS 的语音合成是基于 VITS Kim et al., 2021 的,它是最先进的 TTS 方法之一。
VITS 是一个语音生成网络,可以将文本转换成语音波形。它的工作方式类似于条件变分自编码器(conditional variational auto-encoder),从输入文本估计音频特征。首先,生成用频谱图表示的声学特征。 然后,使用改编自 HiFi-GAN 的转置卷积层解码出波形。在推理过程中,文本编码被上采样并使用流模块(flow module)和 HiFi-GAN 解码器转换成波形。像 Bark 一样,这里不需要声码器(vocoder),因为已经直接生成波形了。
MMS 模型最近才被添加到 🤗 Transformers 中,所以您需要从源代码安装该库:
pip install git+https://github.com/huggingface/transformers.git
让我们试用一下 MMS,看看如何合成非英语的语音,例如德语。首先,我们将加载特定语言的检查点和分词器:
from transformers import VitsModel, VitsTokenizer
model = VitsModel.from_pretrained("facebook/mms-tts-deu")
tokenizer = VitsTokenizer.from_pretrained("facebook/mms-tts-deu")您可能会注意到,加载 MMS 模型需要使用 VitsModel 和 VitsTokenizer。这是因为如前所述,MMS 的 TTS 是基于 VITS 模型的。
让我们选择一首德语儿歌的前两句作为示例文本:
text_example = (
"Ich bin Schnappi das kleine Krokodil, komm aus Ägypten das liegt direkt am Nil."
)要生成波形输出,使用分词器预处理文本,并将其传递给模型:
import torch
inputs = tokenizer(text_example, return_tensors="pt")
input_ids = inputs["input_ids"]
with torch.no_grad():
outputs = model(input_ids)
speech = outputs["waveform"]让我们来听听:
from IPython.display import Audio
Audio(speech, rate=16000)Wunderbar!如果您想尝试其他语言的 MMS,可以 在 🤗 Hub 上 寻找其他合适的 vits 检查点。
现在,让我们看看如何自己微调一个 TTS 模型!
< > Update on GitHub