
BGE-Large-En-V1.5-ONNX-O4
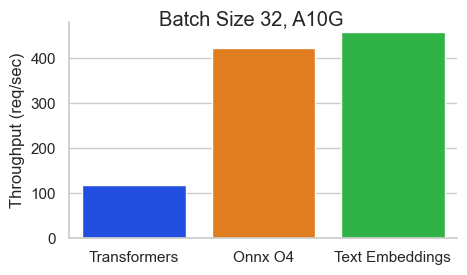
This is an ONNX O4 strategy optimized version of BAAI/bge-large-en-v1.5 optimal for Cuda. It should be much faster than the original
version.
Usage
# pip install "optimum[onnxruntime-gpu]" transformers
from optimum.onnxruntime import ORTModelForFeatureExtraction
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('hooman650/bge-large-en-v1.5-onnx-o4')
model = ORTModelForFeatureExtraction.from_pretrained('hooman650/bge-large-en-v1.5-onnx-o4')
model.to("cuda")
pairs = ["pandas usually live in the jungles"]
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
sentence_embeddings = model(**inputs)[0][:, 0]
# normalize embeddings
sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
- Downloads last month
- 20
Inference Providers
NEW
This model is not currently available via any of the supported Inference Providers.