
Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming
🤗 Hugging Face | 📖 Github | 📑 Technical report
This is a safetensors conversion of gpt-omni/mini-omni.
Mini-Omni is an open-source multimodel large language model that can hear, talk while thinking. Featuring real-time end-to-end speech input and streaming audio output conversational capabilities.
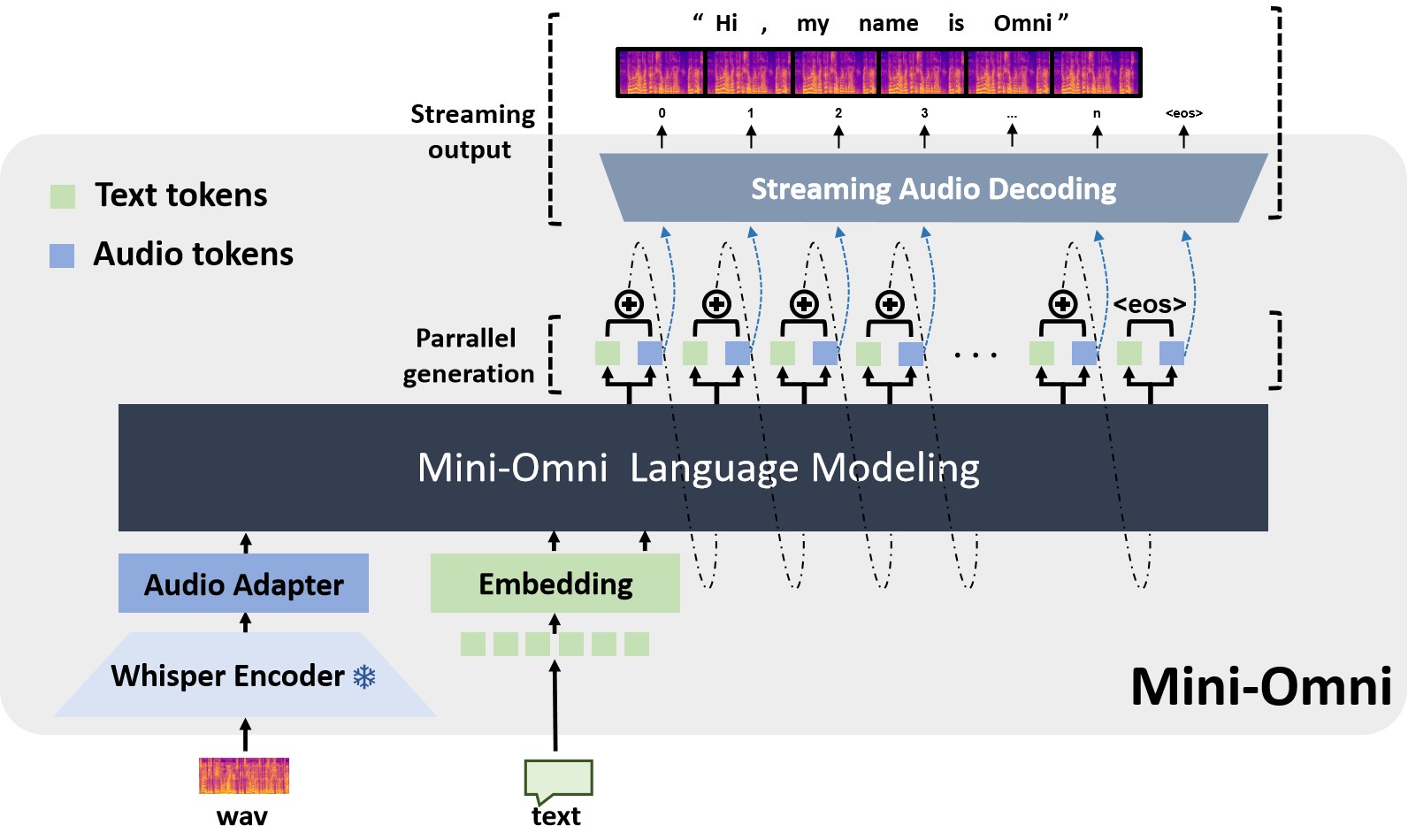
Features
✅ Real-time speech-to-speech conversational capabilities. No extra ASR or TTS models required.
✅ Talking while thinking, with the ability to generate text and audio at the same time.
✅ Streaming audio outupt capabilities.
✅ With "Audio-to-Text" and "Audio-to-Audio" batch inference to further boost the performance.
NOTE: please refer to https://github.com/gpt-omni/mini-omni for more details.
- Downloads last month
- 11
Model tree for leafspark/mini-omni-safetensors
Base model
Qwen/Qwen2-0.5B