Finetuning du SpeechT5
Maintenant que vous êtes familiarisé avec la tâche de synthèse vocale et le fonctionnement interne du SpeechT5 qui a été entraîné sur des données en langue anglaise, voyons comment nous pouvons le finetuner à une autre langue.
Préparation
Assurez-vous de disposer d’un GPU si vous souhaitez reproduire cet exemple. Dans un notebook, vous pouvez vérifier avec la commande suivante :
nvidia-smi
Dans notre exemple, nous utiliserons environ 40 heures de données d’entraînement. Si vous souhaitez suivre en utilisant la version gratuite de Google Colab, vous devrez réduire la quantité de données d’entraînement à environ 10-15 heures, ainsi que réduire le nombre d’étapes d’entraînement.
Vous aurez également besoin de quelques dépendances supplémentaires :
pip install transformers datasets soundfile speechbrain accelerate
Enfin, n’oubliez pas de vous connecter à votre compte Hugging Face pour pouvoir télécharger et partager votre modèle avec la communauté :
from huggingface_hub import notebook_login
notebook_login()Le jeu de données
Pour cet exemple, nous prendrons le sous-ensemble en néerlandais (nl) du jeu de données VoxPopuli.
VoxPopuli est un corpus de parole multilingue à grande échelle composé de données provenant d’enregistrements d’événements du Parlement européen de 2009 à 2020.
Il contient des données de transcription audio étiquetées pour 15 langues européennes. Nous utiliserons le sous-ensemble néerlandais, mais vous pouvez choisir un autre sous-ensemble.
Il s’agit d’un jeu de données de reconnaissance automatique de la parole, donc comme mentionné précédemment, ce n’est pas l’option la plus appropriée pour entraîner des modèles TTS. Cependant, il sera suffisant pour cet exercice.
Chargeons les données :
from datasets import load_dataset, Audio
dataset = load_dataset("facebook/voxpopuli", "nl", split="train")
len(dataset)Sortie :
20968
20968 exemples devraient suffire pour un finetuning. SpeechT5 s’attend à ce que les données audio aient une fréquence d’échantillonnage de 16 kHz, assurez-vous donc que les exemples du jeu de données répondent à cette exigence :
dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))Prétraitement des données
Commençons par définir le checkpoint du modèle à utiliser et par charger le processeur approprié qui contient à la fois le tokenizer et l’extracteur de caractéristiques dont nous aurons besoin pour préparer les données en vue de l’entraînement :
from transformers import SpeechT5Processor
checkpoint = "microsoft/speecht5_tts"
processor = SpeechT5Processor.from_pretrained(checkpoint)Nettoyage du texte pour la tokenisation de SpeechT5
Tout d’abord, pour préparer le texte, nous aurons besoin de la partie tokenizer du processeur, alors allons-y :
tokenizer = processor.tokenizer
Prenons un exemple :
dataset[0]Sortie :
{'audio_id': '20100210-0900-PLENARY-3-nl_20100210-09:06:43_4',
'language': 9,
'audio': {'path': '/root/.cache/huggingface/datasets/downloads/extracted/02ec6a19d5b97c03e1379250378454dbf3fa2972943504a91c7da5045aa26a89/train_part_0/20100210-0900-PLENARY-3-nl_20100210-09:06:43_4.wav',
'array': array([ 4.27246094e-04, 1.31225586e-03, 1.03759766e-03, ...,
-9.15527344e-05, 7.62939453e-04, -2.44140625e-04]),
'sampling_rate': 16000},
'raw_text': 'Dat kan naar mijn gevoel alleen met een brede meerderheid die wij samen zoeken.',
'normalized_text': 'dat kan naar mijn gevoel alleen met een brede meerderheid die wij samen zoeken.',
'gender': 'female',
'speaker_id': '1122',
'is_gold_transcript': True,
'accent': 'None'}Vous remarquerez que les exemples du jeu de données contiennent les caractéristiques raw_text et normalized_text. Lorsque vous décidez quelle caractéristique utiliser comme entrée de texte, il est important de savoir que le tokenizer de SpeechT5 n’a pas de tokens pour les nombres. Dans normalized_text, les nombres sont écrits sous forme textuel. Il s’agit donc d’une meilleure option, et nous devrions utiliser normalized_text comme texte d’entrée.
Comme SpeechT5 a été entraîné sur la langue anglaise, il se peut qu’il ne reconnaisse pas certains caractères dans le jeu de données néerlandais.
S’ils sont laissés tels quels, ces caractères seront convertis en tokens <unk>. Cependant, en néerlandais, certains caractères comme à sont utilisés pour souligner les syllabes. Afin de préserver le sens du texte, nous pouvons remplacer ce caractère par un a normal.
Pour identifier les tokens non supportés, extrayez tous les caractères uniques du jeu de données en utilisant le SpeechT5Tokenizer qui fonctionne avec les caractères comme des tokens.
Pour ce faire, nous allons écrire la fonction extract_all_chars qui concatène les transcriptions de tous les exemples en une chaîne et la convertit en un ensemble de caractères.
Assurez-vous de mettre batched=True et batch_size=-1 dans dataset.map() afin que toutes les transcriptions soient disponibles en même temps pour la fonction de mapping.
def extract_all_chars(batch):
all_text = " ".join(batch["normalized_text"])
vocab = list(set(all_text))
return {"vocab": [vocab], "all_text": [all_text]}
vocabs = dataset.map(
extract_all_chars,
batched=True,
batch_size=-1,
keep_in_memory=True,
remove_columns=dataset.column_names,
)
dataset_vocab = set(vocabs["vocab"][0])
tokenizer_vocab = {k for k, _ in tokenizer.get_vocab().items()}Vous disposez à présent de deux ensembles de caractères : l’un avec le vocabulaire du jeu de données et l’autre avec le vocabulaire du tokenizer. Pour identifier les caractères non pris en charge dans le jeu de données, vous pouvez prendre la différence entre ces deux ensembles. L’ensemble résultant contiendra les caractères qui se trouvent dans le jeu de données mais pas dans le tokenizer.
dataset_vocab - tokenizer_vocab
Sortie :
{' ', 'à', 'ç', 'è', 'ë', 'í', 'ï', 'ö', 'ü'}Pour gérer les caractères non supportés identifiés dans l’étape précédente, nous pouvons définir une fonction qui fait correspondre ces caractères à des tokens valides. Notez que les espaces sont déjà remplacés par ▁ dans le tokenizer et n’ont pas besoin d’être gérés séparément.
replacements = [
("à", "a"),
("ç", "c"),
("è", "e"),
("ë", "e"),
("í", "i"),
("ï", "i"),
("ö", "o"),
("ü", "u"),
]
def cleanup_text(inputs):
for src, dst in replacements:
inputs["normalized_text"] = inputs["normalized_text"].replace(src, dst)
return inputs
dataset = dataset.map(cleanup_text)Maintenant que nous avons traité les caractères spéciaux dans le texte, il est temps de se concentrer sur les données audio.
Les locuteurs
Le jeu de données VoxPopuli comprend la parole de plusieurs locuteurs, mais combien de locuteurs sont représentés dans le jeu de données ? Pour le savoir, nous pouvons compter le nombre de locuteurs uniques et le nombre d’exemples que chaque locuteur apporte au jeu de données. Avec un total de 20 968 exemples dans le jeu de données, cette information nous permettra de mieux comprendre la distribution des locuteurs et des exemples dans les données.
from collections import defaultdict
speaker_counts = defaultdict(int)
for speaker_id in dataset["speaker_id"]:
speaker_counts[speaker_id] += 1En traçant un histogramme, vous pouvez vous faire une idée de la quantité de données pour chaque locuteur.
import matplotlib.pyplot as plt
plt.figure()
plt.hist(speaker_counts.values(), bins=20)
plt.ylabel("Speakers")
plt.xlabel("Examples")
plt.show()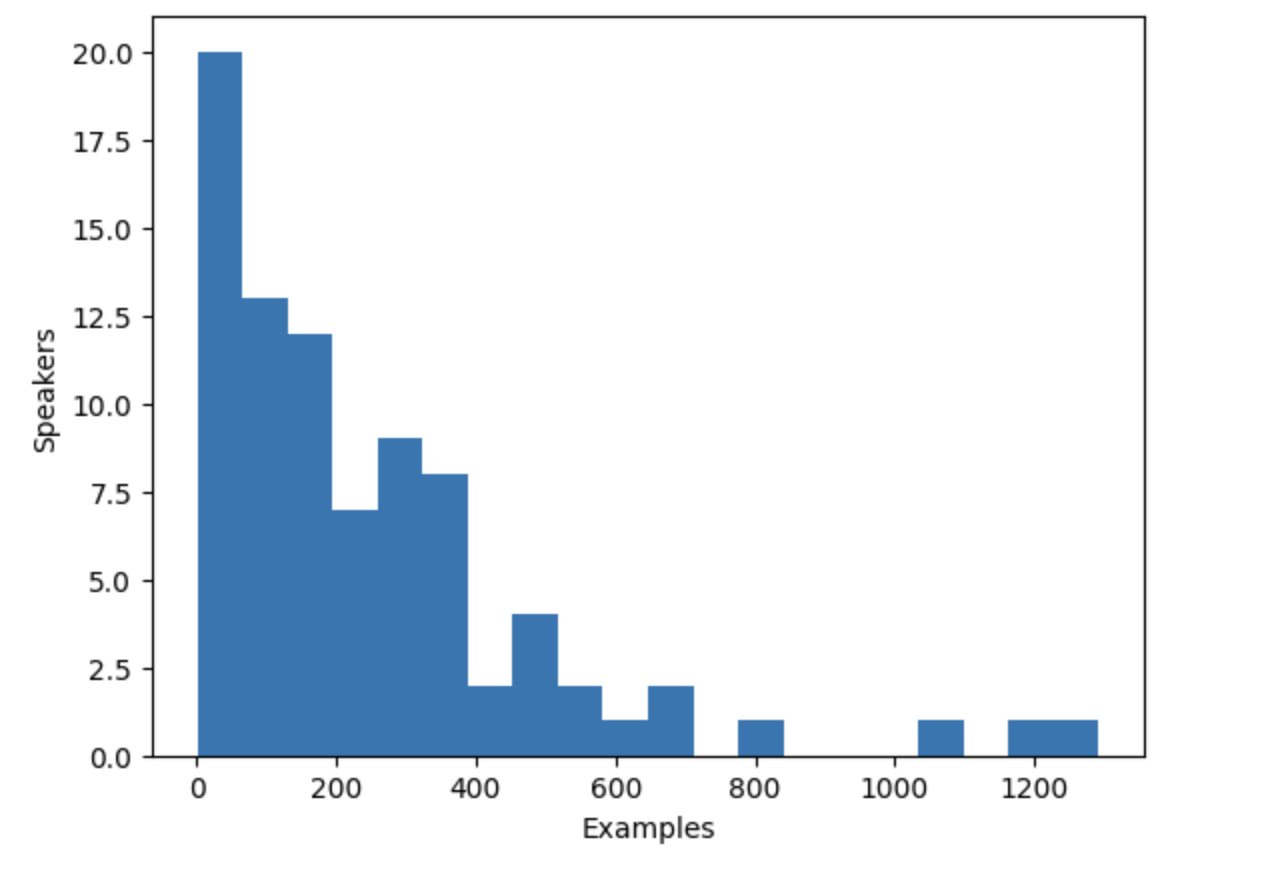
L’histogramme révèle qu’environ un tiers des locuteurs du jeu de données ont moins de 100 exemples, tandis qu’une dizaine de locuteurs ont plus de 500 exemples. Pour améliorer l’efficacité de l’entraînement et équilibrer le jeu de données, nous pouvons limiter les données aux locuteurs ayant entre 100 et 400 exemples.
def select_speaker(speaker_id):
return 100 <= speaker_counts[speaker_id] <= 400
dataset = dataset.filter(select_speaker, input_columns=["speaker_id"])Vérifions le nombre de locuteurs restants :
len(set(dataset["speaker_id"]))Sortie :
42
Voyons combien d’exemples il reste :
len(dataset)Sortie :
9973Vous vous retrouvez avec un peu moins de 10 000 exemples provenant d’environ 40 locuteurs uniques, ce qui devrait être suffisant.
Notez que certains locuteurs ayant peu d’exemples peuvent en fait avoir plus d’audio disponible si les exemples sont longs. Cependant, pour déterminer la quantité totale d’audio pour chaque locuteur, il faut parcourir l’ensemble des données, ce qui est un processus long qui implique le chargement et le décodage de chaque fichier audio. C’est pourquoi nous avons choisi de sauter cette étape.
Enchâssement des locuteurs
Pour permettre au modèle TTS de différencier plusieurs locuteurs, vous devrez créer un enchâssement de locuteur pour chaque exemple. C’est est une entrée supplémentaire dans le modèle qui capture les caractéristiques de la voix d’un locuteur particulier. Pour générer ces enchâssements, utilisez le modèle pré-entraîné spkrec-xvect-voxceleb de SpeechBrain.
Créez une fonction create_speaker_embedding() qui prend une forme d’onde audio en entrée et produit un vecteur de 512 éléments contenant l’enchâssement du locuteur correspondant.
import os
import torch
from speechbrain.pretrained import EncoderClassifier
spk_model_name = "speechbrain/spkrec-xvect-voxceleb"
device = "cuda" if torch.cuda.is_available() else "cpu"
speaker_model = EncoderClassifier.from_hparams(
source=spk_model_name,
run_opts={"device": device},
savedir=os.path.join("/tmp", spk_model_name),
)
def create_speaker_embedding(waveform):
with torch.no_grad():
speaker_embeddings = speaker_model.encode_batch(torch.tensor(waveform))
speaker_embeddings = torch.nn.functional.normalize(speaker_embeddings, dim=2)
speaker_embeddings = speaker_embeddings.squeeze().cpu().numpy()
return speaker_embeddingsIl est important de noter que le modèle speechbrain/spkrec-xvect-voxceleb a été entraîné sur de l’anglais provenant du jeu de données VoxCeleb, alors que les exemples d’entraînement dans ce guide sont en néerlandais. Bien que nous pensions que ce modèle génèrerait toujours des enchâssements de locuteurs raisonnables pour notre jeu de données néerlandais, cette hypothèse peut ne pas être vraie dans tous les cas.
Pour obtenir des résultats optimaux, nous devrions d’abord entraîner un modèle de vecteur X sur le discours cible. Ainsi, le modèle sera mieux à même de capturer les caractéristiques vocales uniques présentes dans la langue néerlandaise. Si vous souhaitez entraîner votre propre modèle X-vector, vous pouvez utiliser ce script comme exemple.
Traitement du jeu de données
Enfin, traitons les données dans le format attendu par le modèle. Créez une fonction prepare_dataset qui prend un seul exemple et utilise l’objet SpeechT5Processor pour tokeniser le texte d’entrée et charger l’audio cible dans un spectrogramme log-mel.
Elle devrait également ajouter les enchâssements de locuteur en tant qu’entrée supplémentaire.
def prepare_dataset(example):
audio = example["audio"]
example = processor(
text=example["normalized_text"],
audio_target=audio["array"],
sampling_rate=audio["sampling_rate"],
return_attention_mask=False,
)
# strip off the batch dimension
example["labels"] = example["labels"][0]
# use SpeechBrain to obtain x-vector
example["speaker_embeddings"] = create_speaker_embedding(audio["array"])
return exampleVérifiez que le traitement est correct en examinant un seul exemple :
processed_example = prepare_dataset(dataset[0])
list(processed_example.keys())Sortie :
['input_ids', 'labels', 'stop_labels', 'speaker_embeddings']Les enchâssements de locuteurs doivent être un vecteur de 512 éléments :
processed_example["speaker_embeddings"].shapeSortie :
(512,)Les étiquettes doivent être un spectrogramme log-mel avec 80 bins mel.
import matplotlib.pyplot as plt
plt.figure()
plt.imshow(processed_example["labels"].T)
plt.show()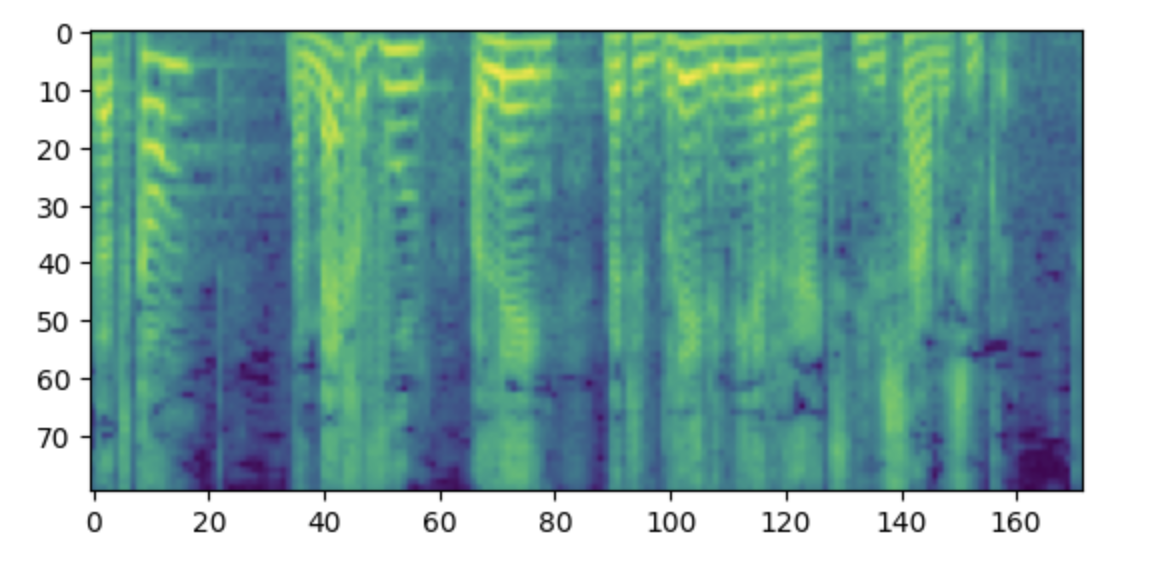
Remarque : si vous trouvez ce spectrogramme déroutant, c’est peut-être parce que vous êtes familier avec la convention qui consiste à placer les basses fréquences en bas et les hautes fréquences en haut d’un graphique. Cependant, lorsque l’on trace des spectrogrammes sous forme d’image à l’aide de la bibliothèque matplotlib, l’axe des ordonnées est inversé et les spectrogrammes apparaissent à l’envers.
Nous devons maintenant appliquer la fonction de traitement à l’ensemble du jeu de données. Cela prendra entre 5 et 10 minutes.
dataset = dataset.map(prepare_dataset, remove_columns=dataset.column_names)Vous verrez un avertissement indiquant que certains exemples du jeu de données sont plus longs que la longueur d’entrée maximale que le modèle peut traiter (600 tokens). Supprimez ces exemples du jeu de données. Ici, nous allons encore plus loin et, pour tenir compte de la taille des batchs, nous supprimons tout ce qui dépasse 200 tokens.
def is_not_too_long(input_ids):
input_length = len(input_ids)
return input_length < 200
dataset = dataset.filter(is_not_too_long, input_columns=["input_ids"])
len(dataset)Sortie :
8259Next, create a basic train/test split:
dataset = dataset.train_test_split(test_size=0.1)Assembleur de données
Afin de combiner plusieurs exemples dans un batch, vous devez définir un assembleur de données personnalisé. Il remplacera les séquences les plus courtes par des tokens de rembourrage, afin de s’assurer que tous les exemples ont la même longueur. Pour les étiquettes des spectrogrammes, les parties rembourrées sont remplacées par la valeur spéciale -100. Cette valeur spéciale indique au modèle d’ignorer cette partie du spectrogramme lors du calcul de la perte de spectrogramme.
from dataclasses import dataclass
from typing import Any, Dict, List, Union
@dataclass
class TTSDataCollatorWithPadding:
processor: Any
def __call__(
self, features: List[Dict[str, Union[List[int], torch.Tensor]]]
) -> Dict[str, torch.Tensor]:
input_ids = [{"input_ids": feature["input_ids"]} for feature in features]
label_features = [{"input_values": feature["labels"]} for feature in features]
speaker_features = [feature["speaker_embeddings"] for feature in features]
# assembler les données d'entrée et les cibles dans un batch
batch = processor.pad(
input_ids=input_ids, labels=label_features, return_tensors="pt"
)
# remplacer le rembourrage par -100 pour ignorer correctement les pertes
batch["labels"] = batch["labels"].masked_fill(
batch.decoder_attention_mask.unsqueeze(-1).ne(1), -100
)
# non utilisé pendant le finetuning
del batch["decoder_attention_mask"]
# arrondir les longueurs cibles au multiple du facteur de réduction
if model.config.reduction_factor > 1:
target_lengths = torch.tensor(
[len(feature["input_values"]) for feature in label_features]
)
target_lengths = target_lengths.new(
[
length - length % model.config.reduction_factor
for length in target_lengths
]
)
max_length = max(target_lengths)
batch["labels"] = batch["labels"][:, :max_length]
# ajoutez également les enchâssements de locuteur
batch["speaker_embeddings"] = torch.tensor(speaker_features)
return batchDans SpeechT5, l’entrée de la partie décodeur du modèle est réduite d’un facteur 2. En d’autres termes, il élimine un pas de temps sur deux de la séquence cible. Le décodeur prédit alors une séquence deux fois plus longue. Étant donné que la longueur de la séquence cible d’origine peut être impaire, l’assembleur de données veille à arrondir la longueur maximale du batch à un multiple de 2.
data_collator = TTSDataCollatorWithPadding(processor=processor)
Entraîner le modèle
Chargez le modèle pré-entraîné à partir du même checkpoint que celui utilisé pour le chargement du processeur :
from transformers import SpeechT5ForTextToSpeech
model = SpeechT5ForTextToSpeech.from_pretrained(checkpoint)L’option use_cache=True est incompatible avec le checkingpointing du gradient. Désactivez-la pour l’entraînement, et réactivez le cache pour la génération afin d’accélérer le temps d’inférence :
from functools import partial
# désactiver le cache pendant l'entraînement car il est incompatible avec le checkpointing du gradient
model.config.use_cache = False
# définir la langue et la tâche pour la génération et réactiver le cache
model.generate = partial(model.generate, use_cache=True)Définir les arguments d’entraînement. Ici, nous ne calculons aucune métrique d’évaluation pendant le processus d’entraînement, nous parlerons d’évaluation plus tard dans ce chapitre. Au lieu de cela, nous ne nous intéresserons qu’à la perte :
from transformers import Seq2SeqTrainingArguments
training_args = Seq2SeqTrainingArguments(
output_dir="speecht5_finetuned_voxpopuli_nl", # changer pour un nom de dépôt de votre choix
per_device_train_batch_size=4,
gradient_accumulation_steps=8,
learning_rate=1e-5,
warmup_steps=500,
max_steps=4000,
gradient_checkpointing=True,
fp16=True,
evaluation_strategy="steps",
per_device_eval_batch_size=2,
save_steps=1000,
eval_steps=1000,
logging_steps=25,
report_to=["tensorboard"],
load_best_model_at_end=True,
greater_is_better=False,
label_names=["labels"],
push_to_hub=True,
)Instancie l’objet Trainer et lui passe le modèle, le jeu de données et l’assembleur de données.
from transformers import Seq2SeqTrainer
trainer = Seq2SeqTrainer(
args=training_args,
model=model,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
data_collator=data_collator,
tokenizer=processor,
)Et voilà, nous sommes prêts à commencer l’entraînement ! Il prendra plusieurs heures. En fonction de votre GPU, il est possible que vous rencontriez une erreur CUDA “out-of-memory” lorsque vous commencez l’entraînement. Dans ce cas, vous pouvez réduire la taille de per_device_train_batch_size par incréments d’un facteur 2 et augmenter gradient_accumulation_steps par 2 pour compenser.
trainer.train()
Pousser le modèle final sur le Hub :
trainer.push_to_hub()
Inférence
Une fois que vous avez finetuné un modèle, vous pouvez l’utiliser pour l’inférence ! Chargez le modèle à partir du Hub (assurez-vous d’utiliser votre nom de compte dans l’extrait de code suivant) :
model = SpeechT5ForTextToSpeech.from_pretrained(
"YOUR_ACCOUNT/speecht5_finetuned_voxpopuli_nl"
)Choisissez un exemple, ici nous en prendrons un du jeu de données de test. Obtenez un enchâssement du locuteur.
example = dataset["test"][304]
speaker_embeddings = torch.tensor(example["speaker_embeddings"]).unsqueeze(0)Définir un texte d’entrée et le tokeniser.
text = "hallo allemaal, ik praat nederlands. groetjes aan iedereen!"Prétraiter le texte d’entrée :
inputs = processor(text=text, return_tensors="pt")Installez un vocodeur et générez de la parole :
from transformers import SpeechT5HifiGan
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan")
speech = model.generate_speech(inputs["input_ids"], speaker_embeddings, vocoder=vocoder)On écoute le résultat ?
from IPython.display import Audio
Audio(speech.numpy(), rate=16000)Il peut être difficile d’obtenir des résultats satisfaisants avec ce modèle dans une nouvelle langue. La qualité de l’enchâssement du locuteur peut être un facteur important. Comme SpeechT5 a été entraîné avec des X-vectors anglais, il donne de meilleurs résultats lorsqu’il utilise des enchâssements de locuteurs anglais. Si la synthèse vocale semble médiocre, essayez d’utiliser un autre enchâssement de locuteur.
L’augmentation de la durée d’entraînement est également susceptible d’améliorer la qualité des résultats. Malgré cela, le discours est clairement néerlandais et non anglais, et il capture les caractéristiques vocales du locuteur (comparez avec l’audio original dans l’exemple).
Une autre chose à expérimenter est la configuration du modèle. Par exemple, essayez d’utiliser config.reduction_factor = 1 pour voir si cela améliore les résultats.
Dans la section suivante, nous verrons comment nous évaluons les modèles de synthèse vocale.
< > Update on GitHub