Créer un assistant vocal
Dans cette section, nous allons rassembler trois modèles déjà vus pour construire un assistant vocal de bout en bout baptisé Marvin 🤖. Comme Alexa d’Amazon ou Siri d’Apple, Marvin est un assistant vocal répondant à un mot déclencheur particulier, écoutant ensuite une requête vocale et répond enfin par une réponse vocale.
Nous pouvons décomposer le pipeline de l’assistant vocal en quatre étapes, chacune d’entre elles nécessitant un modèle autonome :

1. Détection du mot déclencheur
Les assistants vocaux écoutent en permanence les entrées audio provenant du microphone de votre appareil, mais ils ne se mettent en action que lorsqu’un mot déclencheur (ou mot de réveil) particulier est prononcé.
La tâche de détection des mots déclencheurs est gérée par un petit modèle de classification audio sur l’appareil, qui est beaucoup plus petit et plus léger que le modèle de reconnaissance vocale, ne comportant souvent que quelques millions de paramètres, contre plusieurs centaines de millions pour la reconnaissance vocale. Il peut donc être exécuté en continu sur l’appareil sans en épuiser la batterie. Ce n’est que lorsque le mot de réveil est détecté que le modèle de reconnaissance vocale, plus grand, est lancé, avant d’être à nouveau arrêté.
2. Transcription de la parole
L’étape suivante du processus consiste à transcrire la requête vocale en texte. Dans la pratique, le transfert des fichiers audio de votre appareil local vers le cloud est lent en raison de la nature volumineuse des fichiers audio. Il est donc plus efficace de les transcrire directement à l’aide d’un modèle d’ASR sur l’appareil plutôt qu’à l’aide d’un modèle dans le cloud. Le modèle sur l’appareil peut être plus petit et donc moins précis qu’un modèle hébergé dans le cloud, mais la vitesse d’inférence plus rapide en vaut la peine puisque nous pouvons exécuter la reconnaissance vocale quasiment en temps réel, notre énoncé audio étant transcrit au fur et à mesure que nous le prononçons.
Nous sommes maintenant très familiers avec le processus de reconnaissance vocale, donc cela devrait être un jeu d’enfant !
3. Requêter le modèle de langage
Maintenant que nous savons ce que l’utilisateur a demandé, nous devons générer une réponse ! Les meilleurs modèles candidats pour cette tâche sont les grands modèles de langage (LLM), car ils sont effectivement capables de comprendre la sémantique de la requête textuelle et de générer une réponse appropriée.
Puisque notre requête textuelle est petite (juste quelques tokens), et les modèles de langage volumineux (plusieurs milliards de paramètres), la façon la plus efficace d’exécuter l’inférence est d’envoyer notre requête textuelle de notre appareil à un LLM fonctionnant dans le cloud, de générer une réponse textuelle, et de renvoyer la réponse à l’appareil.
4. Synthétiser la réponse
Enfin, nous utiliserons un modèle de synthèse vocale pour synthétiser la réponse textuelle sous forme de parole. Cette opération s’effectue sur l’appareil, mais il est tout à fait possible d’exécuter un modèle de synthèse vocale dans le cloud, en générant la sortie audio et en la transférant vers l’appareil.
Encore une fois, nous avons fait cela plusieurs fois maintenant, donc le processus sera très familier !
Détection des mots déclencheur
La première étape du pipeline de l’assistant vocal consiste à détecter si le mot déclencheur a été prononcé, et nous devons donc trouver un modèle pré-entraîné approprié pour cette tâche ! Vous vous souviendrez de la section sur les modèles pré-entraînés pour la classification audio que Speech Commands est un jeu de données de mots prononcés conçu pour évaluer les modèles de classification audio sur plus de 15 mots de commande simples comme up, down, yes et no, ainsi qu’un label silence pour classer l’absence de parole. Prenez une minute pour écouter les échantillons sur le visualisateur de jeux de données du Hub et vous familiariser à nouveau avec le jeu de données : visualisateur.
Nous pouvons utiliser un modèle de classification audio pré-entraîné sur le jeu de données Speech Commands et choisir l’un de ces mots de commande simples comme mot déclencheur. Parmi plus de 15 mots de commande possibles, si le modèle prédit avec la plus grande probabilité le mot que nous avons choisi, nous pouvons être quasiment certains que ce mot de déclencheur a été prononcé.
Rendez-vous sur le Hub et cliquez sur l’onglet Models : https://huggingface.co/models. Cela va faire apparaître tous les modèles sur le Hub :
Vous remarquerez sur le côté gauche que nous avons une sélection d’onglets que nous pouvons sélectionner pour filtrer les modèles par tâche, bibliothèque, jeu de données, etc. Faites défiler vers le bas et sélectionnez la tâche Audio Classification dans la liste des tâches audio :
Nous sommes maintenant en présence d’un sous-ensemble de plus de 500 modèles de classification audio sur le Hub. Pour affiner cette sélection, nous pouvons filtrer les modèles par jeu de données. Cliquez sur l’onglet Datasets et dans la barre de recherche, tapez speech_commands. Vous pouvez cliquer sur ce bouton pour filtrer tous les modèles de classification audio vers ceux qui ont été finetuné sur le jeu de données Speech Commands :
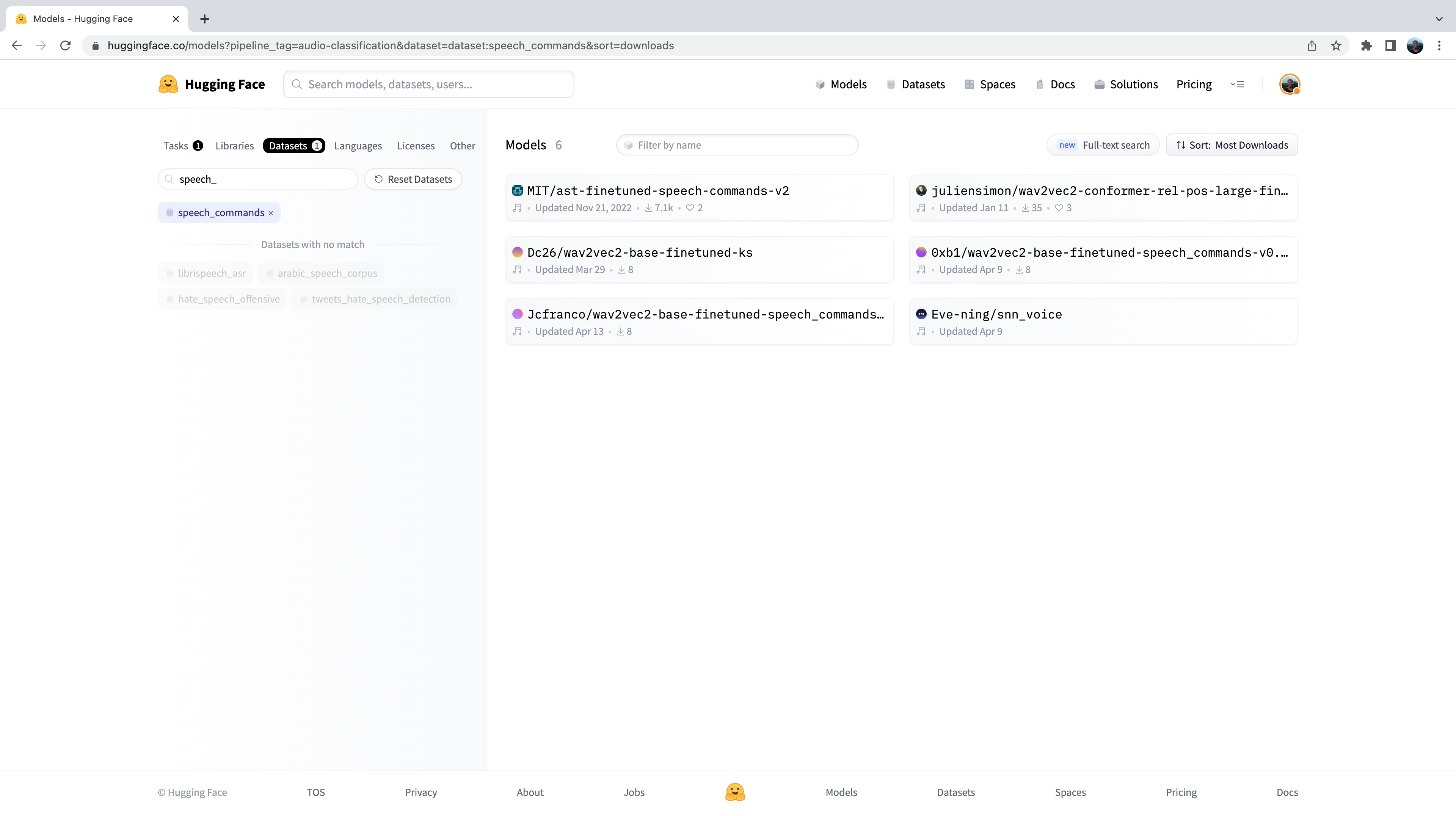
Bien , nous constatons que nous disposons de six modèles pré-entraînés pour ce jeu de données et cette tâche spécifiques (bien que de nouveaux modèles puissent être ajoutés si vous lisez à une date ultérieure !) Vous reconnaîtrez le premier de ces modèles comme le Spectrogram Transformer que nous avons utilisé dans l’exemple de l’unité 4. Nous utiliserons à nouveau ce checkpoint pour notre tâche de détection de mots déclencheur.
Chargeons le checkpoint à l’aide de la classe pipeline :
from transformers import pipeline
import torch
device = "cuda:0" if torch.cuda.is_available() else "cpu"
classifier = pipeline(
"audio-classification", model="MIT/ast-finetuned-speech-commands-v2", device=device
)Nous pouvons vérifier sur quelles étiquettes le modèle a été entraîné en vérifiant l’attribut id2label dans la configuration du modèle :
classifier.model.config.id2label
Nous voyons que le modèle a été entraîné sur 35 étiquettes de classe, y compris quelques mots déclencheurs simples que nous avons décrits ci-dessus, ainsi que quelques objets particuliers comme bed, house et cat. Nous voyons qu’il y a un nom dans ces étiquettes de classe : id 27 correspond à l’étiquette marvin :
classifier.model.config.id2label[27]'marvin'Parfait ! Nous pouvons utiliser ce nom comme mot délchencheur de notre assistant vocal, de la même manière qu’on utilise “Alexa” pour l’Alexa d’Amazon, ou “Hey Siri” pour le Siri d’Apple. Parmi toutes les étiquettes possibles, si le modèle prédit “marvin” avec la probabilité de classe la plus élevée, nous pouvons être sûrs que le mot de réveil que nous avons choisi a été prononcé.
Nous devons maintenant définir une fonction qui écoute en permanence le microphone de notre appareil et qui transmet continuellement l’audio au modèle de classification pour inférence. Pour ce faire, nous allons utiliser une fonction d’aide pratique fournie avec 🤗 Transformers appelée ffmpeg_microphone_live.
Cette fonction transmet de petits morceaux d’audio d’une longueur spécifiée chunk_length_s au classifieur. Pour s’assurer que nous obtenons des frontières lisses entre les morceaux d’audio, nous lançons une fenêtre coulissante à travers notre audio avec un pas de chunk_length_s / 6.
Pour que nous n’ayons pas à attendre que tout le premier morceau soit enregistré avant de commencer l’inférence, nous définissons également une longueur d’entrée audio temporaire minimale stream_chunk_s qui est transmise au modèle avant que le temps chunk_length_s ne soit atteint.
La fonction ffmpeg_microphone_live renvoie un objet generator, produisant une séquence de morceaux audio qui peuvent chacun être transmis au modèle de classification pour faire une prédiction. Nous pouvons passer ce générateur directement au pipeline, qui à son tour retourne une séquence de prédictions de sortie, une pour chaque morceau d’entrée audio. Nous pouvons inspecter les probabilités des classes pour chaque morceau d’audio, et arrêter notre boucle de détection de mot de réveil lorsque nous détectons que le mot de réveil a été prononcé.
Nous utiliserons un critère très simple pour déterminer si notre mot de réveil a été prononcé : si l’étiquette de classe ayant la probabilité la plus élevée est celle de notre mot, et que cette probabilité dépasse un seuil prob_threshold, nous déclarons que le mot déclencheur a été prononcé. L’utilisation d’un seuil de probabilité pour contrôler notre classifieur garantit que le mot déclencheur n’est pas prédit par erreur si l’entrée audio est un bruit, ce qui est typiquement le cas lorsque le modèle est très incertain et que toutes les probabilités d’étiquettes de classe sont faibles. Vous voudrez peut-être ajuster ce seuil de probabilité ou explorer des moyens plus sophistiqués par le biais d’une métrique basée sur l’entropie.
from transformers.pipelines.audio_utils import ffmpeg_microphone_live
def launch_fn(
wake_word="marvin",
prob_threshold=0.5,
chunk_length_s=2.0,
stream_chunk_s=0.25,
debug=False,
):
if wake_word not in classifier.model.config.label2id.keys():
raise ValueError(
f"Wake word {wake_word} not in set of valid class labels, pick a wake word in the set {classifier.model.config.label2id.keys()}."
)
sampling_rate = classifier.feature_extractor.sampling_rate
mic = ffmpeg_microphone_live(
sampling_rate=sampling_rate,
chunk_length_s=chunk_length_s,
stream_chunk_s=stream_chunk_s,
)
print("Listening for wake word...")
for prediction in classifier(mic):
prediction = prediction[0]
if debug:
print(prediction)
if prediction["label"] == wake_word:
if prediction["score"] > prob_threshold:
return TrueEssayons cette fonction pour voir comment elle fonctionne ! Nous allons mettre debug=True pour afficher la prédiction pour chaque morceau d’audio. Laissons le modèle fonctionner pendant quelques secondes pour voir le type de prédictions qu’il fait lorsqu’il n’y a pas de parole, puis prononçons clairement le mot de réveil marvin et regardons sa prédiction monter en flèche à près de 1 :
launch_fn(debug=True)Listening for wake word...
{'score': 0.055326107889413834, 'label': 'one'}
{'score': 0.05999856814742088, 'label': 'off'}
{'score': 0.1282748430967331, 'label': 'five'}
{'score': 0.07310110330581665, 'label': 'follow'}
{'score': 0.06634809821844101, 'label': 'follow'}
{'score': 0.05992642417550087, 'label': 'tree'}
{'score': 0.05992642417550087, 'label': 'tree'}
{'score': 0.999913215637207, 'label': 'marvin'}Génial ! Comme nous nous y attendions, le modèle génère des prédictions erronées pendant les premières secondes. Il n’y a pas d’entrée vocale, donc le modèle fait des prédictions presque aléatoires, mais avec une très faible probabilité. Dès que nous prononçons le mot de réveil, le modèle prédit marvin avec une probabilité proche de 1 et termine la boucle, signalant que le mot de réveil a été détecté et que le système ASR doit être activé !
Transcription de la parole
Une fois de plus, nous utiliserons le modèle Whisper pour notre système de transcription de la parole. Plus précisément, nous chargerons le checkpoint Whisper Base English, car il est suffisamment petit pour donner une bonne vitesse d’inférence avec une précision de transcription raisonnable. Nous utiliserons une astuce pour obtenir une transcription presque en temps réel en étant astucieux sur la façon dont nous transmettons nos entrées audio au modèle. Comme auparavant, vous pouvez utiliser n’importe quel modèle de reconnaissance vocale sur le Hub, y compris Wav2Vec2, MMS ASR ou d’autres tailles de Whisper :
transcriber = pipeline(
"automatic-speech-recognition", model="openai/whisper-base.en", device=device
)"openai/whisper-small.en".Nous pouvons maintenant définir une fonction pour enregistrer l’entrée de notre microphone et transcrire le texte correspondant. Avec la fonction d’aide ffmpeg_microphone_live, nous pouvons contrôler le degré de “temps réel” de notre modèle de reconnaissance vocale. L’utilisation d’un stream_chunk_s plus petit se prête à une reconnaissance vocale davantage en temps réel, puisque nous divisons notre audio d’entrée en plus petits morceaux et que nous les transcrivons à la volée. Cependant, cela se fait au détriment de la précision, puisqu’il y a moins de contexte pour le modèle à déduire.
Lors de la transcription de la parole, nous devons également avoir une idée du moment où l’utilisateur s’arrête de parler, afin de pouvoir mettre fin à l’enregistrement. Pour des raisons de simplicité, nous mettrons fin à l’enregistrement après le premier chunk_length_s (qui est fixé à 5 secondes par défaut), mais vous pouvez essayer d’utiliser un modèle de détection de l’activité vocale (VAD pour voice activity detection) pour prédire quand l’utilisateur s’est arrêté de parler.
import sys
def transcribe(chunk_length_s=5.0, stream_chunk_s=1.0):
sampling_rate = transcriber.feature_extractor.sampling_rate
mic = ffmpeg_microphone_live(
sampling_rate=sampling_rate,
chunk_length_s=chunk_length_s,
stream_chunk_s=stream_chunk_s,
)
print("Start speaking...")
for item in transcriber(mic, generate_kwargs={"max_new_tokens": 128}):
sys.stdout.write("\033[K")
print(item["text"], end="\r")
if not item["partial"][0]:
break
return item["text"]Essayons et voyons comment nous nous débrouillerons ! Une fois que le microphone est activé, commencez à parler et regardez votre transcription apparaître en semi-temps réel :
transcribe()
Start speaking... Hey, this is a test with the whisper model.
Bien, vous pouvez ajuster la longueur maximale de l’audio chunk_length_s en fonction de la rapidité ou de la lenteur avec laquelle vous parlez (augmentez-la si vous avez l’impression de ne pas avoir assez de temps pour parler, diminuez-la si vous êtes resté dans l’expectative à la fin), et le stream_chunk_s pour le facteur temps réel. Il suffit de passer ces arguments à la fonction transcribe.
Requêter le modèle de langue
Maintenant que notre requête vocale a été transcrite, nous voulons générer une réponse significative. Pour ce faire, nous utiliserons un LLM hébergé sur le cloud. Plus précisément, nous choisissons un LLM sur le Hub et utilisons l’API Inference pour interroger facilement le modèle.
Trouvons notre LLM sur le Hub en utilisant l’🤗 Open LLM Leaderboard, un Space qui classe les LLM par performance sur quatre tâches de génération. Nous effectuerons une recherche par “instruct” pour filtrer les modèles qui ont été finetuné car devraient mieux fonctionner pour notre tâche de requêtage :

Nous utiliserons le checkpoint tiiuae/falcon-7b-instruct par TII, un transformer décodeur de paramètres 7B finetuné sur un mélange de jeux de données de chat et d’instructions. Vous pouvez utiliser n’importe quel LLM du Hub ayant l’”Hosted inference API” activé. Il suffit de regarder le widget sur le côté droit de la carte du modèle :

L’API Inference nous permet d’envoyer une requête HTTP depuis notre machine locale vers le LLM hébergé sur le Hub, et renvoie la réponse sous la forme d’un fichier json. Tout ce que nous devons fournir est notre token d’authentification au Hub et l’identifiant du modèle du LLM que nous souhaitons interroger :
from huggingface_hub import HfFolder
import requests
def query(text, model_id="tiiuae/falcon-7b-instruct"):
api_url = f"https://api-inference.huggingface.co/models/{model_id}"
headers = {"Authorization": f"Bearer {HfFolder().get_token()}"}
payload = {"inputs": text}
print(f"Querying...: {text}")
response = requests.post(api_url, headers=headers, json=payload)
return response.json()[0]["generated_text"][len(text) + 1 :]Essayons-le avec une entrée de test !
query("What does Hugging Face do?")'Hugging Face is a company that provides natural language processing and machine learning tools for developers. They'Vous remarquerez à quel point l’inférence est rapide en utilisant l’API Inference. Nous n’avons qu’à envoyer un petit nombre de tokens de texte de notre machine locale au modèle hébergé, le coût de communication est donc très faible. Le LLM est hébergé sur des GPU, de sorte que l’inférence s’exécute très rapidement. Enfin, la réponse générée est transférée du modèle à notre machine locale, toujours avec un faible coût de communication.
Synthétiser la parole
Et maintenant, nous sommes prêts à obtenir la sortie vocale finale ! Une fois de plus, nous utiliserons le modèle SpeechT5 TTS de Microsoft mais vous pouvez utiliser n’importe quel modèle TTS de votre choix. Chargeons le processeur et le modèle :
from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech, SpeechT5HifiGan
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts")
model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts").to(device)
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan").to(device)Et aussi l’enchâssement des locuteurs :
from datasets import load_dataset
embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
speaker_embeddings = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0)Nous allons réutiliser la fonction synthesise que nous avons définie dans le chapitre précédent :
def synthesise(text):
inputs = processor(text=text, return_tensors="pt")
speech = model.generate_speech(
inputs["input_ids"].to(device), speaker_embeddings.to(device), vocoder=vocoder
)
return speech.cpu()Vérifions rapidement que cela fonctionne comme prévu :
from IPython.display import Audio
audio = synthesise(
"Hugging Face is a company that provides natural language processing and machine learning tools for developers."
)
Audio(audio, rate=16000)Joli travail 👍
Marvin 🤖
Maintenant que nous avons défini une fonction pour chacune des quatre étapes du pipeline de l’assistant vocal, il ne reste plus qu’à les assembler pour obtenir notre assistant vocal de bout en bout. Nous allons simplement concaténer les quatre étapes, en commençant par la détection du mot de réveil (launch_fn), la transcription de la parole, le requêtage du LLM, et enfin la synthèse de la parole.
launch_fn()
transcription = transcribe()
response = query(transcription)
audio = synthesise(response)
Audio(audio, rate=16000, autoplay=True)Essayez-le avec quelques demandes ! Voici quelques exemples pour vous aider à démarrer :
- *Quel est le pays le plus chaud du monde ?
- Comment fonctionnent les transformers* ?
- *Connais-tu l’espagnol ?
Et avec cela, nous avons notre assistant vocal complet, réalisé à l’aide des outils audio que vous avez appris tout au long de ce cours, avec une pincée de magie LLM à la fin. Il y a plusieurs extensions que nous pourrions faire pour améliorer l’assistant vocal. Tout d’abord, le modèle de classification audio classifie 35 étiquettes différentes. Nous pourrions utiliser un modèle de classification binaire plus petit et plus léger qui prédit uniquement si le mot de réveil a été prononcé ou non. Deuxièmement, nous préchargeons tous les modèles à l’avance et les laissons tourner sur notre appareil. Si nous voulions économiser de l’énergie, nous ne chargerions chaque modèle qu’au moment où il est nécessaire, et nous le déchargerions par la suite. Troisièmement, il manque un modèle de détection de l’activité vocale dans notre fonction de transcription, qui transcrit pendant une durée fixe, parfois trop longue, parfois trop courte.
Généralisation 🪄
Jusqu’à présent, nous avons vu comment générer des sorties vocales avec notre assistant vocal Marvin. Pour terminer, nous allons montrer comment nous pouvons généraliser ces sorties vocales au texte, à l’audio et à l’image.
Nous utiliserons Transformers Agents pour créer notre assistant. Transformers Agents fournit une API de langage naturel au-dessus des bibliothèques 🤗 Transformers et Diffusers, interprétant une entrée de langage naturel en utilisant un LLM avec des prompts soigneusement conçus, et en utilisant un ensemble d’outils pour fournir des sorties multimodales.
Allons-y et instançons un agent. Il y a trois LLM disponibles pour Transformers Agents, dont deux sont open-source et gratuits sur le Hub. Le troisième est un modèle d’OpenAI qui nécessite une clé API OpenAI. Nous utiliserons le modèle gratuit Bigcode Starcoder dans cet exemple, mais vous pouvez également essayer l’un ou l’autre des autres LLM disponibles :
from transformers import HfAgent
agent = HfAgent(
url_endpoint="https://api-inference.huggingface.co/models/bigcode/starcoder"
)Pour utiliser l’agent, il suffit d’appeler agent.run avec notre prompt de texte. A titre d’exemple, nous allons lui faire générer une image d’un chat 🐈 (qui, espérons-le, ait l’air un peu mieux que cet emoji) :
agent.run("Generate an image of a cat")
C’est aussi simple que cela ! L’agent a interprété notre prompt et a utilisé Stable Diffusion pour générer l’image, sans que nous ayons à nous soucier du chargement du modèle, de l’écriture de la fonction ou de l’exécution du code.
Nous pouvons maintenant remplacer notre fonction de requête LLM et l’étape de synthèse de texte par notre Transformers Agent dans notre assistant vocal, puisque l’Agent va s’occuper de ces deux étapes pour nous :
launch_fn() transcription = transcribe() agent.run(transcription)
Essayez de prononcer le même prompt “Générer une image d’un chat” (en anglais “Generate an image of a cat”) et voyez comment le système s’en sort. Si vous posez à l’agent une simple requête de type question/réponse, l’agent répondra par un texte. Vous pouvez l’encourager à générer des sorties multimodales en lui demandant de renvoyer une image ou de la parole. Par exemple, vous pouvez lui demander de générer une image d’un chat, la légender et prononcer la légende (“Generate an image of a cat, caption it, and speak the caption”).
Bien que l’agent soit plus flexible que notre première itération de l’assistant Marvin 🤖, cette généralisation peut conduire à des performances inférieures sur les requêtes standard de l’assistant vocal. Pour récupérer des performances, vous pouvez essayer d’utiliser un LLM plus performant, comme celui d’OpenAI, ou définir un ensemble d’outils personnalisés spécifiques à la tâche d’assistant vocal.
< > Update on GitHub