Audio Course documentation
Prétraitement d’un jeu de données audio
Prétraitement d’un jeu de données audio
Le chargement d’un jeu de données avec 🤗 Datasets n’est que la moitié du plaisir. Si vous prévoyez de l’utiliser pour entraîner un modèle ou pour exécuter l’inférence, vous devrez d’abord prétraiter les données. En général, cela impliquera les étapes suivantes:
- Rééchantillonnage des données audio
- Filtrage du jeu de données
- Conversion des données audio en entrée attendue du modèle
Rééchantillonnage des données audio
La fonction load_dataset télécharge des exemples audio avec le taux d’échantillonnage avec lequel ils ont été publiés.
Ce n’est pas toujours le taux d’échantillonnage attendu par un modèle que vous prévoyez d’entraîner ou d’utiliser pour l’inférence.
S’il existe un écart entre les taux d’échantillonnage, vous pouvez rééchantillonner l’audio à la fréquence d’échantillonnage attendue du modèle.
La plupart des modèles pré-entraînés disponibles ont été pré-entraînés sur des jeux de données audio à une fréquence d’échantillonnage de 16 kHz.
Lorsque nous avons exploré le jeu de données MINDS-14, vous avez peut-être remarqué qu’il est échantillonné à 8 kHz, ce qui signifie que nous devrons probablement le suréchantillonner.
Pour ce faire, utilisez la méthode cast_column de 🤗 Datasets.
Cette opération ne modifie pas l’audio sur place, mais plutôt les signaux aux jeux de données pour rééchantillonner les exemples audio à la volée lorsqu’ils sont chargés.
Le code suivant définira la fréquence d’échantillonnage à 16 kHz :
from datasets import Audio
minds = minds.cast_column("audio", Audio(sampling_rate=16_000))Rechargez le premier exemple audio dans le jeu de données MINDS-14 et vérifiez qu’il a été rééchantillonné à la « fréquence d’échantillonnage » souhaitée :
minds[0]Sortie :
{
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"audio": {
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"array": array(
[
2.0634243e-05,
1.9437837e-04,
2.2419340e-04,
...,
9.3852862e-04,
1.1302452e-03,
7.1531429e-04,
],
dtype=float32,
),
"sampling_rate": 16000,
},
"transcription": "I would like to pay my electricity bill using my card can you please assist",
"intent_class": 13,
}
Vous remarquerez peut-être que les valeurs de tableau sont maintenant également différentes. C’est parce que nous avons maintenant deux fois plus de valeurs d’amplitude pour chacune d’entre elles que nous avions auparavant.
Filtrage du jeu de données
Vous devrez peut-être filtrer les données en fonction de certains critères. L’un des cas courants consiste à limiter les exemples audio à une certaine durée.
Par exemple, nous pourrions vouloir filtrer tous les exemples de plus de 20 secondes pour éviter les erreurs de mémoire insuffisante lors de l’entraînement d’un modèle.
Nous pouvons le faire en utilisant la méthode filter de 🤗 Datasets et en lui passant une fonction avec une logique de filtrage. Commençons par écrire une fonction qui indique quels exemples conserver et lesquels rejeter.
Cette fonction, is_audio_length_in_range', renvoie Truesi un échantillon est inférieur à 20s etFalse` s’il est plus long que 20s.
MAX_DURATION_IN_SECONDS = 20.0
def is_audio_length_in_range(input_length):
return input_length < MAX_DURATION_IN_SECONDSLa fonction de filtrage peut être appliquée à la colonne d’un jeu de données, mais nous n’avons pas de colonne avec une durée de piste audio dans ce jeu de données. Cependant, nous pouvons en créer un, filtrer en fonction des valeurs de cette colonne, puis le supprimer.
# Utilisez librosa pour obtenir la durée de l'exemple à partir du fichier audio
new_column = [librosa.get_duration(path=x) for x in minds["path"]]
minds = minds.add_column("duration", new_column)
# utiliser la méthode `filter` de 🤗 Datasets pour appliquer la fonction de filtrage
minds = minds.filter(is_audio_length_in_range, input_columns=["duration"])
# supprimer la colonne d'assistance temporaire
minds = minds.remove_columns(["duration"])
mindsSortie :
Dataset({features: ["path", "audio", "transcription", "intent_class"], num_rows: 624})Nous pouvons vérifier que le jeu de données a été filtré de 654 exemples à 624.
Prétraitement des données audio
L’un des aspects les plus difficiles de l’utilisation d’ensembles de données audio consiste à préparer les données dans le bon format pour la formation des modèles. Comme vous l’avez vu, les données audio brutes se présentent sous la forme d’un tableau de valeurs d’échantillon. Cependant, les modèles pré-entraînés, que vous les utilisiez pour l’inférence ou que vous souhaitiez les finetuner pour votre tâche, s’attendent à ce que les données brutes soient converties en fonctionnalités d’entrée. Les exigences pour les caractéristiques d’entrée peuvent varier d’un modèle à l’autre. Elles dépendent de l’architecture du modèle et des données avec lesquelles il a été pré-entraîné. La bonne nouvelle est que, pour chaque modèle audio pris en charge, 🤗 Transformers offrent une classe d’extracteur de caractéristiques qui peut convertir les données audio brutes en caractéristiques d’entrée attendues par le modèle.
Alors, que fait un extracteur de caractéristiques avec les données audio brutes ? Jetons un coup d’œil à l’extracteur de caractéristiques de Whisper pour comprendre certaines transformations d’extraction de caractéristiques courantes. Whisper est un modèle pré-entraîné pour la reconnaissance vocale automatique (ASR) publié en septembre 2022 par Alec Radford et al. d’OpenAI. Tout d’abord, l’extracteur de fonction Whisper pave / tronque un batch d’exemples audio de sorte que tous les exemples ont une longueur d’entrée de 30s. Les exemples plus courts sont complétés à 30s en ajoutant des zéros à la fin de la séquence (les zéros dans un signal audio correspondent à l’absence de signal ou au silence). Les exemples de plus de 30 ans sont tronqués à 30 s. Étant donné que tous les éléments du batch sont rembourrés/tronqués à une longueur maximale dans l’espace d’entrée, il n’y a pas besoin d’un masque d’attention. Whisper est unique à cet égard, la plupart des autres modèles audio nécessitent un masque d’attention qui détaille où les séquences ont été rembourrées, et donc où elles doivent être ignorées dans le mécanisme d’auto-attention. Whisper est entraîné pour fonctionner sans masque d’attention et déduire directement des signaux vocaux où ignorer les entrées. La deuxième opération effectuée par l’extracteur de fonctions Whisper consiste à convertir les matrices audio rembourrées en spectrogrammes log-mel. Ces spectrogrammes décrivent comment les fréquences d’un signal changent au fil du temps, exprimées sur l’échelle mel et mesurées en décibels (la partie log) pour rendre les fréquences et les amplitudes plus représentatives de l’audition humaine. Toutes ces transformations peuvent être appliquées à vos données audio brutes avec quelques lignes de code. Allons de l’avant et chargeons l’extracteur de caractéristiques à partir du checkpoint de Whisper pré-entraîné pour être prêt pour nos données audio:
from transformers import WhisperFeatureExtractor
feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-small")Ensuite, vous pouvez écrire une fonction pour pré-traiter un seul exemple audio en le faisant passer par le feature_extractor.
def prepare_dataset(example):
audio = example["audio"]
features = feature_extractor(
audio["array"], sampling_rate=audio["sampling_rate"], padding=True
)
return featuresNous pouvons appliquer la fonction de préparation des données à tous nos exemples d’entraînement en utilisant la méthode map de 🤗 Datasets :
minds = minds.map(prepare_dataset)
mindsSortie :
Dataset(
{
features: ["path", "audio", "transcription", "intent_class", "input_features"],
num_rows: 624,
}
)Aussi simple que cela, nous avons maintenant des spectrogrammes log-mel comme input_features dans le jeu de données.
Visualisons-le pour l’un des exemples de minds :
import numpy as np
example = minds[0]
input_features = example["input_features"]
plt.figure().set_figwidth(12)
librosa.display.specshow(
np.asarray(input_features[0]),
x_axis="time",
y_axis="mel",
sr=feature_extractor.sampling_rate,
hop_length=feature_extractor.hop_length,
)
plt.colorbar()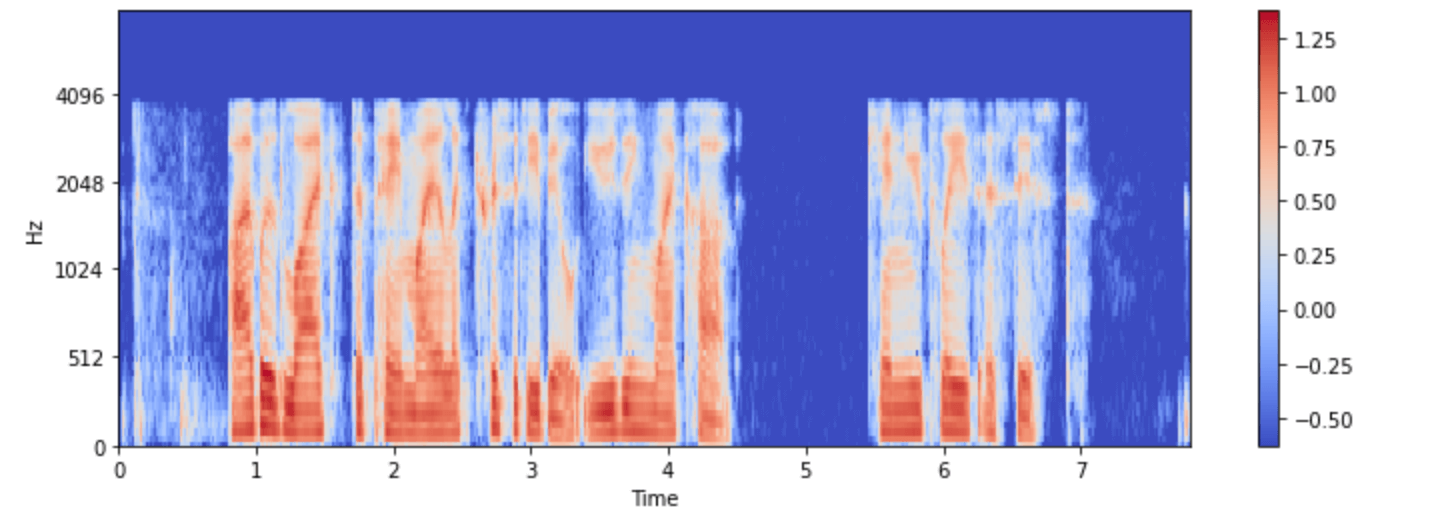
Vous pouvez maintenant voir à quoi ressemble l’entrée audio du modèle Whisper après le prétraitement.
La classe d’extracteur de caractéristiques du modèle se charge de transformer les données audio brutes au format attendu par le modèle. Cependant, de nombreuses tâches impliquant l’audio sont multimodales, par exemple la reconnaissance vocale. Dans de tels cas, 🤗 Transformers offrent également des tokeniseurs spécifiques au modèle pour traiter les entrées de texte. Pour une plongée approfondie dans les tokeniseurs, veuillez vous référer à notre cours de NLP.
Vous pouvez charger séparément l’extracteur de caractéristiques et le tokeniseur pour Whisper et d’autres modèles multimodaux, ou vous pouvez charger les deux via un processeur.
Pour rendre les choses encore plus simples, utilisez AutoProcessor pour charger l’extracteur de caractéristiques et le processeur d’un modèle à partir d’un checkpoint, comme ceci :
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("openai/whisper-small")Nous avons illustré ici les étapes fondamentales de préparation des données. Bien entendu, les données personnalisées peuvent nécessiter un prétraitement plus complexe.
Dans ce cas, vous pouvez étendre la fonction prepare_dataset pour effectuer n’importe quel type de transformations de données personnalisées.
Avec 🤗 Datasets, si vous pouvez l’écrire en tant que fonction Python, vous pouvez l’appliquer à votre jeu de données !