Введение в аудиоданные
По своей природе звуковая волна является непрерывным сигналом, то есть содержит бесконечное число значений сигнала за определенное время. Это создает проблемы для цифровых устройств, которые ожидают конечные массивы. Для обработки, хранения и передачи сигнала цифровыми устройствами, непрерывная звуковая волна должна быть преобразована в ряд дискретных значений, называемых цифровым представлением.
Если обратиться к любому набору аудиоданных, то можно найти цифровые файлы со звуковыми фрагментами, например, с текстовым повествованием или музыкой.
Вы можете встретить различные форматы файлов, такие как .wav (Waveform Audio File), .flac (Free Lossless Audio Codec),
.mp3 (MPEG-1 Audio Layer 3). Эти форматы различаются главным образом способом сжатия цифрового представления аудиосигнала.
Рассмотрим, как мы приходим от непрерывного сигнала к такому представлению. Сначала аналоговый сигнал улавливается микрофоном, который преобразует звуковые волны в электрический сигнал. Затем электрический сигнал оцифровывается с помощью Аналого-Цифрового Преобразователя для получения цифрового представления путем дискретизации.
Выборка и частота дискретизации
Выборка (сэмлирование, дискретизация) - это процесс измерения значения непрерывного сигнала с фиксированным шагом по времени. Выборочная форма сигнала является дискретной, поскольку содержит конечное число значений сигнала через равномерные интервалы времени.
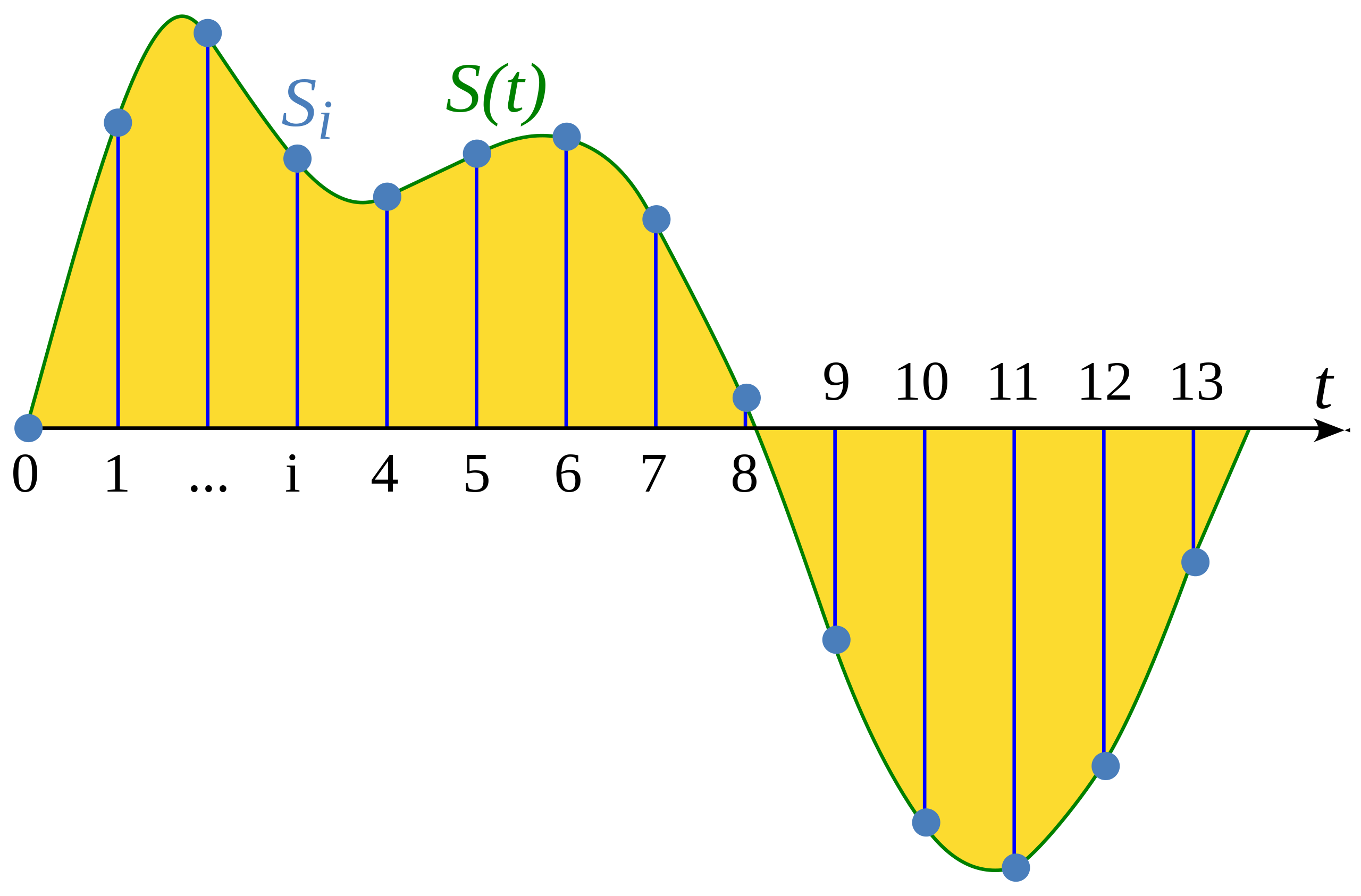
Иллюстрация из статьи Википедии: Сэмплирование (обработка сигналов)
Частота выборки (сэмплирования) (также называемая частотой дискретизации) - это количество выборок, сделанных за одну секунд измеряемое в герцах (Гц). Чтобы дать вам примерную точку отсчета, частота дискретизации аудиофайлов CD-качества составляет 44 100 Гц, то есть выборки делаются 44 100 раз в секунду. Для сравнения, частота дискретизации звука высокого разрешения составляет 192 000 Гц или 192 кГц. Обычно частота дискретизации, используемая при обучении речевых моделей, составляет 16 000 Гц или 16 кГц.
Выбор частоты дискретизации в первую очередь определяет наивысшую частоту, которая может быть извлечена из сигнала. Это значение также, известно как предел Найквиста, и составляет ровно половину частоты дискретизации. Слышимые частоты в человеческой речи лежат ниже 8 кГц, поэтому для дискретизации речи достаточно 16 кГц. Использование более высокой частоты дискретизации не позволяет получить больше информации и только приведет к увеличению вычислительных затрат на обработку таких файлов. С другой стороны, дискретизация звука при слишком низкой частоте дискретизации приводит к потере информации. Речь, дискретизированная с частотой 8 кГц, будет звучать приглушенно, так как более высокие частоты не могут быть захвачены при такой частоте дискретизации.
При работе над любой аудио задачей важно убедиться, что все примеры звука в вашем наборе данных имеют одинаковую частоту дискретизации. Если вы планируете использовать пользовательские аудиоданные для дообучения предварительно обученной модели, то частота дискретизации ваших данных должна соответствовать частоте дискретизации данных, на которых была предварительно обучена модель. Частота дискретизации определяет временной интервал между последовательными выборками звука, что влияет на временное разрешение аудиоданных. Рассмотрим пример: 5-секундный звук при частоте дискретизации 16 000 Гц будет представлен в виде серии из 80 000 значений, а тот же 5-секундный звук при частоте дискретизации 8 000 Гц будет представлен в виде серии из 40 000 значений. Модели трансформеров, решающие аудиозадачи, рассматривают примеры как последовательности и полагаются на механизмы внимания для обучения аудио или мультимодальному представлению. Поскольку последовательности данных различны для аудиопримеров с разной частотой дискретизации, то моделям будет сложно обобщать данные для разных частот дискретизации. Передискретизация - это процесс согласования частот дискретизации, являющийся частью препроцессинга аудиоданных.
Амплитуда и битовая глубина
В то время как частота дискретизации говорит о том, как часто происходит выборка образцов, какие именно значения содержатся в каждом образце?
Звук возникает в результате изменения давления воздуха на частотах, слышимых человеком. Амплитуда звука характеризует уровень звукового давления в любой момент времени и измеряется в децибелах (дБ). Мы воспринимаем амплитуду как громкость. Для примера, обычный разговор не превышает 60 дБ, а рок-концерт может достигать 125 дБ, что является пределом для человеческого слуха.
В цифровом аудио каждый образец звука фиксирует амплитуду звуковой волны в определенный момент времени. Битовая глубина образца звука определяет, с какой точностью может быть описано это значение амплитуды. Чем выше битовая глубина, тем точнее цифровое представление приближается к исходной непрерывной звуковой волне.
Наиболее распространенные битовые глубины звука - 16 и 24 бита. Каждая из них представляет собой двоичный термин, обозначающий количество возможных шагов, на которое можно квантовать амплитудное значение при его преобразовании из непрерывного в дискретное: 65 536 шагов для 16-битного звука, для 24-битного звука - 16 777 216 шагов. Поскольку при квантовании происходит округление непрерывного значения до дискретного, процесс дискретизации вносит шум. Чем выше битовая глубина, тем меньше этот шум квантования. На практике шум квантования 16-битного звука уже достаточно мал, чтобы быть неслышимым, и использование большей битовой глубины обычно не требуется.
Вы также можете встретить 32-битные аудио. В нем выборки хранятся в виде значений с плавающей точкой, тогда как в 16- и 24-битном аудио используются целочисленные выборки. Точность 32-битного значения с плавающей точкой составляет 24 бита, что дает такую же битовую глубину, как и у 24-битного звука. Предполагается, что аудио выборки с плавающей точкой лежат в диапазоне [-1,0, 1,0]. Поскольку модели машинного обучения естественным образом работают с данными в формате с плавающей точкой, перед тем как использовать их для обучения модели, аудиоданные необходимо преобразовать в формат с плавающей точкой. Как это сделать, мы рассмотрим в следующем разделе Препроцессинг.
Как и в случае с непрерывными звуковыми сигналами, амплитуда цифрового звука обычно выражается в децибелах (дБ). Поскольку слух человека имеет логарифмическую природу - наши уши более чувствительны к небольшим колебаниям тихих звуков, чем громких, то громкость звука легче интерпретировать, если амплитуды выражены в децибелах, которые также являются логарифмическими. Децибельная шкала для реального звука начинается с 0 дБ, что соответствует самому тихому звуку, который может услышать человек, а более громкие звуки имеют большие значения. Однако для цифровых аудиосигналов 0 дБ - это самая громкая возможная амплитуда, а все остальные амплитуды отрицательны. Краткое эмпирическое правило: каждые -6 дБ - это уменьшение амплитуды вдвое, и все, что ниже -60 дБ обычно неслышно, если только вы не увеличите громкость.
Аудио как форма волны
Возможно, вам приходилось видеть визуализацию звуков в виде формы волны, которая отображает значения отсчетов во времени и иллюстрирует изменения амплитуды звука. Такое представление звука называется временной областью.
Этот тип визуализации полезен для выявления специфических особенностей аудиосигнала, таких как время появления отдельных звуковых событий, общая громкость сигнала, неравномерности или шумы, присутствующие в аудиосигнале.
Для построения графика формы волны аудиосигнала можно использовать библиотеку Python librosa:
pip install librosa
Возьмем для примера звук “Трубы”, который поставляется вместе с библиотекой::
import librosa
array, sampling_rate = librosa.load(librosa.ex("trumpet"))Пример загружается в виде кортежа состоящего из временного ряда звука (здесь мы называем его array), и частоты дискретизации (sampling_rate).
Посмотрим на форму волны этого звука с помощью функции librosa waveshow():
import matplotlib.pyplot as plt
import librosa.display
plt.figure().set_figwidth(12)
librosa.display.waveshow(array, sr=sampling_rate)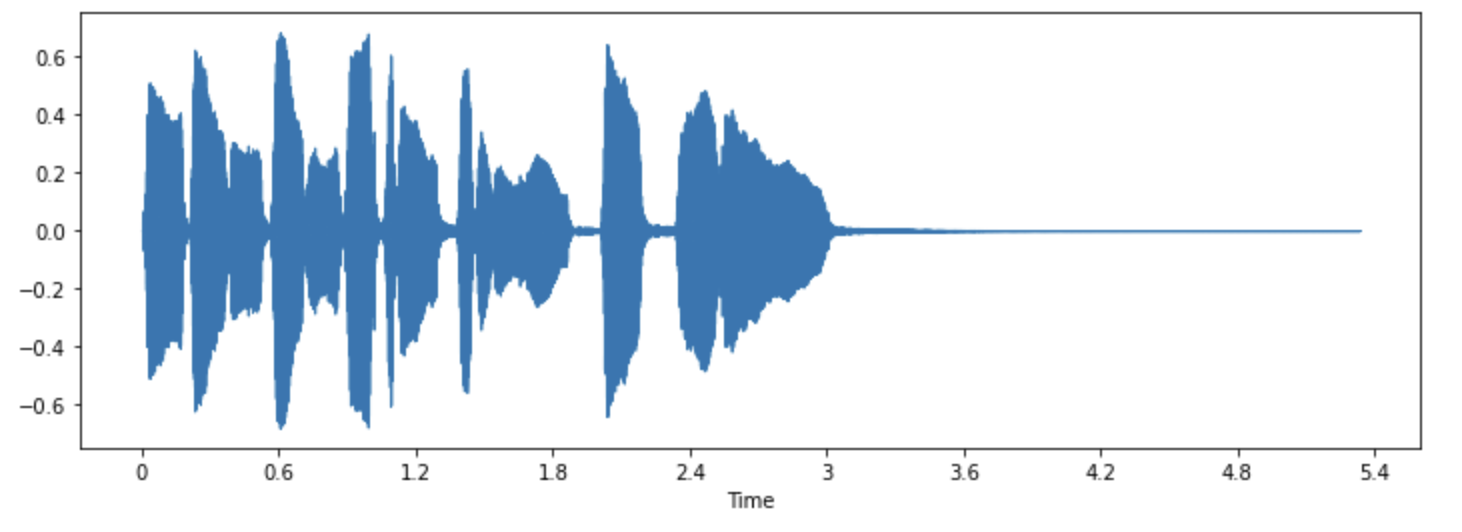
При этом по оси y откладывается амплитуда сигнала, а по оси x - время. Другими словами, каждая точка соответствует одному значению выборки, которое было взято при сэмплировании этого звука. Также отметим, что librosa возвращает звук уже в виде значений с плавающей точкой, при этом значения амплитуды действительно находятся в диапазоне [-1.0, 1.0].
Визуализация звука наряду с его прослушиванием может быть полезным инструментом для понимания данных, с которыми вы работаете. Вы можете увидеть форму сигнала, заметить закономерности, научиться выявлять шумы или искажения. При предварительной обработке данных, например, нормализации, повторной выборке или фильтрации, можно визуально убедиться в том, что этапы предварительной обработки были выполнены как ожидалось. После обучения модели можно также визуализировать примеры, в которых возникают ошибки (например, в задаче классификации звука), для отладки возникающих проблем.
Частотный спектр
Другим способом визуализации аудиоданных является построение частотного спектра аудиосигнала, также известное как частотный интервал. Спектр вычисляется с помощью Дискретного Преобразования Фурье или ДПФ (Discrete Fourier Transform - DFT). Он описывает отдельные частоты, из которых состоит сигнал, и их силу.
Построим частотный спектр для того же звука трубы, взяв ДПФ с помощью функции numpy rfft(). Хотя
можно построить спектр всего звука, удобнее рассматривать небольшую область. Здесь мы возьмем
ДПФ первых 4096 выборок, что приблизительно равно длительности первой сыгранной ноты:
import numpy as np
dft_input = array[:4096]
# Рассчитаем ДПФ
window = np.hanning(len(dft_input))
windowed_input = dft_input * window
dft = np.fft.rfft(windowed_input)
# получим амплитудный спектр в децибелах
amplitude = np.abs(dft)
amplitude_db = librosa.amplitude_to_db(amplitude, ref=np.max)
# получим частотные столбцы
frequency = librosa.fft_frequencies(sr=sampling_rate, n_fft=len(dft_input))
plt.figure().set_figwidth(12)
plt.plot(frequency, amplitude_db)
plt.xlabel("Frequency (Hz)")
plt.ylabel("Amplitude (dB)")
plt.xscale("log")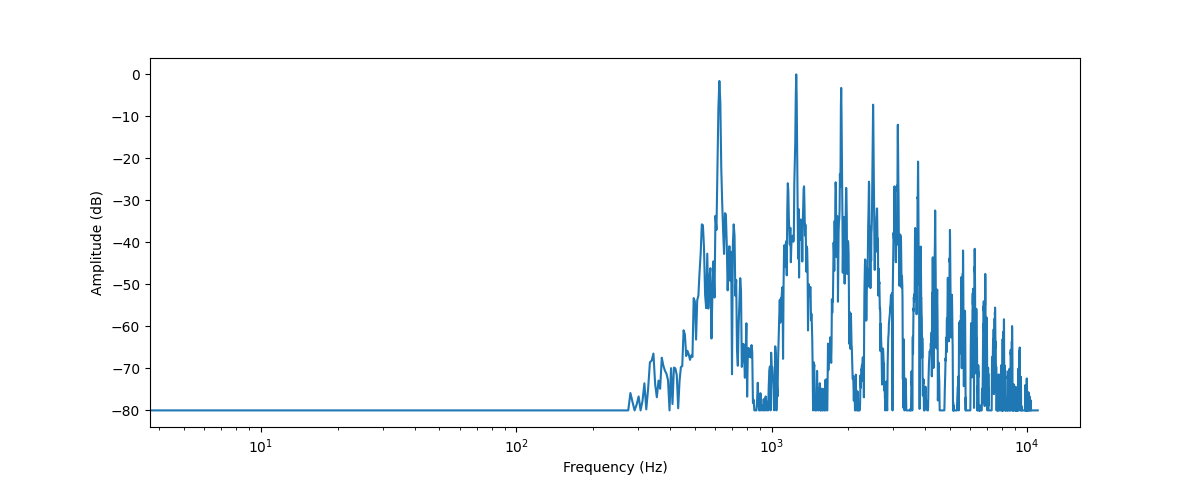
Здесь отображается сила различных частотных составляющих, присутствующих в данном аудио сегменте. На оси x откладываются значения частот, обычно в логарифмическом масштабе, а по оси y - их амплитуды.
Построенный нами частотный спектр имеет несколько пиков. Эти пики соответствуют гармоникам исполняемой ноты, причем более высокие гармоники более тихие. Поскольку первый пик находится на частоте около 620 Гц, это частотный спектр ноты E♭.
На выходе ДПФ получается массив комплексных чисел, состоящий из действительной и мнимой компонент. Взяв
величину с помощью np.abs(dft), можно извлечь из спектрограммы амплитудную информацию. Угол между действительной и
мнимой составляющими дает так называемый фазовый спектр, но в приложениях машинного обучения он часто отбрасывается.
Вы использовали librosa.amplitude_to_db() для преобразования значений амплитуды в децибельную шкалу, что облегчает просмотр
более тонких деталей в спектре. Иногда используют энергетический спектр, который измеряет энергию, а не амплитуду;
это просто спектр с квадратом амплитудных значений.
Частотный спектр аудиосигнала содержит точно такую же информацию, как и его волновая форма, - это просто два разных способа взглянуть на одни и те же данные (здесь - первые 4096 выборок из звука трубы). Если волновая форма отображает амплитуду звукового сигнала во времени, то спектр представляет амплитуды отдельных частот в фиксированный момент времени.
Спектрограмма
Что если мы хотим увидеть, как изменяются частоты в аудиосигнале? Труба играет несколько нот, и все они имеют разные частоты. Проблема в том, что спектр показывает только застывший снимок частот в данный момент времени. Решение состоит в том, чтобы взять несколько ДПФ, каждый из которых охватывает лишь небольшой отрезок времени, и сложить полученные спектры вместе в спектрограмму.
Спектрограмма представляет собой график изменения частотного содержания звукового сигнала во времени. Она позволяет увидеть время, частоту, и амплитуду на одном графике. Алгоритм, выполняющий эти вычисления, называется ОПФ или Оконное Преобразование Фурье (Short Time Fourier Transform - STFT).
Спектрограмма является одним из наиболее информативных аудио инструментов. Например, при работе с музыкальной записью можно увидеть различные инструменты и вокальные дорожки и их вклад в общее звучание. В речи можно идентифицировать различные гласные звуки, поскольку каждый гласный звук характеризуется определенными частотами.
Построим спектрограмму для того же звука трубы, используя функции библиотеки librosa stft() и specshow():
import numpy as np
D = librosa.stft(array)
S_db = librosa.amplitude_to_db(np.abs(D), ref=np.max)
plt.figure().set_figwidth(12)
librosa.display.specshow(S_db, x_axis="time", y_axis="hz")
plt.colorbar()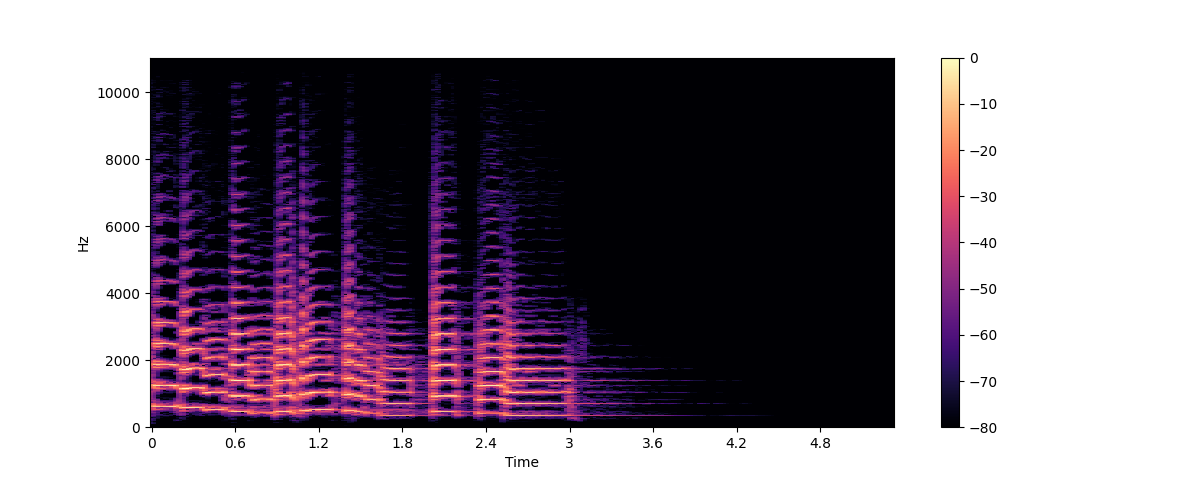
На этом графике ось x представляет собой время, как и при визуализации формы волны, но теперь ось y представляет собой частоту в Гц. Интенсивность цвета показывает амплитуду или мощность частотной составляющей в каждый момент времени, измеряемую в децибелах (дБ).
Спектрограмма создается путем выделения коротких сегментов аудиосигнала, как правило, длительностью несколько миллисекунд, и вычисления
дискретного преобразования Фурье каждого сегмента для получения его частотного спектра. Полученные спектры складываются
вместе по оси времени для получения спектрограммы. Каждый вертикальный срез на этом изображении соответствует одному частотному
спектру, если смотреть сверху. По умолчанию librosa.stft() разбивает аудиосигнал на сегменты по 2048 выборок, что
дает хороший компромисс между частотным и временным разрешением.
Поскольку спектрограмма и волновая форма - это разные представления одних и тех же данных, то с помощью обратного ОПФ можно превратить спектрограмму обратно в исходную волновую форму. Однако для этого помимо информации об амплитуде требуется информация о фазе. Если спектрограмма была сгенерирована моделью машинного обучения, то она, как правило, выдает только амплитуды. В этом случае для восстановления формы волны из спектрограммы можно использовать алгоритм восстановления фазы, например, классический алгоритм Гриффина-Лима, или нейронную сеть, называемую вокодером.
Спектрограммы используются не только для визуализации. Многие модели машинного обучения принимают на вход спектрограммы - в отличие от формы волны - и выдают на выходе спектрограммы.
Теперь, когда мы знаем, что такое спектрограмма и как она строится, рассмотрим ее разновидность, широко используемую при обработке речи, - Мел спектрограмму.
Мэл спектрограмма
Мел-спектрограмма - это разновидность спектрограммы, которая широко используется в задачах обработки речи и машинного обучения. Она похожа на спектрограмму тем, что показывает частотное содержание аудиосигнала во времени, но на другой частотной оси.
В стандартной спектрограмме частотная ось линейна и измеряется в герцах (Гц). Однако слуховая система человека более чувствительна к изменениям на низких частотах, чем на высоких, и эта чувствительность уменьшается логарифмически с увеличением частоты. Шкала Мэл - это перцептивная шкала, которая аппроксимирует нелинейную частотную характеристику человеческого уха.
Для создания мэл спектрограммы, как и ранее, используется ОПФ, при этом аудиосигнал разбивается на короткие сегменты для получения последовательности частотных спектров. Кроме того, каждый спектр пропускается через набор фильтров, так называемый банк фильтров мэла, для [NL1] преобразования частот в Мэл шкалу.
Рассмотрим, как можно построить мэл спектрограмму с помощью функции librosa melspectrogram(), которая выполняет все эти действия за нас:
S = librosa.feature.melspectrogram(y=array, sr=sampling_rate, n_mels=128, fmax=8000)
S_dB = librosa.power_to_db(S, ref=np.max)
plt.figure().set_figwidth(12)
librosa.display.specshow(S_dB, x_axis="time", y_axis="mel", sr=sampling_rate, fmax=8000)
plt.colorbar()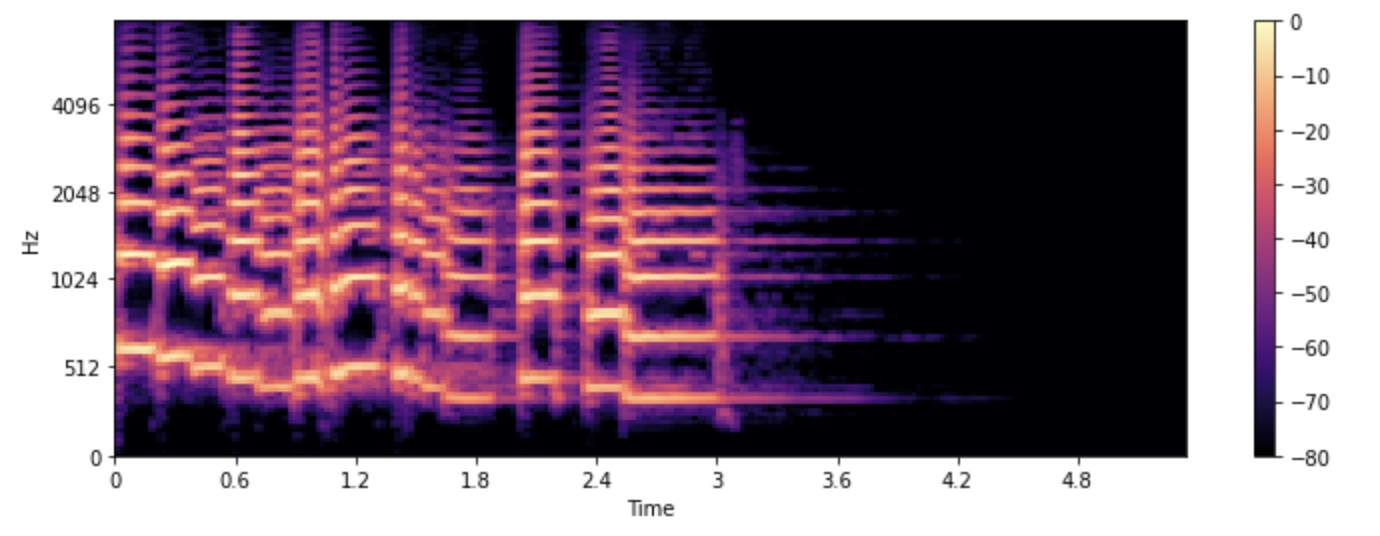
В приведенном примере n_mels означает количество генерируемых мэл диапазонов. Мел диапазоны определяют набор частотных
диапазонов, которые разделяют спектр на перцептивно значимые компоненты, используя набор фильтров, форма и расстояние между которыми
выбираются таким образом, чтобы имитировать реакцию человеческого уха на различные частоты. Обычные значения для n_mels это 40 или 80. fmax
указывает максимальную частоту (в Гц), которая нас интересует.
Как и в случае с обычной спектрограммой, принято выражать силу мел-частотных компонентов в
децибелах. Такую спектрограмму принято называть лог-мэл-спектрограммой, поскольку при переводе в децибелы выполняется
логарифмическая операция. В приведенном выше примере использовалась функция librosa.power_to_db(), так как librosa.feature.melspectrogram() создает спектрограмму мощности.
Создание mel-спектрограммы - это операция с потерями, так как она связана с фильтрацией сигнала. Конвертировать mel-спектрограмму обратно в волновую форму сложнее, чем обычную спектрограмму, так как для этого необходимо оценить частоты, которые были отброшены. Поэтому для получения формы волны из мэл спектрограммы необходимы модели машинного обучения, такие как вокодер HiFiGAN.
По сравнению со стандартной спектрограммой, мэл спектрограмма может отражать более значимые для восприятия человеком особенности аудиосигнала, что делает ее популярной в таких задачах, как распознавание речи, идентификация диктора и классификация музыкальных жанров.
Теперь, когда вы знаете, как визуализировать примеры аудиоданных, попробуйте посмотреть, как выглядят ваши любимые звуки. :)