Charger et explorer un jeu de données audio
Dans ce cours, nous utiliserons la bibliothèque 🤗 Datasets pour travailler avec des jeux de données audio. 🤗 Datasets est une bibliothèque open-source permettant de télécharger et de préparer des jeux de données à partir de toutes les modalités, y compris l’audio. La bibliothèque offre un accès facile à une sélection inégalée de jeux de données d’apprentissage automatique accessibles sur Hugging Face Hub. De plus, 🤗 Datasets comprend de multiples fonctionnalités adaptées aux jeux de données audio simplifiant le travail avec de tels jeux de données pour les chercheurs et les praticiens. Pour commencer à utiliser des jeux de données audio, assurez-vous que la 🤗 Datasets est installée :
pip install datasets[audio]
L’une des principales caractéristiques déterminantes de 🤗 Datasets est la possibilité de télécharger et de préparer un jeu de données en une seule ligne de code Python à l’aide de la fonction load_dataset().
Chargeons et explorons un jeu de données audio appelé MINDS-14, qui contient des enregistrements de personnes posant des questions à un système bancaire électronique dans plusieurs langues et dialectes.
Pour charger le jeu de données MINDS-14, nous devons copier l’identifiant du jeu de données sur le Hub (PolyAI/minds14) et le transmettre à la fonction load_dataset.
Nous préciserons également que nous ne nous intéressons qu’au sous-ensemble australien (‘en-AU’) des données, et le limiterons à la division de l’entraînement :
from datasets import load_dataset
minds = load_dataset("PolyAI/minds14", name="en-AU", split="train")
mindsSortie :
Dataset(
{
features: [
"path",
"audio",
"transcription",
"english_transcription",
"intent_class",
"lang_id",
],
num_rows: 654,
}
)Le jeu de données contient 654 fichiers audio, chacun étant accompagné d’une transcription, d’une traduction en anglais et d’une étiquette indiquant l’intention derrière la requête de la personne. La colonne audio contient les données audio brutes. Examinons de plus près l’un des exemples:
example = minds[0]
exampleSortie :
{
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"audio": {
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"array": array(
[0.0, 0.00024414, -0.00024414, ..., -0.00024414, 0.00024414, 0.0012207],
dtype=float32,
),
"sampling_rate": 8000,
},
"transcription": "I would like to pay my electricity bill using my card can you please assist",
"english_transcription": "I would like to pay my electricity bill using my card can you please assist",
"intent_class": 13,
"lang_id": 2,
}Vous remarquerez peut-être que la colonne audio contient plusieurs caractéristiques :
path: le chemin d’accès au fichier audio (*.wavdans ce cas).array: les données audio décodées, représentées sous la forme d’un tableau NumPy à 1 dimension.sampling_rate: taux d’échantillonnage du fichier audio (8 000 Hz dans cet exemple). Leintent_classest une catégorie de classification de l’enregistrement audio. Pour convertir ce nombre en une chaîne significative, nous pouvons utiliser la méthodeint2str():
id2label = minds.features["intent_class"].int2str
id2label(example["intent_class"])Sortie :
"pay_bill"Si vous regardez la fonction de transcription, vous pouvez voir que le fichier audio a effectivement enregistré une personne posant une question sur le paiement d’une facture.
Si vous envisagez d’entraîner un classifieur audio sur ce sous-ensemble de données, vous n’aurez pas nécessairement besoin de toutes les caractéristiques.
Par exemple, le lang_id aura la même valeur pour tous les exemples et ne sera pas utile.
Les english_transcription dupliqueront probablement la transcription de ce sous-ensemble, afin que nous puissions les supprimer en toute sécurité.
Vous pouvez facilement supprimer les caractéristiques non pertinentes à l’aide de la méthode remove_columns de 🤗 Datasets :
columns_to_remove = ["lang_id", "english_transcription"]
minds = minds.remove_columns(columns_to_remove)
mindsSortie :
Dataset({features: ["path", "audio", "transcription", "intent_class"], num_rows: 654})Maintenant que nous avons chargé et inspecté le contenu brut du jeu de données, écoutons quelques exemples ! Nous utiliserons les fonctionnalités Blocs et Audio de Gradio pour décoder quelques échantillons aléatoires du jeu de données:
import gradio as gr
def generate_audio():
example = minds.shuffle()[0]
audio = example["audio"]
return (
audio["sampling_rate"],
audio["array"],
), id2label(example["intent_class"])
with gr.Blocks() as demo:
with gr.Column():
for _ in range(4):
audio, label = generate_audio()
output = gr.Audio(audio, label=label)
demo.launch(debug=True)Si vous le souhaitez, vous pouvez également visualiser certains des exemples. Traçons la forme d’onde pour le premier exemple.
import librosa
import matplotlib.pyplot as plt
import librosa.display
array = example["audio"]["array"]
sampling_rate = example["audio"]["sampling_rate"]
plt.figure().set_figwidth(12)
librosa.display.waveshow(array, sr=sampling_rate)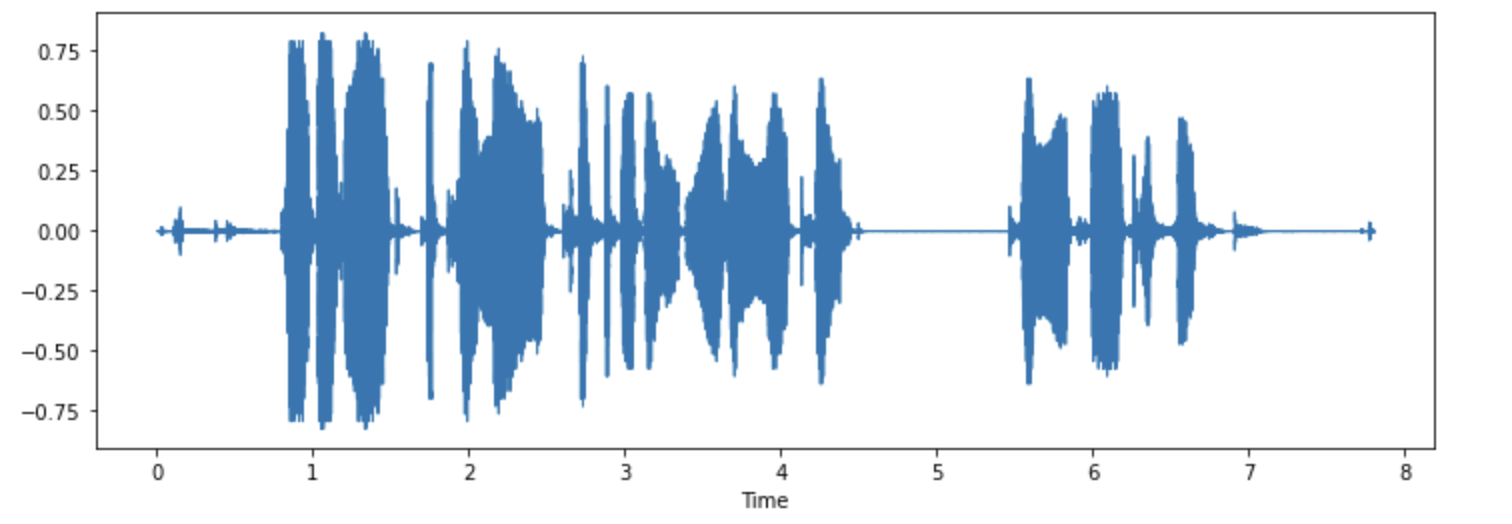
Essayez ! Téléchargez un autre dialecte ou une autre langue du jeu de données MINDS-14, écoutez et visualisez quelques exemples pour avoir une idée des variations du jeu de données. Vous pouvez trouver la liste complète des langues disponibles ici.
< > Update on GitHub