Audio Course documentation
Modèles et jeux de données pré-entraînés pour la classification d’audio
Modèles et jeux de données pré-entraînés pour la classification d’audio
Le Hub abrite plusieurs centaines de modèles pré-entraînés pour la classification d’audio. Dans cette section, nous passerons en revue certaines des tâches de classification d’audio les plus courantes et suggérerons des modèles pré-entraînés appropriés pour chacune. En utilisant la classe pipeline(), la commutation entre les modèles et les tâches est simple : une fois que vous savez comment utiliser pipeline() pour un modèle, vous pourrez l’utiliser pour n’importe quel modèle sur le Hub, sans modification du code ! Cela rend l’expérimentation de la classe pipeline() extrêmement rapide, ce qui vous permet de sélectionner rapidement le meilleur modèle pré-entraîné pour vos besoins.
Avant de passer aux différents problèmes de classification d’audio, récapitulons rapidement les architectures de transformers généralement utilisées. L’architecture standard de classification d’audio est motivée par la nature de la tâche. Nous voulons transformer une séquence d’entrées audio (c’est-à-dire notre réseau audio d’entrée) en une prédiction d’étiquette de classe unique. Les modèles d’encodeur associent d’abord la séquence audio d’entrée dans une séquence de représentations à l’état caché en faisant passer les entrées à travers un bloc transformer. La séquence de représentations d’états masqués est ensuite associée à une sortie d’étiquette de classe en prenant la moyenne sur les états masqués et en faisant passer le vecteur résultant à travers une couche de classification linéaire. Par conséquent, il y a une préférence pour les modèles encodeur pour la classification d’audio.
Les modèles de décodeur introduisent une complexité inutile à la tâche car ils supposent que les sorties peuvent également être une séquence de prédictions (plutôt qu’une prédiction d’étiquette de classe unique), et génèrent ainsi plusieurs sorties. Par conséquent, ils ont une vitesse d’inférence plus lente et ont tendance à ne pas être utilisés. Les modèles encodeur-décodeur sont largement omis pour la même raison. Ces choix d’architecture sont analogues à ceux de NLP, où les modèles d’encodeur tels que BERT sont privilégiés pour les tâches de classification de séquences, et les modèles de décodeur tels que GPT réservés aux tâches de génération de séquences.
Maintenant que nous avons récapitulé l’architecture du transformer standard pour la classification d’audio, passons aux différents sous-ensembles de la classification d’audio et couvrons les modèles les plus populaires !
🤗 Installation de Transformers
Au moment de la rédaction de cette section, les dernières mises à jour requises pour le pipeline de classification d’audio se trouvent uniquement sur la version « principale » du dépôt 🤗 Transformers, plutôt que sur la dernière version de PyPi. Pour nous assurer que nous avons ces mises à jour localement, nous allons installer Transformers à partir de la branche main avec la commande suivante :
pip install git+https://github.com/huggingface/transformersRepérage de mots-clés
Le repérage de mots clés (KWS pour Keyword spotting) est la tâche d’identifier un mot-clé dans un discours. L’ensemble des mots-clés possibles forme l’ensemble des étiquettes de classe prédites. Par conséquent, pour utiliser un modèle de repérage de mots clés pré-entraîné, vous devez vous assurer que vos mots-clés correspondent à ceux sur lesquels le modèle a été pré-entraîné. Ci-dessous, nous présenterons deux jeux de données et modèles pour la détection de mots clés.
MINDS-14
Commençons en utilisant le même jeu de données MINDS-14 exploré dans l’unité précédente. Si vous vous souvenez, MINDS-14 contient des enregistrements de personnes posant des questions à un système bancaire électronique dans plusieurs langues et dialectes, et a indique une classe d’intention pour chaque enregistrement. Nous pouvons donc classer les enregistrements par intention de l’appel.
from datasets import load_dataset
minds = load_dataset("PolyAI/minds14", name="en-AU", split="train")Nous allons charger le checkpoint "anton-l/xtreme_s_xlsr_300m_minds14", qui est un modèle XLS-R finetuné sur MINDS-14 pendant environ 50 époques. Il atteint une précision de 90% sur toutes les langues de MINDS-14 sur l’ensemble d’évaluation.
from transformers import pipeline
classifier = pipeline(
"audio-classification",
model="anton-l/xtreme_s_xlsr_300m_minds14",
)Enfin, nous pouvons passer un échantillon au pipeline de classification pour faire une prédiction :
classifier(minds[0]["path"])Sortie :
[
{"score": 0.9631525278091431, "label": "pay_bill"},
{"score": 0.02819698303937912, "label": "freeze"},
{"score": 0.0032787492964416742, "label": "card_issues"},
{"score": 0.0019414445850998163, "label": "abroad"},
{"score": 0.0008378693601116538, "label": "high_value_payment"},
]Nous avons identifié que l’intention de l’appel était de payer une facture, avec une probabilité de 96%. Vous pouvez imaginer que ce type de système de repérage de mots-clés soit utilisé comme première étape d’un centre d’appels automatisé, où nous voulons catégoriser les appels entrants des clients en fonction de leur requête et leur offrir un support contextualisé en conséquence.
Speech Commands
Speech Commands est un jeu de données de mots parlés conçu pour évaluer les modèles de classification d’audio sur des mots de commande simples. Le jeu de données se compose de 15 classes de mots-clés, d’une classe pour le silence et d’une classe inconnue pour inclure le faux positif. Les 15 mots-clés sont des mots uniques qui seraient généralement utilisés dans les paramètres sur l’appareil pour contrôler les tâches de base ou lancer d’autres processus. Un modèle similaire fonctionne en continu sur votre téléphone mobile. Ici, au lieu d’avoir des mots de commande uniques, nous avons des mots de réveil spécifiques à votre appareil, tels que « Hey Google » ou « Hey Siri ». Lorsque le modèle de classification d’audio détecte ces mots de réveil, il déclenche votre téléphone pour commencer à écouter le microphone et transcrire votre discours à l’aide d’un modèle de reconnaissance vocale. Le modèle de classification d’audio est beaucoup plus petit et plus léger que le modèle de reconnaissance vocale, souvent seulement quelques millions de paramètres contre plusieurs centaines de millions pour la reconnaissance vocale. Ainsi, il peut fonctionner en continu sur votre appareil sans vider votre batterie ! Ce n’est que lorsque le mot de réveil est détecté que le modèle de reconnaissance vocale plus large est lancé, puis qu’il est à nouveau arrêté. Nous couvrirons les modèles de transformers pour la reconnaissance vocale dans la prochaine unité, donc à la fin du cours, vous devriez avoir les outils dont vous avez besoin pour construire votre propre assistant à commande vocale ! Comme pour tout jeu de données sur le Hub, nous pouvons avoir une idée de la tête des données sans avoir à les télécharger ou les avoir en mémoire. Après avoir accédé à la carte du jeu de données Speech Commands sur le Hub, nous pouvons utiliser la visionneuse de données pour faire défiler les 100 premiers échantillons du jeu de données, écouter les fichiers audio et vérifier toute autre information de métadonnées :
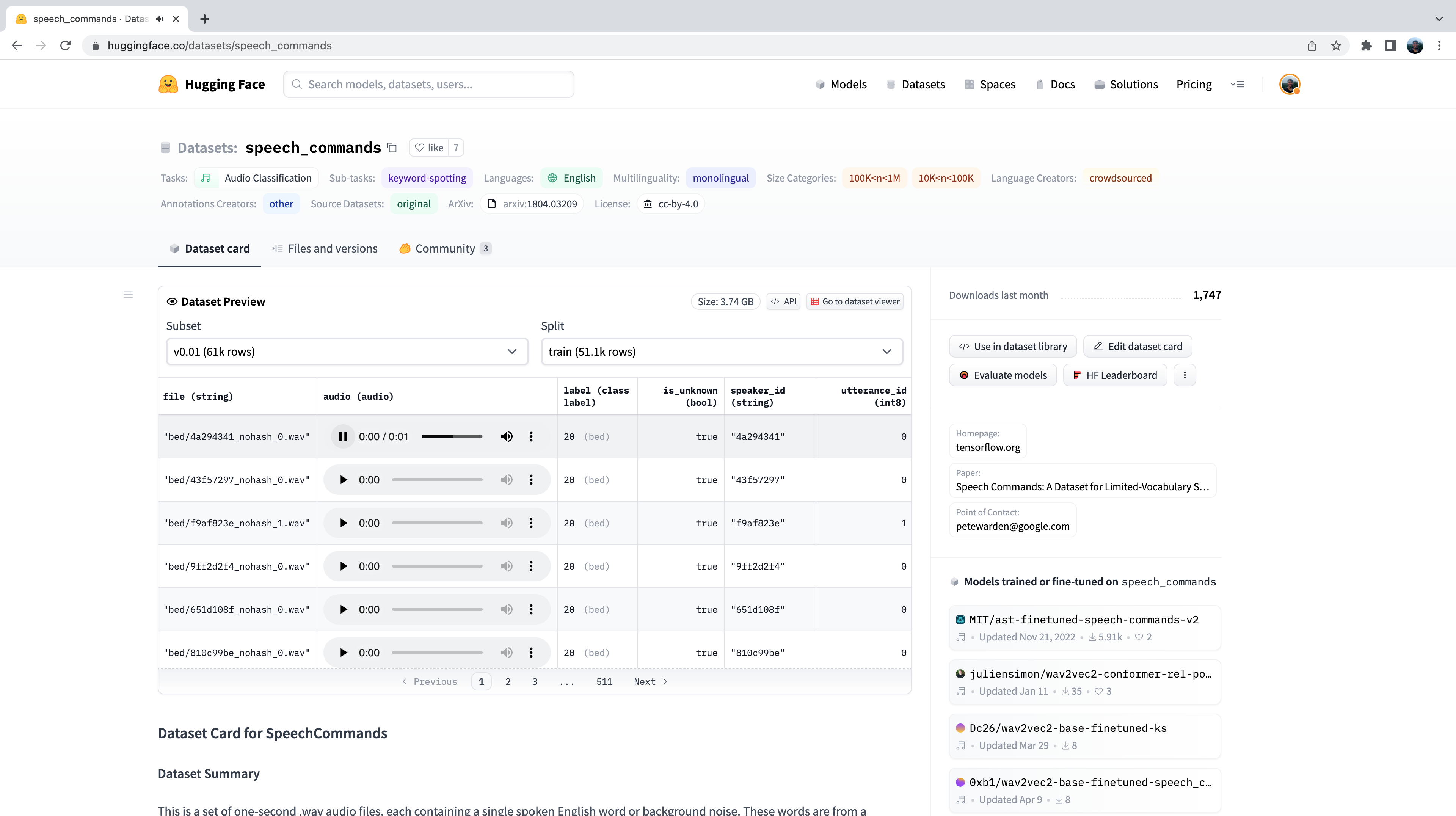
L’aperçu du jeu de données est un moyen de découvrir les jeux de données audio avant de s’engager à les utiliser. Vous pouvez choisir n’importe quel jeu de données sur le Hub, faire défiler les échantillons et écouter l’audio pour les différents sous-ensembles et échantillons, en évaluant s’il s’agit du bon jeu de données pour vos besoins. Une fois que vous avez sélectionné un jeu de données, il est trivial de télécharger les données afin de pouvoir commencer à les utiliser. Faisons cela et chargeons un échantillon du jeu de données Speech Commands en utilisant le mode streaming :
speech_commands = load_dataset(
"speech_commands", "v0.02", split="validation", streaming=True
)
sample = next(iter(speech_commands))Nous allons charger un checkpoint d’un transformer d’audio sous la forme de spectrogramme finetuné sur le jeu de données Speech Commands :
classifier = pipeline(
"audio-classification", model="MIT/ast-finetuned-speech-commands-v2"
)
classifier(sample["audio"].copy())Sortie :
[{'score': 0.9999892711639404, 'label': 'backward'},
{'score': 1.7504888774055871e-06, 'label': 'happy'},
{'score': 6.703040185129794e-07, 'label': 'follow'},
{'score': 5.805884484288981e-07, 'label': 'stop'},
{'score': 5.614546694232558e-07, 'label': 'up'}]On dirait que l’exemple contient le mot backward avec une forte probabilité. Nous pouvons écouter l’échantillon et vérifier qu’il est correct:
from IPython.display import Audio
Audio(sample["audio"]["array"], rate=sample["audio"]["sampling_rate"])Vous vous demandez peut-être comment nous avons sélectionné les modèles pré-entraînés montrés dans ces exemples de classification d’audio. C’est très simple ! La première chose que nous devons faire est de nous diriger sur le Hub et de cliquer sur l’onglet « Models »: https://huggingface.co/models Cela va faire apparaître tous les modèles sur le Hub :
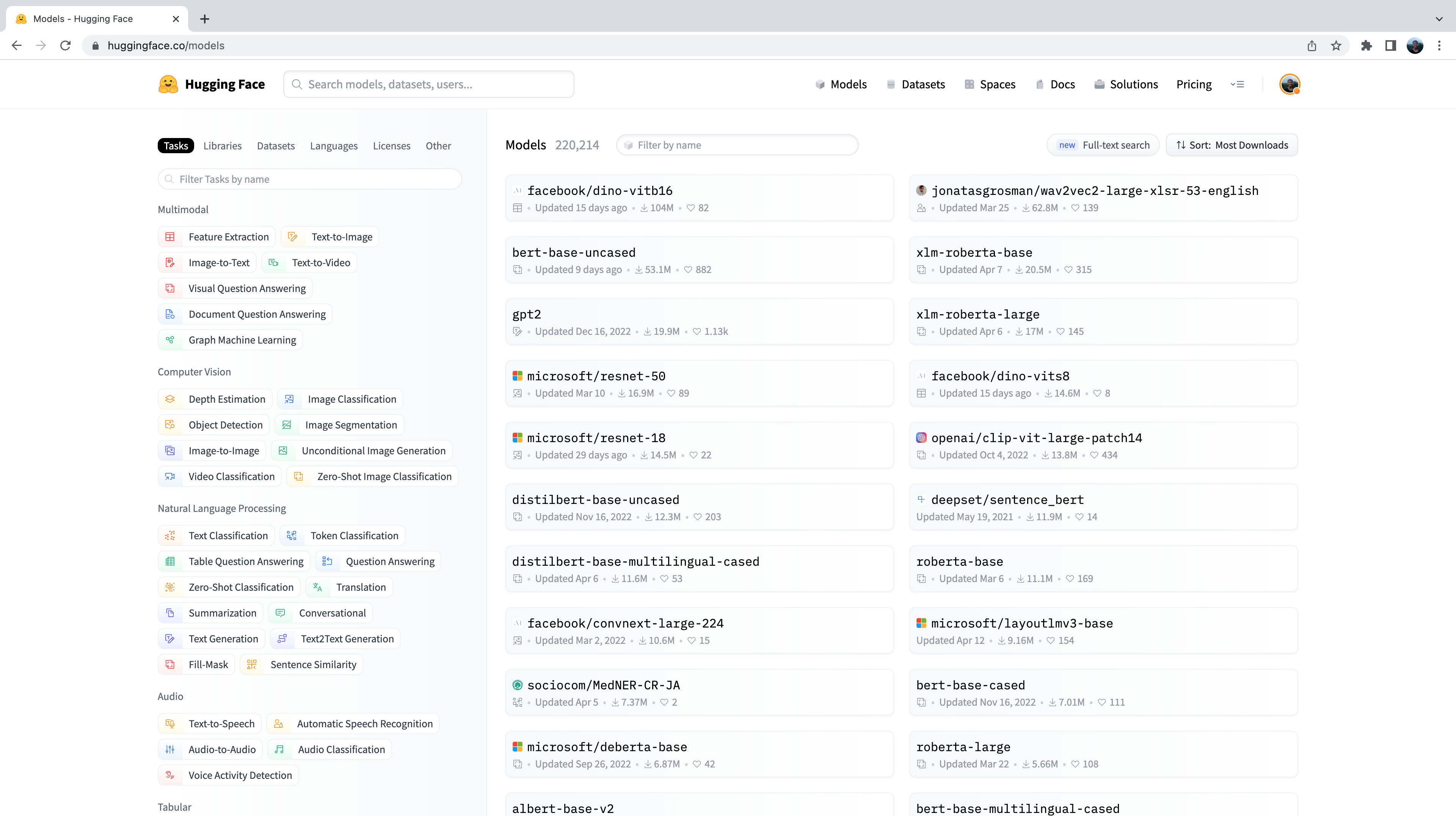
Vous remarquerez sur le côté gauche que nous avons plusieurs onglets que nous pouvons sélectionner pour filtrer les modèles par tâche, bibliothèque, jeu de données, etc. Faites défiler vers le bas et sélectionnez la tâche « Classification d’audio » dans la liste des tâches audio:
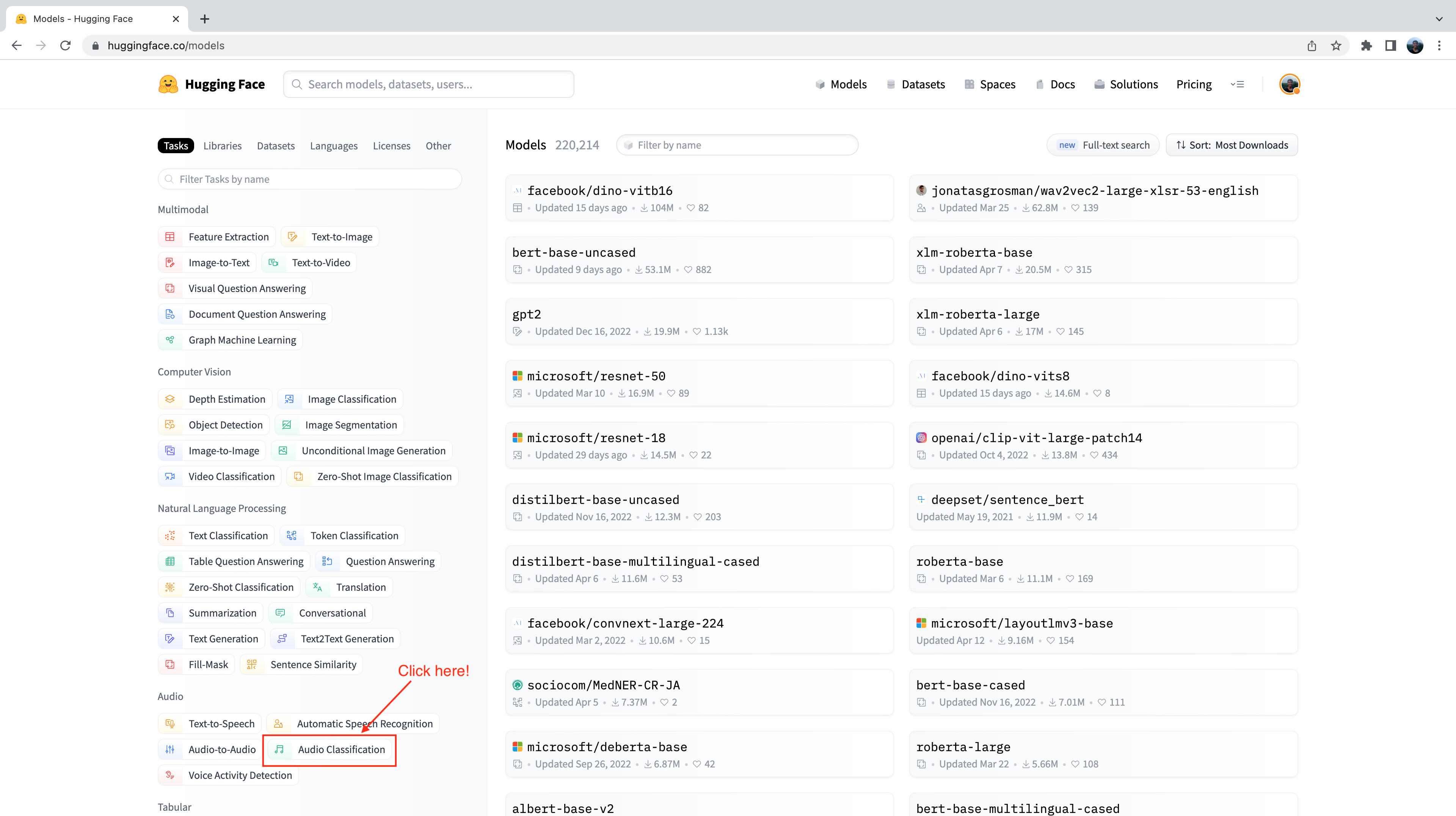
Nous voyons alors le sous-ensemble de modèles de classification d’audio présent sur le Hub. Pour affiner davantage cette sélection, nous pouvons filtrer les modèles par jeu de données. Cliquez sur l’onglet « Jeux de données », et dans la zone de recherche, tapez « speech_commands ». Lorsque vous commencez à taper, vous verrez la sélection pour ‘speech_commands’ apparaître sous l’onglet de recherche. Vous pouvez cliquer sur ce bouton pour filtrer tous les modèles de classification d’audio finetuné sur le jeu de données Speech Commands :
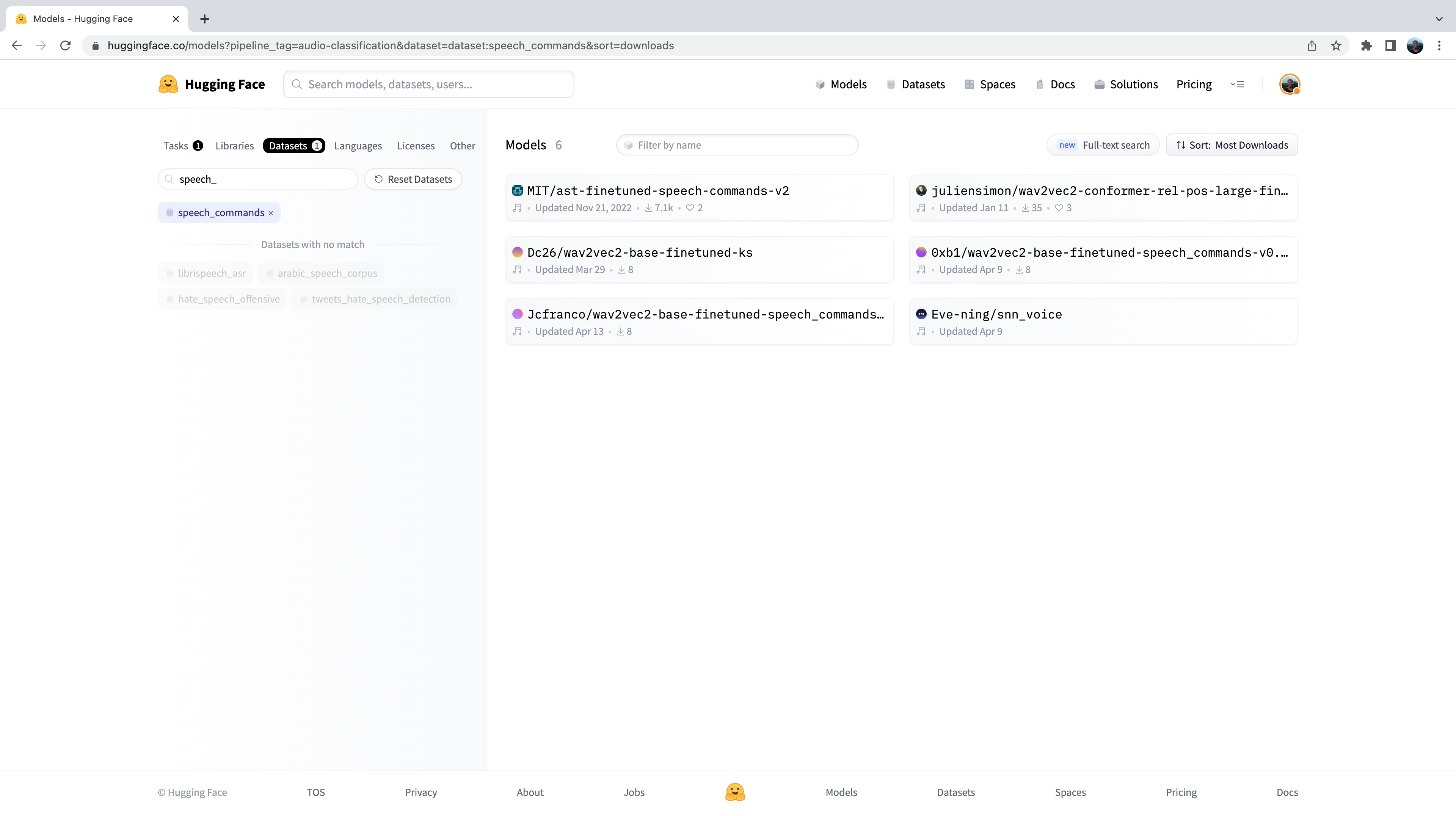
Bien, nous voyons que nous avons 6 modèles pré-entraînés à notre disposition pour ce jeu de données et cette tâche spécifiques. Le premier listé est celui que nous avons utilisé dans l’exemple précédent. Ce processus de filtrage des modèles du Hub est exactement la façon dont nous avons procédé pour choisir ce modèle.
Identification de la langue
L’identification de la langue est la tâche d’identifier la langue parlée dans un échantillon audio à partir d’une liste de langues candidates. Cette tâche peut jouer un rôle important dans de nombreux pipelines de parole. Par exemple, étant donné un échantillon audio dans une langue inconnue, un modèle d’identification de langue peut être utilisé pour catégoriser la ou les langues parlées dans l’échantillon audio, puis sélectionner un modèle de reconnaissance vocale approprié entraîné sur cette langue pour transcrire l’audio.
FLEURS
FLEURS (Few-shot Learning Evaluation of Universal Representations of Speech) est un jeu de données permettant d’évaluer les systèmes de reconnaissance vocale dans 102 langues, dont beaucoup sont classées comme à faibles ressources. Jetez un coup d’œil à la carte de FLEURS sur le Hub et explorez les différentes langues présentes : google/fleurs. Pouvez-vous trouver votre langue maternelle ici ? Si ce n’est pas le cas, quelle est la langue la plus proche ? Chargeons un échantillon à partir de l’échantillon de validation de FLEURS en utilisant le mode streaming :
fleurs = load_dataset("google/fleurs", "all", split="validation", streaming=True)
sample = next(iter(fleurs))Génial ! Nous pouvons maintenant charger notre modèle de classification d’audio. Pour cela, nous utiliserons une version de Whisper finetuné sur FLEURS, qui est actuellement le modèle de détection de langue le plus performant sur le Hub:
classifier = pipeline(
"audio-classification", model="sanchit-gandhi/whisper-medium-fleurs-lang-id"
)Nous pouvons ensuite passer l’audio à travers notre classifieur et générer une prédiction :
classifier(sample["audio"])Sortie :
[{'score': 0.9999330043792725, 'label': 'Afrikaans'},
{'score': 7.093023668858223e-06, 'label': 'Northern-Sotho'},
{'score': 4.269149485480739e-06, 'label': 'Icelandic'},
{'score': 3.2661141631251667e-06, 'label': 'Danish'},
{'score': 3.2580724109720904e-06, 'label': 'Cantonese Chinese'}]Nous pouvons voir que le modèle a prédit que l’audio était en Afrikaans avec une probabilité extrêmement élevée. FLEURS contient des données audio provenant d’un large éventail de langues : nous pouvons voir que les étiquettes de classe possibles incluent le sotho du Nord, l’islandais, le danois et le cantonais, entre autres. Vous pouvez trouver la liste complète des langues ici : google/fleurs. À vous de jouer ! Quels autres checkpoints pouvez-vous trouver sur le Hub afin de détecter les langues présentes dans FLEURS ? Quels modèles de transformers utilisent-ils sous le capot ?
Classification d’audio en zéro-shot
Dans le paradigme traditionnel de la classification d’audio, le modèle prédit une étiquette de classe à partir d’un ensemble de classes prédéfinies possibles. Cela constitue un obstacle à l’utilisation de modèles pré-entraînés pour la classification d’audio, car les étiquettes du modèle pré-entraîné doit correspondre à celui de la tâche en aval. Pour l’exemple précédent de détection de langues, le modèle doit prédire l’une des 102 classes de langue sur lesquelles il a été entraîné. Si la tâche en aval nécessite en fait 110 langues, le modèle ne serait pas en mesure de prédire 8 des 110 langues, et nécessiterait donc un nouvel entraînement pour atteindre une couverture complète. Cela limite l’efficacité de l’apprentissage par transfert pour les tâches de classification d’audio. La classification d’audio zéro-shot est une méthode permettant de prendre un modèle de classification d’audio pré-entraîné entraîné sur un ensemble d’exemples étiquetés et de lui permettre de classer de nouveaux exemples de classes inédites. Voyons comment nous pouvons y parvenir. Actuellement, 🤗 Transformers prend en charge un type de modèle pour la classification d’audio en zéro-shot : le modèle CLAP. CLAP est un modèle basé sur un transformer qui prend à la fois l’audio et le texte comme entrées, et calcule la similitude entre les deux. Si nous passons une entrée de texte fortement corrélée à une entrée audio, nous obtiendrons un score de similarité élevé. Inversement, passer une entrée de texte qui n’a aucun rapport avec l’entrée audio renverra une faible similitude. Nous pouvons utiliser cette prédiction de similarité pour la classification d’audio en zéro-shot en passant une entrée audio au modèle et plusieurs étiquettes candidates. Le modèle renverra un score de similarité pour chacune des étiquettes candidates, et nous pouvons choisir celle qui a le score le plus élevé comme prédiction.
Prenons un exemple où nous utilisons une entrée audio du jeu de données Environmental Speech Challenge (ESC) :
dataset = load_dataset("ashraq/esc50", split="train", streaming=True)
audio_sample = next(iter(dataset))["audio"]["array"]Nous définissons ensuite nos étiquettes candidates, qui forment l’ensemble des étiquettes de classification possibles. Le modèle renverra une probabilité de classification pour chacune des étiquettes que nous définissons. Cela signifie que nous devons connaître a-priori l’ensemble des étiquettes possibles dans notre problème de classification, de sorte que l’étiquette correcte soit contenue dans l’ensemble et se voie donc attribuer un score de probabilité valide. Notez que nous pouvons soit transmettre l’ensemble complet des étiquettes au modèle, soit un sous-ensemble sélectionné à la main qui, selon nous, contient l’étiquette correcte. Passer l’ensemble complet des étiquettes sera plus exhaustif, mais se fait au détriment d’une précision de classification plus faible puisque l’espace de classification est plus grand (à condition que l’étiquette correcte soit notre sous-ensemble d’étiquettes choisi):
candidate_labels = ["Sound of a dog", "Sound of vacuum cleaner"]Nous pouvons parcourir les deux modèles pour trouver l’étiquette candidate qui est la plus similaire à l’entrée audio:
classifier = pipeline(
task="zero-shot-audio-classification", model="laion/clap-htsat-unfused"
)
classifier(audio_sample, candidate_labels=candidate_labels)Sortie :
[{'score': 0.9997242093086243, 'label': 'Sound of a dog'}, {'score': 0.0002758323971647769, 'label': 'Sound of vacuum cleaner'}]Le modèle semble assez confiant (probabilité de 99,97%) que nous ayons le son d’un chien .Nous allons donc prendre cela comme notre prédiction. Confirmons si nous avions raison en écoutant l’échantillon audio (n’augmentez pas trop le volume, sinon vous risquez de sursauter !):
Audio(audio, rate=16000)Parfait ! Nous avons le son d’un chien qui aboie 🐕, ce qui correspond à la prédiction du modèle. Jouez avec différents échantillons audio et différentes étiquettes candidates. Pouvez-vous définir un ensemble d’étiquettes qui donnent une bonne généralisation à travers le jeu de données ESC ? Astuce : pensez à l’endroit où vous pourriez trouver des informations sur les sons possibles dans ESC et construisez vos étiquettes en conséquence. Vous vous demandez peut-être pourquoi nous n’utilisons pas le pipeline de classification d’audio zero-shot pour toutes les tâches de classification d’audio ? Il semble que nous puissions faire des prédictions pour n’importe quel problème de classification d’audio en définissant des étiquettes de classe appropriées à priori, contournant ainsi la contrainte dont notre tâche de classification a besoin pour correspondre aux étiquettes sur lesquelles le modèle a été pré-entraîné. Cela se résume à la nature du modèle CLAP utilisé dans le pipeline zéro-shot. CLAP est pré-entraîné sur des données de classification d’audio génériques, similaires aux sons environnementaux dans le jeu de données ESC, plutôt que sur des données vocales spécifiques, comme nous l’avions dans la tâche de détection de langue. Si vous lui donnez un discours en anglais et un discours en espagnol, CLAP saurait que les deux exemples étaient des données vocales. Mais il ne serait pas capable de différencier les langues de la même manière qu’un modèle de détection de langue dédié à cette tâche.
Et ensuite ?
Nous avons couvert un certain nombre de tâches de classification d’audio, présenté les jeux de données et les modèles les plus pertinents que vous pouvez télécharger à partir du Hub et comment les utiliser en quelques lignes de code à l’aide de la classe pipeline(). Ces tâches comprenent la détection de mots-clés, l’identification de la langue et la classification d’audio en zéro-shot.
Mais que se passe-t-il si nous voulons faire quelque chose de nouveau ? Nous avons beaucoup travaillé sur les tâches de traitement de la parole, mais ce n’est qu’un aspect de la classification d’audio. Un autre domaine populaire du traitement d’audio est la musique. Bien que la musique ait des caractéristiques intrinsèquement différentes à la parole, bon nombre des mêmes principes que nous avons déjà appris peuvent être appliqués.
Dans la section suivante, nous allons passer en revue un guide étape par étape sur la façon dont vous pouvez finetuner un transformer avec 🤗 Transformers sur la tâche de classification de la musique. À la fin, vous aurez un checkpoint finetuné que vous pourrez brancher dans la classe pipeline(), vous permettant de classer les chansons exactement de la même manière que nous avons classé la parole ici.