Modèles pré-entraînés pour la synthèse vocale
Par rapport aux tâches de reconnaissance automatique de la parole et de classification audio, il y a beaucoup moins de checkpoints de modèles pré-entraînés disponibles. Vous trouverez près de 300 sur le Hub. Parmi ces modèles pré-entraînés, nous nous concentrerons sur deux architectures qui sont facilement disponibles dans la bibliothèque 🤗 Transformers : SpeechT5 et Massive Multilingual Speech (MMS). Dans cette section, nous allons explorer comment utiliser ces modèles.
SpeechT5
[SpeechT5] (https://arxiv.org/abs/2110.07205) est un modèle publié par Junyi Ao et al. de Microsoft qui est capable de gérer une série de tâches vocales. Bien que dans cette unité, nous nous concentrions sur l’aspect texte-parole, ce modèle peut être adapté à des tâches de parole-texte (reconnaissance automatique de la parole ou identification du locuteur), ainsi qu’à des tâches de parole-parole (par exemple, amélioration de la parole ou conversion entre différentes voix). Ceci est dû à la façon dont le modèle est conçu et pré-entraîné.
Au cœur de SpeechT5 se trouve un transformer encodeur-décodeur classique. Ce réseau modélise une transformation de séquence à séquence en utilisant des représentations cachées. Ce transformer est le même pour toutes les tâches prises en charge par SpeechT5.
Il est complété par six pré ou post-réseaux modaux spécifiques (parole/texte). La parole ou le texte en entrée (en fonction de la tâche) est prétraité par un pré-réseau correspondant afin d’obtenir les représentations cachées que le transformer peut utiliser. La sortie obtenue est ensuite transmise à un post-réseau qui l’utilisera pour générer la sortie dans la modalité cible.
Voici à quoi ressemble l’architecture (image tirée de l’article original) :
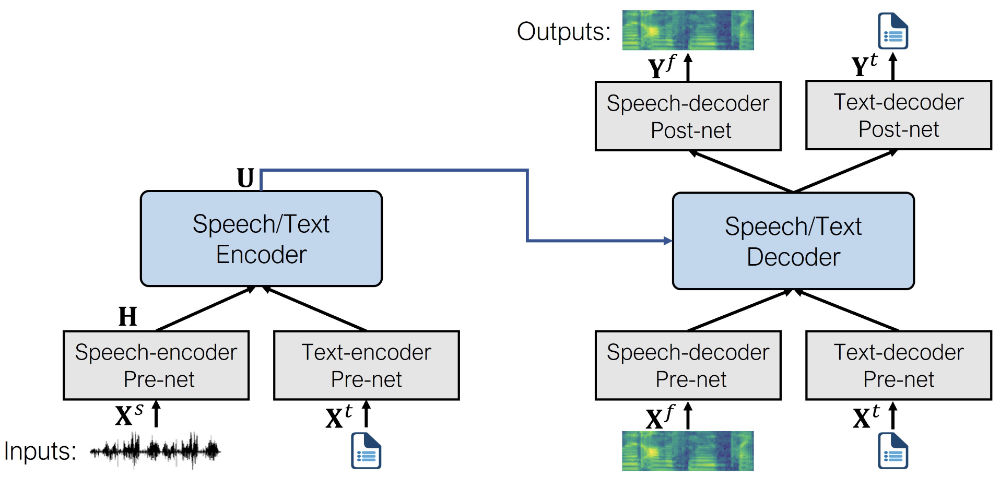
SpeechT5 est d’abord pré-entraîné à l’aide de données vocales et textuelles non étiquetées en grande quantité afin d’acquérir une représentation unifiée des différentes modalités. Pendant la phase de pré-entraînement, tous les pré-réseaux et post-réseaux sont utilisés simultanément.
Après le pré-entraînement, le réseau encodeur-décodeur finetuné pour chaque tâche individuelle. À cette étape, seuls les pré- et post-réseaux pertinents pour la tâche spécifique sont utilisés. Par exemple, pour utiliser SpeechT5 pour la synthèse vocale, vous aurez besoin du pré-réseau encodeur de texte pour les entrées de texte et des pré-réseaux et post-réseaux du décodeur de parole pour les sorties de parole.
Cette approche permet d’obtenir plusieurs modèles finetunés pour différentes tâches vocales qui bénéficient tous du pré-entraînement initial sur des données non étiquetées.
Même si les modèles finetunés commencent par utiliser le même ensemble de poids provenant du modèle pré-entraîné partagé, les versions finales sont toutes très différentes au bout du compte. Vous ne pouvez pas prendre un modèle ASR finetuné et échanger les pré- et post-réseaux pour obtenir un modèle de TTS fonctionnel, par exemple. SpeechT5 est flexible, mais pas à ce point ;)
Voyons quels sont les pré- et post-réseaux que SpeechT5 utilise pour la tâche de TTS :
- Pré-réseau encodeur de texte : Une couche d’enchâssement de texte qui fait correspondre les tokens de texte aux représentations cachées que l’encodeur attend. Ceci est similaire à ce qui se passe dans un modèle NLP tel que BERT.
- Pré-réseau de décodage de la parole : Il prend en entrée un spectrogramme log-mel et utilise une séquence de couches linéaires pour compresser le spectrogramme en représentations cachées.
- Post-réseau décodeur de la parole : Il prédit un résidu à ajouter au spectrogramme de sortie et est utilisé pour affiner les résultats.
Une fois combinée, voici à quoi ressemble l’architecture SpeechT5 pour la synthèse vocale :
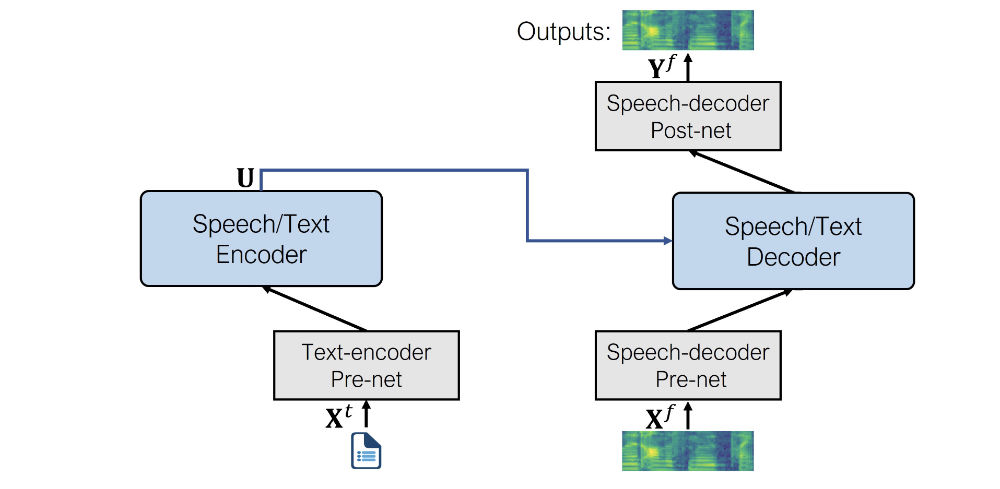
Comme vous pouvez le constater, la sortie est un spectrogramme log mel et non une forme d’onde. Si vous vous souvenez, nous avons brièvement abordé ce sujet dans l’unité 3. Il est courant que les modèles qui génèrent de l’audio produisent un spectrogramme log mel, qui doit être converti en forme d’onde à l’aide d’un réseau neuronal supplémentaire appelé vocodeur.
Voyons comment procéder.
Tout d’abord, chargeons le SpeechT5 finetuné sur du TTS depuis le Hub, ainsi que l’objet processeur utilisé pour la tokenisation et l’extraction de caractéristiques :
from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts")
model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts")Ensuite, le texte d’entrée est tokenisé.
inputs = processor(text="Don't count the days, make the days count.", return_tensors="pt")Le SpeechT5 TTS n’est pas limité à la création de discours pour un seul locuteur. Il utilise en effet ce que l’on appelle des ” enchâssements de locuteurs, qui capturent les caractéristiques de la voix d’un locuteur particulier.
L’enchâssement des locuteurs est une méthode permettant de représenter l’identité d’un locuteur de manière compacte, sous la forme d’un vecteur de taille fixe, quelle que soit la longueur de l’énoncé. Ces enchâssements capturent des informations essentielles sur la voix d’un locuteur, son accent, son intonation et d’autres caractéristiques uniques qui distinguent un locuteur d’un autre. De tels enregistrements peuvent être utilisés pour la vérification du locuteur, la diarisation du locuteur, l’identification du locuteur, etc. Les techniques les plus courantes pour générer des enchâssements de locuteurs sont les suivantes :
- Les I-Vecteurs (vecteurs d’identité) : ils sont basés sur un modèle de mélange gaussien (GMM). Ils représentent les locuteurs sous la forme de vecteurs de faible dimension et de longueur fixe, dérivés des statistiques d’un GMM spécifique au locuteur, et sont obtenus de manière non supervisée.
- Les vecteurs X : ils sont dérivés à l’aide de réseaux neuronaux profonds (DNN) et capturent des informations sur le locuteur au niveau de l’image en incorporant le contexte temporel.
X-Vectors est une méthode de pointe qui montre des performances supérieures sur des jeux de données d’évaluation par rapport aux I-Vectors. Le réseau neuronal profond est utilisé pour obtenir les X-Vecteurs : il est entraîné à discriminer les locuteurs, et fait correspondre des énoncés de longueur variable à des enchâssements de dimension fixe. Vous pouvez également charger un enchâssement de locuteur X-Vector qui a été calculé à l’avance et qui encapsule les caractéristiques d’élocution d’un locuteur particulier.
Chargeons un tel enchâssement de locuteur à partir d’un jeu de données sur le Hub. Les enchâssements ont été obtenus à partir du jeu de données CMU ARCTIC en utilisant ce script, mais n’importe quel enchâssement X-Vector devrait fonctionner.
from datasets import load_dataset
embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
import torch
speaker_embeddings = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0)L’enchâssement du locuteur est un tenseur de forme (1, 512). Cette représentation particulière du locuteur décrit une voix féminine.
À ce stade, nous disposons déjà de suffisamment d’entrées pour générer un log mel spectrogramme en sortie :
spectrogram = model.generate_speech(inputs["input_ids"], speaker_embeddings)Il en résulte un tenseur de forme (140, 80) contenant un log mel spectrogramme. La première dimension est la longueur de la séquence, et elle peut varier d’une exécution à l’autre car le pré-réseau décodeur de parole applique toujours un dropout à la séquence d’entrée. Cela ajoute un peu de variabilité aléatoire à la parole générée.
Cependant, si nous cherchons à générer une forme d’onde de la parole, nous devons spécifier un vocodeur à utiliser pour la conversion du spectrogramme en forme d’onde. En théorie, vous pouvez utiliser n’importe quel vocodeur qui fonctionne sur des mel spectrogrammes 80-bin. De manière pratique, 🤗 Transformers propose un vocodeur basé sur HiFi-GAN. Ses poids ont été aimablement fournis par les auteurs originaux de SpeechT5.
HiFi-GAN est un réseau antagoniste génératif (GAN) de pointe conçu pour de la synthèse vocale haute-fidélité. Il est capable de générer des formes d’ondes audio réalistes et de haute qualité à partir de spectrogrammes.
À un niveau élevé, HiFi-GAN se compose d’un générateur et de deux discriminateurs. Le générateur est un réseau neuronal entièrement convolutionnel qui prend un mel spectrogramme en entrée et apprend à produire des formes d’ondes audio brutes. Les discriminateurs ont pour rôle de faire la distinction entre l’audio réel et l’audio généré. Les deux discriminateurs se concentrent sur des aspects différents de l’audio.
HiFi-GAN est entraîné sur un grand jeu de données d’enregistrements audio de haute qualité. Il utilise un entraînement dit antagoniste, dans lequel les réseaux du générateur et du discriminateur sont en compétition l’un contre l’autre. Au départ, le générateur produit un son de faible qualité et le discriminateur peut facilement le différencier du son réel. Au fur et à mesure que l’entraînement progresse, le générateur améliore sa sortie, dans le but de tromper le discriminateur. Le discriminateur, à son tour, devient plus précis dans la distinction entre le son réel et le son généré. Cette boucle de rétroaction antagoniste permet aux deux réseaux de s’améliorer au fil du temps. En fin de compte, HiFi-GAN apprend à générer un son de haute fidélité qui ressemble étroitement aux caractéristiques des données entraînées.
Le chargement du vocodeur est aussi simple que n’importe quel autre modèle de 🤗 Transformers.
from transformers import SpeechT5HifiGan
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan")Il ne vous reste plus qu’à le passer en argument lors de la génération de la parole, et les sorties seront automatiquement converties en forme d’onde de la parole.
speech = model.generate_speech(inputs["input_ids"], speaker_embeddings, vocoder=vocoder)Écoutons le résultat. La fréquence d’échantillonnage utilisée par SpeechT5 est toujours de 16 kHz.
from IPython.display import Audio
Audio(speech, rate=16000)Super !
N’hésitez pas à jouer avec la démo de SpeechT5 TSS, à explorer d’autres voix, à expérimenter avec les entrées. Notez que ce checkpoint pré-entraîné ne prend en charge que la langue anglaise :
Massive Multilingual Speech (MMS)
Que faire si vous recherchez un modèle pré-entraîné dans une langue autre que l’anglais ? Massive Multilingual Speech (MMS) est un autre modèle qui couvre un large éventail de tâches vocales, mais qui prend en charge un grand nombre de langues. Par exemple, il peut synthétiser la parole dans plus de 1 100 langues.
MMS pour la synthèse vocale est basé sur [VITS Kim et al., 2021] (https://arxiv.org/pdf/2106.06103.pdf), qui est l’une des approches TTS les plus modernes.
VITS est un réseau de génération de parole qui convertit le texte en formes d’ondes vocales brutes. Il fonctionne comme un auto-encodeur variationnel conditionnel, estimant les caractéristiques audio à partir du texte d’entrée. Tout d’abord, les caractéristiques acoustiques, représentées sous forme de spectrogrammes, sont générées. La forme d’onde est ensuite décodée à l’aide de couches convolutives transposées adaptées de HiFi-GAN. Pendant l’inférence, les encodages du texte sont suréchantillonnés et transformés en formes d’onde à l’aide du module de flux et du décodeur HiFi-GAN. Cela signifie que vous n’avez pas besoin d’ajouter un vocodeur pour l’inférence, il est déjà “intégré”.
Essayons le modèle et voyons comment nous pouvons synthétiser de la parole dans une langue autre que l’anglais, par exemple l’allemand. Tout d’abord, nous allons charger le checkpoint du modèle et le tokenizer pour la bonne langue :
from transformers import VitsModel, VitsTokenizer
model = VitsModel.from_pretrained("facebook/mms-tts-deu")
tokenizer = VitsTokenizer.from_pretrained("facebook/mms-tts-deu")Vous pouvez remarquer que pour charger le MMS, vous devez utiliser VitsModel et VitsTokenizer. C’est parce que le MMS pour la synthèse vocale est basé sur le modèle VITS comme mentionné précédemment.
Prenons un exemple de texte en allemand, comme ces deux premières lignes d’une chanson pour enfants :
text_example = (
"Ich bin Schnappi das kleine Krokodil, komm aus Ägypten das liegt direkt am Nil."
)Pour générer une forme d’onde, il faut prétraiter le texte à l’aide du tokenizer et le transmettre au modèle :
import torch
inputs = tokenizer(text_example, return_tensors="pt")
input_ids = inputs["input_ids"]
with torch.no_grad():
outputs = model(input_ids)
speech = outputs.audio[0]Écoutons :
from IPython.display import Audio
Audio(speech, rate=16000)Superbe ! Si vous souhaitez essayer MMS avec une autre langue, trouvez d’autres checkpoints vits appropriés sur le [Hub] (https://huggingface.co/models?filter=vits).
Voyons maintenant comment vous pouvez vous-même finetuner un modèle TTS !
< > Update on GitHub