
LVM-Med: Learning Large-Scale Self-Supervised Vision Models for Medical Imaging via Second-order Graph Matching (Neurips 2023).
We release LVM-Med's pre-trained models in PyTorch and demonstrate downstream tasks on 2D-3D segmentations, linear/fully finetuning image classification, and object detection.
LVM-Med was trained with ~ 1.3 million medical images collected from 55 datasets using a second-order graph matching formulation unifying current contrastive and instance-based SSL.
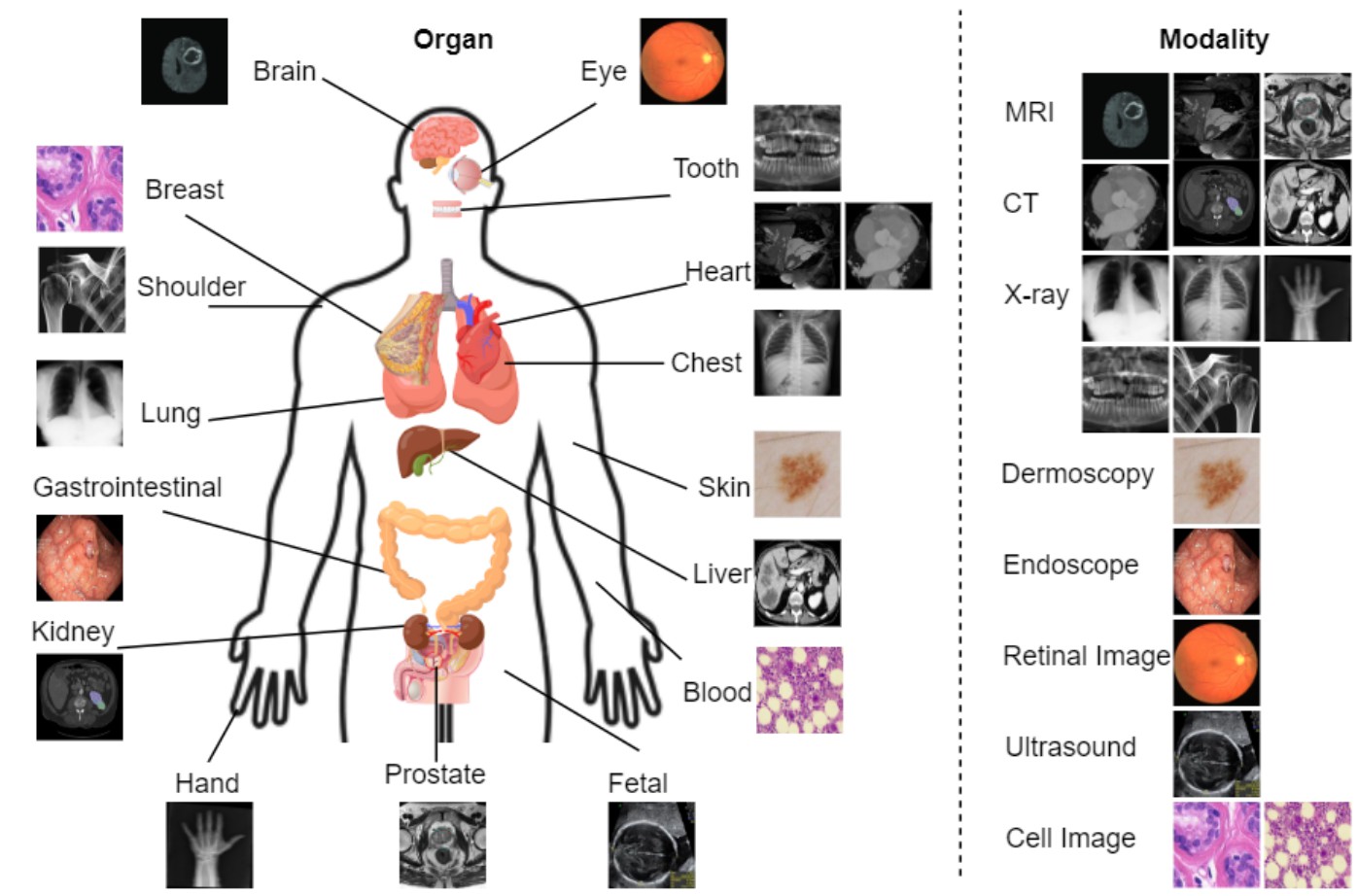

Table of contents
- News
- LVM-Med Pretrained Models
- Further Training LVM-Med on Large Dataset
- Prerequisites
- Preparing Dataset
- Downstream Tasks
- Citation
- Related Work
- License
News
- 14/12/2023: The LVM-Med training algorithm is ready to be released! Please send us an email to request!
- If you want to have other architecture, send us a request by email or create an Issue. If the requests are enough, we will train them.
- Coming soon: ConvNext architecture trained by LVM-Med.
- Coming soon: ViT architectures for end-to-end segmentation with better performance reported in the paper.
- 31/07/2023: Release ONNX support for LVM-Med ResNet50 and LVM-Med ViT as backbones in
onnx_modelfolder. - 26/07/2023: We release ViT architectures (ViT-B and ViT-H) initialized from LVM-Med and further training on the LIVECell dataset with 1.6 million high-quality cells. See at this table.
- 25/06/2023: We release two pre-trained models of LVM-Med: ResNet-50 and ViT-B. Providing scripts for downstream tasks.
LVM-Med Pretrained Models
| Arch | Params (M) | 2D Segmentation (Dice) | 3D Segmentation (3D IoU) | Weights |
|---|---|---|---|---|
| ResNet-50 | 25.5M | 83.05 | 79.02 | backbone |
| ViT-B | 86.0M | 85.80 | 80.90 | backbone |
After downloading the pre-trained models, please place them in lvm_med_weights folder to use.
- For Resnet-50, we demo end-to-end segmentation/classification/object detection.
- For ViT-B, we demo prompt-based segmentation using bounding-boxes.
Important Note: please check dataset.md to avoid potential leaking testing data when using our model.
Segment Anything Model-related Experiments
- For all experiments using SAM model, we use the base architecture of SAM which is
sam_vit_b. You could browse theoriginal repofor this pre-trained weight and put it in./working_dir/sam_vit_b_01ec64.pthfolder to use yaml properly.
Further Training LVM-Med on Large Dataset
We release some further pre-trained weight on other large datasets as mentioned in the Table below.
| Arch | Params (M) | Dataset Name | Weights | Descriptions |
|---|---|---|---|---|
| ViT-B | 86.0M | LIVECell | backbone | Link |
| ViT-H | 632M | LIVECell | backbone | Link |
Prerequisites
The code requires python>=3.8, as well as pytorch>=1.7 and torchvision>=0.8. Please follow the instructions here to install both PyTorch and TorchVision dependencies. Installing both PyTorch and TorchVision with CUDA support is strongly recommended.
To set up our project, run the following command:
git clone https://huggingface.co/duynhm/LVM-Med
cd LVM-Med
conda env create -f lvm_med.yml
conda activate lvm_med
To fine-tune for Segmentation using ResNet-50, we utilize U-Net from segmentation-models-pytorch package. To install this library, you can do the following ones:
git clone https://github.com/qubvel/segmentation_models.pytorch.git
cd segmentation_models.pytorch
pip install -e
cd ..
mv segmentation_models_pytorch_example/encoders/__init__.py segmentation_models.pytorch/segmentation_models_pytorch/__init__.py
mv segmentation_models_pytorch_example/encoders/resnet.py segmentation_models.pytorch/segmentation_models_pytorch/resnet.py
Preparing datasets
For the Brain Tumor Dataset
You could download the Brain dataset via Kaggle's Brain Tumor Classification (MRI) and change the name into BRAIN.
For VinDr
You can download the dataset from this link VinDr and put the folder vinbigdata into the folder object_detection. To build the dataset, after downloading the dataset, you can run script convert_to_coco.py inside the folder object_detection.
python convert_to_coco.py # Note, please check links inside the code in lines 146 and 158 to build dataset correctly
More information can be found in object_detection.
Others
First you should download the respective dataset that you need to run to the dataset_demo folder. To get as close results as your work as possible, you could prepare some of our specific dataset (which are not pre-distributed) the same way as we do:
python prepare_dataset.py -ds [dataset_name]
such that: dataset_name is the name of dataset that you would like to prepare. After that, you should change paths to your loaded dataset on our pre-defined yaml file in dataloader/yaml_data.
Currently support for Kvasir, BUID, FGADR, MMWHS_MR_Heart and MMWHS_CT_Heart.
Note: You should change your dataset name into the correct format (i.e., Kvasir, BUID) as our current support dataset name. Or else it won't work as expected.
Downstream Tasks
Segmentation
1. End-to-End Segmentation
a) Training Phase:
Fine-tune for downstream tasks using ResNet-50
python train_segmentation.py -c ./dataloader/yaml_data/buid_endtoend_R50.yml
Changing name of dataset in .yml configs in ./dataloader/yaml_data/ for other experiments.
Note: to apply segmentation models (2D or 3D) using ResNet-50, we suggest normalizing gradient for stable training phases by set:
clip_value = 1
torch.nn.utils.clip_grad_norm_(net.parameters(), clip_value)
See examples in file /segmentation_2d/train_R50_seg_adam_optimizer_2d.py lines 129-130.
b) Inference:
ResNet-50 version
python train_segmentation.py -c ./dataloader/yaml_data/buid_endtoend_R50.yml -test
For the end-to-end version using SAM's ViT, we will soon release a better version than the reported results in the paper.
2. Prompt-based Segmentation with ViT-B
a. Prompt-based segmentation with fine-tuned decoder of SAM (MedSAM).
We run the MedSAM baseline to compare performance by:
Train
python3 medsam.py -c dataloader/yaml_data/buid_sam.yml
Inference
python3 medsam.py -c dataloader/yaml_data/buid_sam.yml -test
b. Prompt-based segmentation as MedSAM but using LVM-Med's Encoder.
The training script is similar as MedSAM case but specify the weight model by -lvm_encoder.
Train
python3 medsam.py -c dataloader/yaml_data/buid_lvm_med_sam.yml -lvm_encoder ./lvm_med_weights/lvmmed_vit.pth
Test
python3 medsam.py -c dataloader/yaml_data/buid_lvm_med_sam.yml -lvm_encoder ./lvm_med_weights/lvmmed_vit.pth -test
You could also check our example notebook Prompt_Demo.ipynb for results visualization using prompt-based MedSAM and prompt-based SAM with LVM-Med's encoder. The pre-trained weights for each SAM decoder model in the demo are here. Please download trained models of LVM-Med and MedSAM and put them into working_dir/checkpoints folder for running the aforementioned notebook file.
c. Zero-shot prompt-based segmentation with Segment Anything Model (SAM) for downstream tasks
The SAM model without any finetuning using bounding box-based prompts can be done by:
python3 zero_shot_segmentation.py -c dataloader/yaml_data/buid_sam.yml
Image Classification
We provide training and testing scripts using LVM-Med's ResNet-50 models for Brain Tumor Classification and Diabetic Retinopathy Grading in FGADR dataset (Table 5 in main paper and Table 12 in Appendix). The version with ViT models will be updated soon.
a. Training with FGADR
# Fully fine-tuned with 1 FCN
python train_classification.py -c ./dataloader/yaml_data/fgadr_endtoend_R50_non_frozen_1_fcn.yml
# Fully fine-tuned with multiple FCNs
python train_classification.py -c ./dataloader/yaml_data/fgadr_endtoend_R50_non_frozen_fcns.yml
# Freeze all and fine-tune 1-layer FCN only
python train_classification.py -c ./dataloader/yaml_data/fgadr_endtoend_R50_frozen_1_fcn.yml
# Freeze all and fine-tune multi-layer FCN only
python train_classification.py -c ./dataloader/yaml_data/fgadr_endtoend_R50_frozen_fcns.yml
To run for Brain dataset, choose other config files brain_xyz.ymlin folder ./dataloader/yaml_data/.
b. Inference with FGADR
# Fully fine-tuned with 1 FCN
python train_classification.py -c ./dataloader/yaml_data/fgadr_endtoend_R50_non_frozen_1_fcn.yml -test
# Fully fine-tuned with multiple FCNs
python train_classification.py -c ./dataloader/yaml_data/fgadr_endtoend_R50_non_frozen_fcns.yml -test
# Freeze all and fine-tune 1-layer FCN only
python train_classification.py -c ./dataloader/yaml_data/fgadr_endtoend_R50_frozen_1_fcn.yml -test
# Freeze all and fine-tune multi-layer FCN only
python train_classification.py -c ./dataloader/yaml_data/fgadr_endtoend_R50_frozen_fcns.yml -test
Object Detection
We demonstrate using LVM-Med ResNet-50 for object detection with Vin-Dr dataset. We use Faster-RCNN for the network backbone.
You can access object_detection folder for more details.
Citation
Please cite this paper if it helps your research:
@article{nguyen2023lvm,
title={LVM-Med: Learning Large-Scale Self-Supervised Vision Models for Medical Imaging via Second-order Graph Matching},
author={Nguyen, Duy MH and Nguyen, Hoang and Diep, Nghiem T and Pham, Tan N and Cao, Tri and Nguyen, Binh T and Swoboda, Paul and Ho, Nhat and Albarqouni, Shadi and Xie, Pengtao and others},
journal={arXiv preprint arXiv:2306.11925},
year={2023}
}
Related Work
We use and modify codes from SAM and MedSAM for prompt-based segmentation settings. A part of LVM-Med algorithm adopt data transformations from Vicregl, Deepcluster-v2. We also utilize vissl framework to train 2D self-supervised methods in our collected data. Thank the authors for their great work!
License
Licensed under the CC BY-NC-ND 2.0 (Attribution-NonCommercial-NoDerivs 2.0 Generic). The code is released for academic research use only. For commercial use, please contact Ho_Minh_Duy.Nguyen@dfki.de