Загрузка и изучение аудио набора данных
В этом курсе мы будем использовать библиотеку 🤗 Datasets для работы с наборами аудиоданных. 🤗 Datasets - это библиотека с открытым исходным кодом для загрузки и подготовки наборов данных всех модальностей, включая аудио. Библиотека предоставляет легкий доступ к беспрецедентному подборке наборов данных машинного обучения, публично доступных на Hugging Face Hub. Кроме того, 🤗 Datasets содержит множество функций, предназначенных для работы с аудиоданными, которые упрощают работу с ними как для исследователей, так и для практиков.
Для начала работы с наборами аудиоданных необходимо убедиться, что у вас установлена библиотека 🤗 Datasets:
pip install datasets[audio]
Одной из ключевых особенностей 🤗 Datasets является возможность загрузки и подготовки набора данных всего одной строкой
Python-кода с помощью функции load_dataset().
Давайте загрузим и исследуем набор аудиоданных под названием MINDS-14, который содержит записи людей, задающих вопросы системе дистанционного банковского обслуживания на нескольких языках и диалектах.
Для загрузки набора данных MINDS-14 нам необходимо скопировать идентификатор набора данных на хабе (PolyAI/minds14) и передать его
в функцию load_dataset. Мы также укажем, что нас интересует только австралийское подмножество (en-AU)
данных, и ограничим его частью набора данных предназначенной для обучения:
from datasets import load_dataset
minds = load_dataset("PolyAI/minds14", name="en-AU", split="train")
mindsOutput:
Dataset(
{
features: [
"path",
"audio",
"transcription",
"english_transcription",
"intent_class",
"lang_id",
],
num_rows: 654,
}
)Набор содержит 654 аудиофайла, каждый из которых сопровождается транскрипцией, переводом на английский язык и меткой, указывающей на намерение человека, сделавшего запрос. В столбце audio содержатся необработанные аудиоданные. Рассмотрим подробнее на одном из примеров:
example = minds[0]
exampleOutput:
{
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"audio": {
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"array": array(
[0.0, 0.00024414, -0.00024414, ..., -0.00024414, 0.00024414, 0.0012207],
dtype=float32,
),
"sampling_rate": 8000,
},
"transcription": "I would like to pay my electricity bill using my card can you please assist",
"english_transcription": "I would like to pay my electricity bill using my card can you please assist",
"intent_class": 13,
"lang_id": 2,
}Вы можете заметить, что столбец аудио содержит несколько параметров. Вот что они собой представляют:
path: путь к аудиофайлу (в данном случае*.wav).array: Декодированные аудиоданные, представленные в виде одномерного массива NumPy.sampling_rate. Частота дискретизации аудиофайла (в данном примере 8 000 Гц).
Класс intent_class - это классификационная категория аудиозаписи. Для преобразования этого числа в осмысленную строку
можно использовать метод int2str():
id2label = minds.features["intent_class"].int2str
id2label(example["intent_class"])Output:
"pay_bill"Если посмотреть на транскрипцию, то можно увидеть, что в аудиофайле действительно записан человек, задающий вопрос об оплате счета.
Если вы планируете обучать аудиоклассификатор на этом подмножестве данных, то, возможно, вам не обязательно понадобятся все признаки. Например,
lang_id будет иметь одно и то же значение для всех примеров и не будет полезен. Параметр english_transcription, скорее всего, будет
дублировать transcription в этом подмножестве, поэтому их можно смело удалить.
Удалить нерелевантные признаки можно с помощью метода 🤗 Datasets remove_columns:
columns_to_remove = ["lang_id", "english_transcription"]
minds = minds.remove_columns(columns_to_remove)
mindsOutput:
Dataset({features: ["path", "audio", "transcription", "intent_class"], num_rows: 654})Теперь, когда мы загрузили и осмотрели необработанное содержимое набора данных, давайте прослушаем несколько примеров! Мы воспользуемся функциями Blocks
и Audio из Gradio для декодирования нескольких случайных образцов из набора данных:
import gradio as gr
def generate_audio():
example = minds.shuffle()[0]
audio = example["audio"]
return (
audio["sampling_rate"],
audio["array"],
), id2label(example["intent_class"])
with gr.Blocks() as demo:
with gr.Column():
for _ in range(4):
audio, label = generate_audio()
output = gr.Audio(audio, label=label)
demo.launch(debug=True)При желании можно также визуализировать некоторые примеры. Построим форму волны для первого примера.
import librosa
import matplotlib.pyplot as plt
import librosa.display
array = example["audio"]["array"]
sampling_rate = example["audio"]["sampling_rate"]
plt.figure().set_figwidth(12)
librosa.display.waveshow(array, sr=sampling_rate)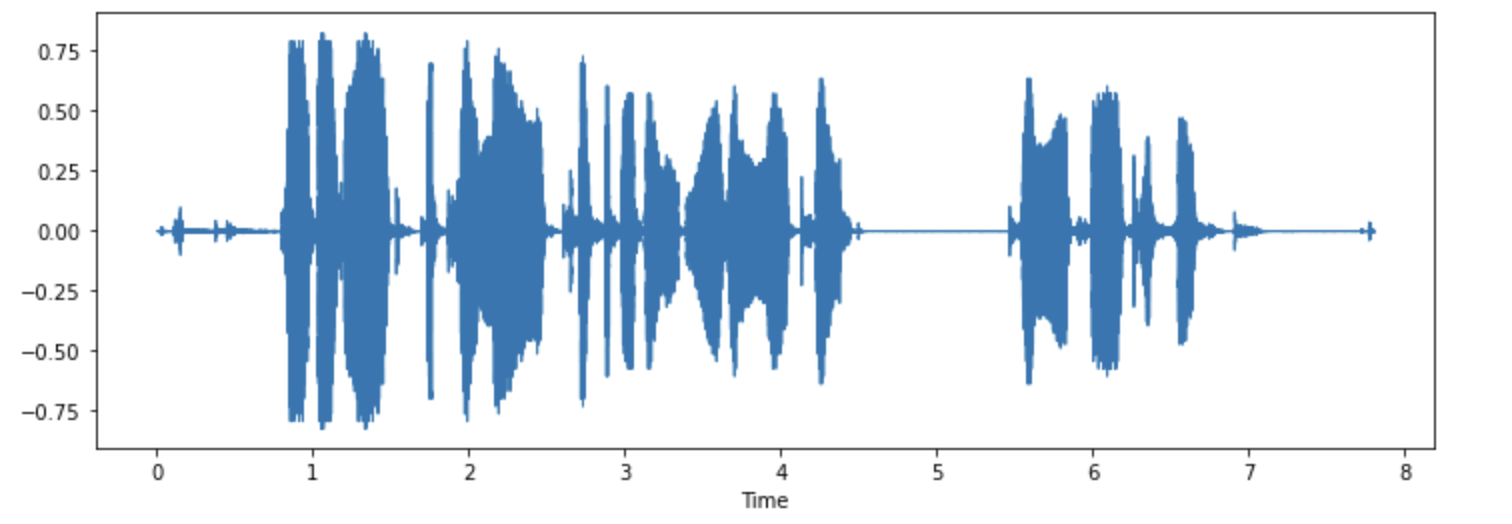
Попробуйте! Загрузите другой диалект или язык из набора данных MINDS-14, прослушайте и визуализируйте несколько примеров, чтобы получить представление о вариативности всего набора данных. Полный список доступных языков можно найти здесь.
< > Update on GitHub